Memory might seem intimidating at first, but remember that a computer isn't magical, and at the core it's really just a giant calculator. Memory is just bytes of temporary storage space that are numbered with addresses. This memory can be accessed by its addresses, and the byte at any particular address can be read from or written to. Current Intel x86 processors use a 32-bit addressing scheme, which means there are 232, or 4,294,967,296 possible addresses. A program's variables are just certain places in memory that are used to store information.
Pointers are a special type of variable used to store addresses of memory locations to reference other information. Because memory cannot actually be moved, the information in it must be copied. However, it can be computationally expensive to copy large chunks of memory around to be used by different functions or in different places. This is also expensive from a memory standpoint, because a new block of memory must be allocated for the copy destination before the source can be copied. Pointers are a solution to this problem. Instead of copying the large block of memory around, a pointer variable is assigned the address of that large memory block. Then this small 4-byte pointer can then be passed around to the various functions that need to access the large memory block.
The processor has its own special memory, which is relatively small. These portions of memory are called registers, and there are some special registers that are used to keep track of things as a program executes. One of the most notable is the extended instruction pointer (EIP). The EIP is a pointer that holds the address of the currently executing instruction. Other 32-bit registers that are used as pointers are the extended base pointer (EBP) and the extended stack pointer (ESP). All three of these registers are important to the execution of a program and will be explained in more depth later.
When programming in a high-level language, like C, variables are declared using a data type. These data types can range from integers to characters to custom user-defined structures. One reason this is necessary is to properly allocate space for each variable. An integer needs to have 4 bytes of space, while a character only needs a single byte. This means that an integer has 32 bits of space (4,294,967,296 possible values), while a character has only 8 bits of space (256 possible values).
In addition, variables can be declared in arrays. An array is just a list of N elements of a specific data type. So a 10-character array is simply 10 adjacent characters located in memory. An array is also referred to as a buffer, and a character array is also referred to as a string. Because copying large buffers around is very computationally expensive, pointers are often used to store the address of the beginning of the buffer. Pointers are declared by prepending an asterisk to the variable name. Here are some examples of variable declarations in C:
int integer_variable; char character_variable; char character_array[10]; char *buffer_pointer;
One important detail of memory on x86 processors is the byte order of 4-byte words. The ordering is known as little endian, meaning that the least significant byte is first. Ultimately, this means that the bytes are stored in memory in reverse for 4-byte words, such as integers and pointers. The hexadecimal value 0x12345678 stored in little endian would look like 0x78563412 in memory. Even though compilers for high-level languages such as C will account for the byte ordering automatically, this is an important detail to remember.
Sometimes a character array will have ten bytes allocated to it, but only four bytes will actually be used. If the word "test" is stored in a character array with ten bytes allocated for it, there will be extra bytes at the end that aren't needed. A zero, or null byte, delimiter is used to terminate the string and tell any function that is dealing with the string to stop operations there.
0 1 2 3 4 5 6 7 8 9 t e s t 0 X X X X X
So a function that copies the above string from this character buffer to a different location would only copy "test", stopping at the null byte, instead of copying the entire buffer. Similarly, a function that prints the contents of a character buffer would only print the word "test", instead of printing out "test" followed by several random bytes of data that might be found afterward. Terminating strings with null bytes increases efficiency and allows display functions to work more naturally.
Program memory is divided into five segments: text, data, bss, heap, and stack. Each segment represents a special portion of memory that is set aside for a certain purpose.
The text segment is also sometimes called the code segment. This is where the assembled machine language instructions of the program are located. The execution of instructions in this segment is non-linear, thanks to the aforementioned high-level control structures and functions, which compile into branch, jump, and call instructions in assembly language. As a program executes, the EIP is set to the first instruction in the text segment. The processor then follows an execution loop that does the following:
Read the instruction that EIP is pointing to.
Add the byte-length of the instruction to EIP.
Execute the instruction that was read in step 1.
Go to step 1.
Sometimes the instruction will be a jump or a call instruction, which changes the EIP to a different address of memory. The processor doesn't care about the change, because it's expecting the execution to be non-linear anyway. So if the EIP is changed in step 3, the processor will just go back to step 1 and read the instruction found at the address of whatever the EIP was changed to.
Write permission is disabled in the text segment, as it is not used to store variables, only code. This prevents people from actually modifying the program code, and any attempt to write to this segment of memory will cause the program to alert the user that something bad happened and kill the program. Another advantage of this segment being read-only is that it can be shared between different copies of the program, allowing multiple executions of the program at the same time without any problems. It should also be noted that this memory segment has a fixed size, because nothing ever changes in it.
The data and bss segments are used to store global and static program variables. The data segment is filled with the initialized global variables, strings, and other constants that are used through the program. The bss segment is filled with the uninitialized counterparts. Although these segments are writable, they also have a fixed size.
The heap segment is used for the rest of the program variables. One notable point about the heap segment is that it isn't of fixed size, meaning it can grow larger or smaller as needed. All of the memory within the heap is managed by allocator and deallocator algorithms, which respectively reserve a region of memory in the heap for use and remove reservations to allow that portion of memory to be reused for later reservations. The heap will grow and shrink depending on how much memory is reserved for use. The growth of the heap moves downward toward higher memory addresses.
The stack segment also has variable size and is used as a temporary scratchpad to store context during function calls. When a program calls a function, that function will have its own set of passed variables, and the function's code will be at a different memory location in the text (or code) segment. Because the context and the EIP must change when a function is called, the stack is used to remember all of the passed variables and where the EIP should return to after the function is finished.
In general computer science terms, a stack is an abstract data structure that is used frequently. It has first-in, last-out (FILO) ordering, which means the first item that is put into a stack is the last item to come out of it. Like putting beads on a piece of string that has a giant knot on the end, you can't get the first bead off until you have removed all the other beads. When an item is placed into a stack, it's known as pushing, and when an item is removed from a stack, it's called popping.
As the name implies, the stack segment of memory is, in fact, a stack data structure. The ESP register is used to keep track of the address of the end of the stack, which is constantly changing as items are pushed into and popped from it. Because this is very dynamic behavior, it makes sense that the stack is also not of a fixed size. Opposite to the growth of the heap, as the stack changes in size, it grows upward toward lower memory addresses.
The FILO nature of a stack might seem odd, but because the stack is used to store context, it's very useful. When a function is called, several things are pushed to the stack together in a structure called a stack frame. The EBP register (sometimes called the frame pointer (FP) or local base pointer (LB)) is used to reference variables in the current stack frame. Each stack frame contains the parameters to the function, its local variables, and two pointers that are necessary to put things back the way they were: the saved frame pointer (SFP) and the return address. The stack frame pointer is used to restore EBP to its previous value, and the return address is used to restore EIP to the next instruction found after the function call.
Here's an example test function and main function:
void test_function(int a, int b, int c, int d)
{
char flag;
char buffer[10];
}
void main()
{
test_function(1, 2, 3, 4);
}
This small code segment first declares a test function that has four arguments, which are all declared as integers: a, b, c, and d. The local variables for the function include a single character called flag and a 10-character buffer called buffer. The main function is executed when the program is run, and it simply calls the test function.
When the test function is called from the main function, the various values are pushed to the stack to create the stack frame as follows. When test_function() is called, the function arguments are pushed onto the stack in reverse order (because it's FILO). The arguments for the function are 1, 2, 3, and 4, so the subsequent push instructions push 4, 3, 2, and finally 1 onto the stack. These values correspond to the variables d, c, b, and a in the function.
When the assembly "call" instruction is executed, to change the execution context to test_function(), the return address is pushed onto the stack. This value will be the location of the instruction following the current EIP — specifically the value stored during step 3 of the previously mentioned execution loop. The storage of the return address is followed by what is called the procedure prolog occurs. In this step, the current value of EBP is pushed to the stack. This value is called the saved frame pointer (SFP) and is later used to restore EBP back to its original state. The current value of ESP is then copied into EBP to set the new frame pointer. Finally, memory is allocated on the stack for the local variables of the function (flag and buffer) by subtracting from ESP. The memory allocated for these local variables isn't pushed to the stack, so the variables are in expected order. In the end, the stack frame looks something like this:
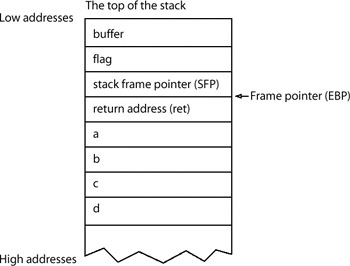
This is the stack frame. Local variables are referenced by subtracting from the frame pointer EBP, and the function arguments are referenced by adding to it.
When a function is called, the EIP is changed to the address of the beginning of the function in the text (or code) segment of memory to execute it. Memory in the stack is used for the function's local variables and the function arguments. After the execution finishes, the entire stack frame is popped off the stack, and the EIP is set to the return address so the program can continue execution. If another function were called within the function, another stack frame would be pushed onto the stack, and so on. As each function ends, its stack frame is popped off the stack so execution can be returned to the previous function. This behavior is why this segment of memory is organized in a FILO data structure.
The various segments of memory are arranged in the order they were presented, from the lower memory addresses to the higher memory addresses. Because most people are familiar with seeing lists that count downward, the smaller memory addresses are shown at the top.
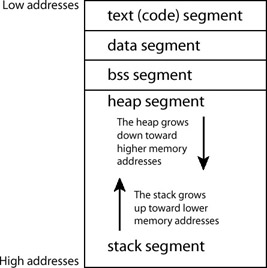
Because the heap and the stack are both dynamic, they both grow in different directions toward each other. This minimizes wasted space and the possibility of either segments growing into each other.