- Felkészülés a hibakeresésre
- A töréspontok, és lehetőségeik
- A try-catch szerkezet
- Optimalizálás
- A program közzététele
1, Felkészülés a hibakeresésre
A szintaktikai hibák megtalálása feltehetően senkinek nem okoz gondot mire eddig eljut, vagyis hogy megtaláljon egy elhagyott zárójelet, pontosvesszőt, elgépelést, stb. A fejezet ezért az elvi hibákkal fog foglalkozni, amik szintaktikailag helyesek - de a programot mégis összeomlasztják futás közben.
Mind a sebtében összehajintott programokban, mind az előre megfontoltan elkészített óriási projektekben lehetnek elvi hibák, és ezek feltárása sok esetben komolyabb szellemi munka, mint maga a program megírása - hiszen végig kell gondolni a gép fejével hogy mit csinál ekkor és ekkor.
Ez a fejezet ezzel fog foglalkozni - az egyszerűség kedvéért pedig Code::Blocks (CB) alól.
Ahhoz hogy hibát tudjunk keresni, használhatjuk a parancssori GDB-t, vagy használhatjuk az IDE-t. Mivel a CB a GDB-t használja, meg kell neki adni a helyét (ahol saját fordító, stb. van [pl. Borland C++] ott erre nincs szükség).
1a, A CB felkészítése a hibakeresésre
Természetesen a GDB felkutatásához ismernünk kell annak a helyét:
- ha hivatalos csomagot szedtünk le, és külön tettük fel a MinGW-t akkor ott találjuk, ahova feltettük azt
- ha az egyszerűsített csomagot (amit csak ki kell bontani) szedtük le, akkor a program mappájában lesz
Bárhol is van a .\bin\gdb.exe elérési úton találjuk. Nálam ez most:
D:\Programok\Programozas\CodeBlocks-EP\MinGW\bin\gdb.exe
Ha megtaláltuk a fájlt, akkor tallózzuk be az "Executable path: " című részhez, ebben az ablakban:
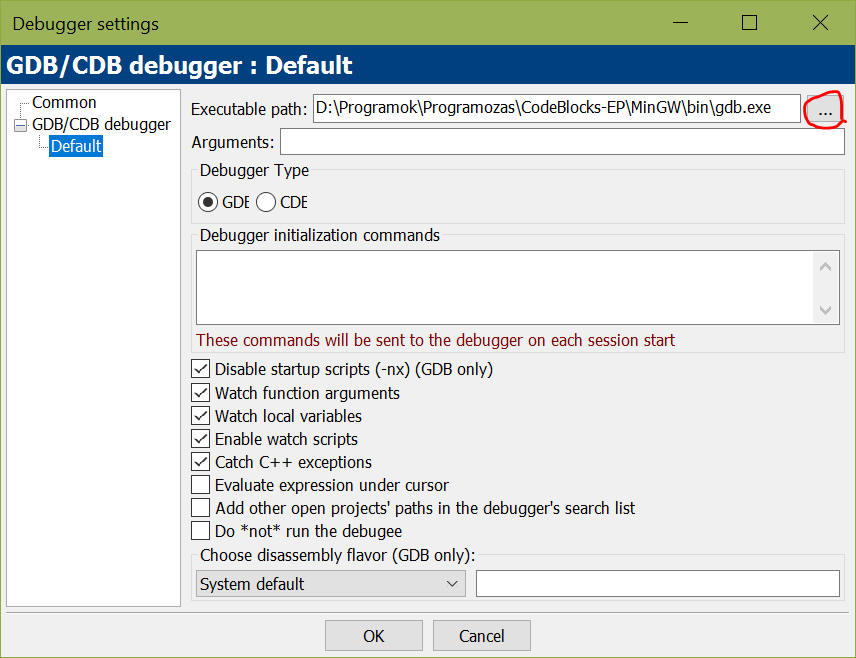
Ez az ablak a Settings > Debugger... menüpontban érhető el.
Ha ezzel végeztünk, az IDE már kész a hibakeresésre - de mi még nem.
1b, Az első projekt létrehozása
Ahhoz hogy hibát kereshessünk ezentúl projektben kell dolgozni, akkor is ha csak egy fájlból áll a program.
Ehhez első lépésként nyissuk meg az alábbi menüpontot:
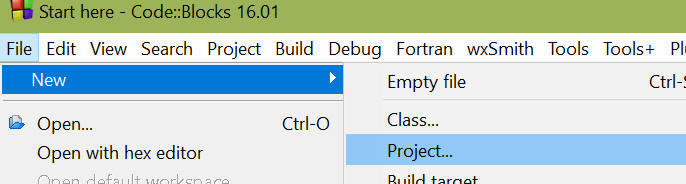
A következő lépésben kapunk egy ilyen ablakot:
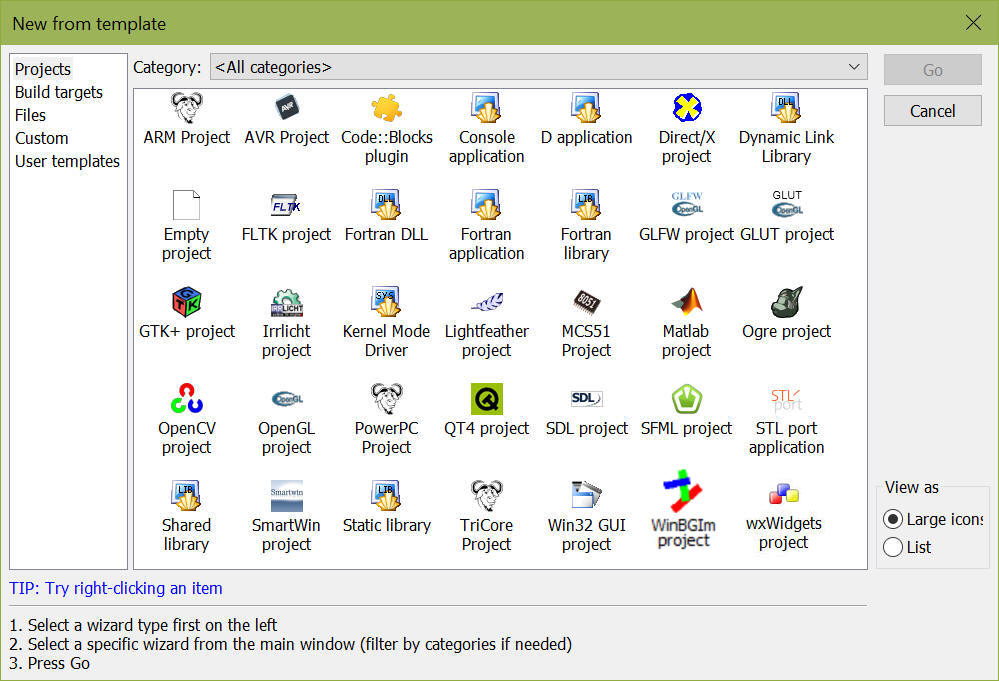
Ezen ablakból ami számunkra érdekes lehet azok az alábbiak:
- Console Application: szöveges módú Windows alapú alkalmazás (.EXE)
- Dynamic Link Library: dinamikus csatolású függvénytár (.DLL)
- Win32 GUI project: grafikus módú (ablakos) Windows alapú alkalmazás (.EXE)
- WinBGIm project: a Borland C++ grafikus képességeivel bíró, szöveges módú Windows alapú alkalmazás (.EXE)
Most egyelőre maradjunk a Console application típusú projektnél.
Ezek után meg fogja kérdezni hogy melyik programnyelven szeretnénk dolgozni, én egyelőre a C++ nyelvet választom ki, de típusszigorú C kódot fogok írni (ami megtehető).
Ez után a projekt nevét, és elhelyezkedését kell megadni. Érdemes a fájlnévben kerülni a szóközt és az ékezetet, mivel a GDB bizonyos esetekben nem működik jól, ha ilyenek vannak.
A projekt neve lesz különben a kész fájl neve is (na nem mintha nem lehetne átnevezni).
Több fordító esetén itt kiválaszthatnánk hogy mivel szeretnénk a programot fordítani, szerintem itt ez egyértelmű:
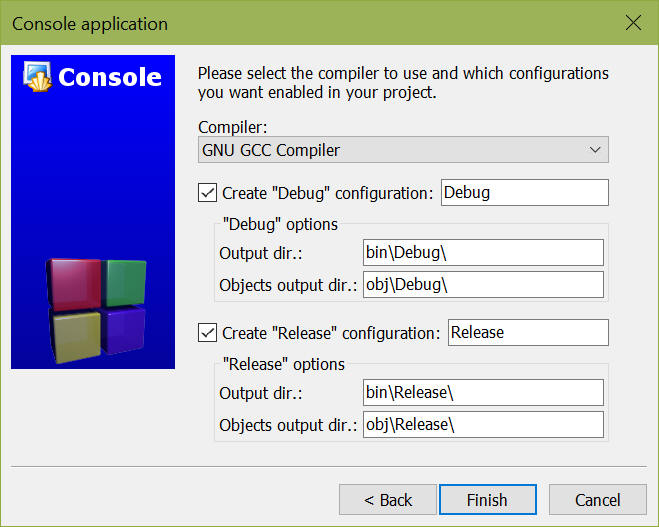
Itt fontos hogy legyen mind a Debug ("hibakeresési"), mind a Release ("kiadási") konfiguráció kipipálva - mindkettőre szükség lesz.
A Finish gombra kattintva oldalt megjelent a projektünk, benne egy alap progival:
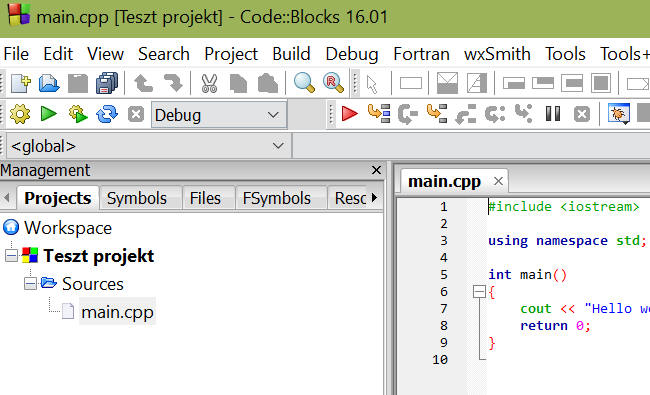
Most két út áll előttünk - ha meglévő fájlokat (pl. korábban megírt .C + .H fájlokat) akarunk hozzáadni a projekthez akkor a projektre kattintsunk jobb gombbal, és válasszuk az "Add files..." menüpontot.
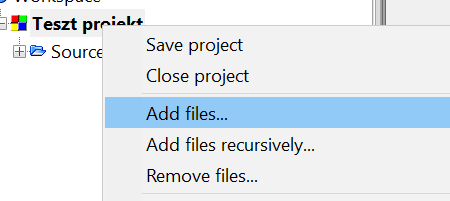
Amennyiben a programhoz új fájlt akarunk adni, akkor a megszokott módon kell megtenni:
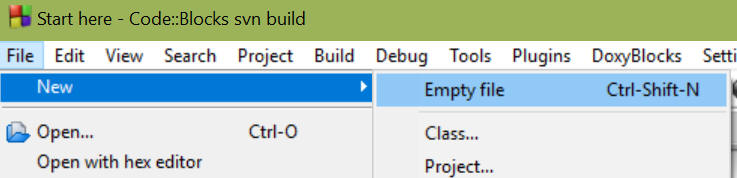
Ezúttal a CB feltesz majd egy kérdést - hozzáadjuk az új fájlt a projekthez?
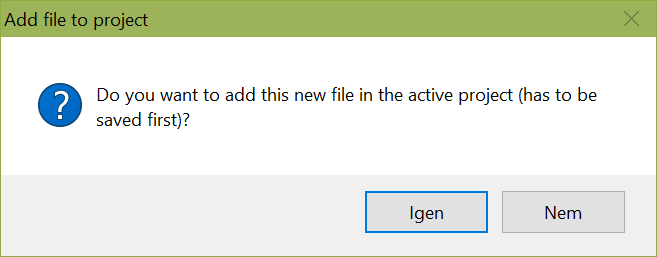
Természetesen igen. A mentésnél a projekt mappájába mentsük .C (vagy .CPP) kiterjesztéssel.
1c, A projekt fordítása és futtatása
A projekt fordítása továbbra történhet az F9 ( )
segítségével, de ha ezt választjuk lényegében semmi plusz nem fog történni.
)
segítségével, de ha ezt választjuk lényegében semmi plusz nem fog történni.
Azért csináltuk végig ezt a sok mindent, hogy a futtatás történhessen más
módon is - először csak fordítunk (Ctrl+F9,  ),
majd futtatunk hibakereséssel (F8,
),
majd futtatunk hibakereséssel (F8,  ).
).
A hibakeresésnek ugyanakkor lesz egy plusz összetevője - a kész .EXE fájlban el kell helyezni hibakeresési információkat. Ilyen hibakeresési információ lesz pl. hogy az adott utasítás (.EXE fájlban), a programkód (.C) melyik sorához tartozik.
A hibakeresési információk kétélűek, ha benne felejtjük a programban, az sebezhető lesz és visszafejthető - ugyanakkor számunkra nélkülözhetetlenek a hibakereséshez.
Ezért van kétféle konfigurációnk a fordításhoz:
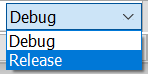
Ha a Debug változatot használjuk, tudunk hibát keresni - belefordulnak ezek az információk a .EXE fájlba.
Ha a Release változatot használjuk, a program kisebb lesz mivel a hibakeresési információkat nem fogja tartalmazni - így viszont nem lehet hibát keresni.
Mivel a Release módot kb. csak a feltöltés előtt szoktuk használni, általában Debug módban dolgozunk.
2, A töréspontok, és lehetőségeik
Tegyük fel hogy az alábbi programban nem tudjuk, hol fog összeomlani - és szeretnénk megtudni ezt.
| #include
<stdio.h> int main() { int i = 1, j = 0; printf("A hanyados: %d", i / j); return 0; } |
Erre vannak a töréspontok bevezetve - használatukhoz egészen egyszerűen annyit kell tennünk hogy az adott sor száma elé kattintunk, úgy hogy ott megjelenjen egy piros pötty:
A fordítás (Ctrl+F9), és futtatás (F8) során a program meg fog állni minden egyes sor lefuttatása előtt:
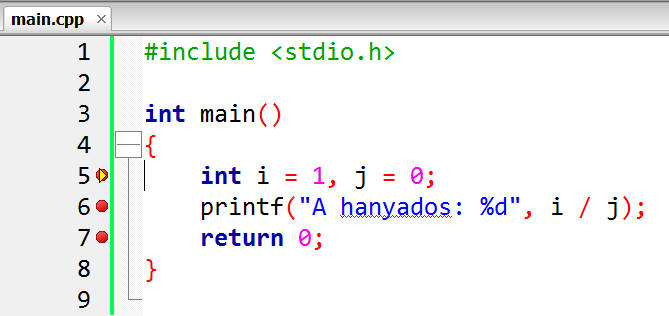
Jól látható hogy az 5. sorig eljutunk, tehát eddig nincs hiba - ha most összeomlik a következő sorban, akkor az 5. sor volt a ludas. Az F8 hatására folytatódik a program.
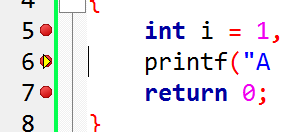
De nem teszi meg, simán eljut a 6. sorig, tehát gyanítható hogy addig helyes a program. Az F8 ismételt megnyomása hatására a program kivételt dob fel, és a CB megváltozik:
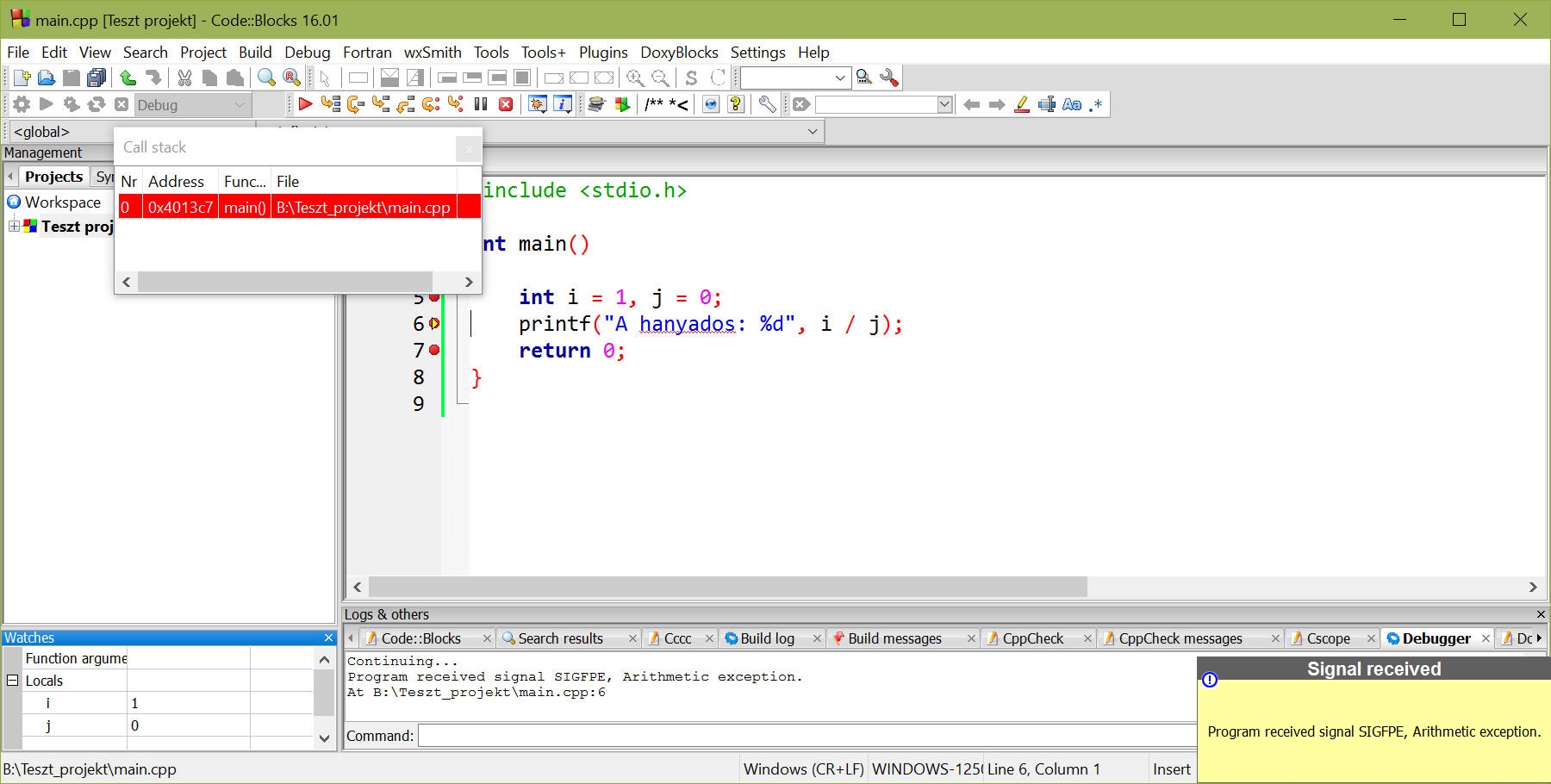
Első lépésben értesít minket egy hibáról, másrészt felugrik egy "Call Stack" nevű (hívási verem) ablak, ami megadja hogy melyik függvényben, melyik címen történt kivétel (ha a projekt sima C-hez lenne nem lenne ilyen sok adatunk a hibáról).
Arról is információt kapunk a jobb alsó sarokban, hogy számítási hiba történt (arithmetic exception = aritmetikai kivétel).
Az F8 ismételt lenyomására a program befejezi futását megint:
De ez most nem probléma mert rengeteg információval lettünk gazdagabbak:
- Számítási hiba van a 6. sorban.
- Mivel a printf amúgy normálisan szokott működni, feltehetően az osztással lesz gebasz.
- Mivel az osztással sem szokott gond lenni, feltehetően a két oldalán lévő értékekkel lesz gond.
- Ha megnézzük hogy mit osztunk el mivel, akkor azt láthatjuk hogy a második tag nulla (j = 0) - így a program a nullával való osztás miatt hasal el.
Megoldás: pl. j = 1 hatására a progi hibátlanul fog futni.
A példa azért is érdekes mert a hiba nem azért volt, mert a 6. sorban rossz dolgot adtunk meg, hanem azért mert a korábban megállapított adatokkal (5. sor) ez a művelet nem végezhető el.
2a, A változók megfigyelése (watches)
A fenti példa nagyon gagyi, hiszen előre tudjuk hogy mivel fogunk osztani.
Mi van olyankor, ha valamilyen bonyolult számítás útján, netán algoritmussal jutunk el a fenti értékekre?
Ilyenkor jó lenne nyomon követni a változók értékét, és egy két jó helyre kitett törésponttal ez meg is valósítható.
Megint kiemelném, hogy a töréspont az adott sor lefutása előtti állapotot térképezi fel, vagyis ha egy változó megváltozott értékére vagyunk kíváncsiak, akkor a számítás utáni sorba kell tenni a töréspontot.

Jelen programban valami számítás által kapjuk meg a két értéket, és mivel a számolt értékek érdekelnek minket a printf sorára tesszük a töréspontot.
Az F8 lenyomására megáll a printf-nél a program, de semmi információnk nincs a változókról. Ahhoz hogy erről adatokat kapjunk, jelenítsük meg a Watches ablakot:
És ezek után már is megkapjuk az i, és j számolt értékét:
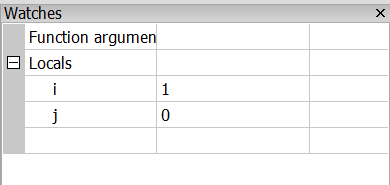
Megjegyzés: Az algoritmus "egészen véletlenül", szándékosan ugyanazokat a számokat adja ki mint a fenti példában.
Mi van akkor ha a töréspont a szamol utasítás egyetlen sorába kerül?
Ilyenkor kiírja a két paramétert, de a visszatérési értéket nem:
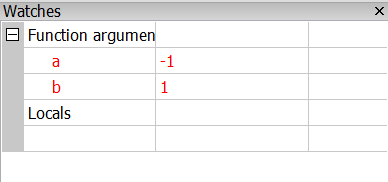
Ilyenkor be szoktunk vezetni ún. hibakeresési segédváltozókat:
| #include
<stdio.h> #include <math.h> int szamol(int a, int b) { int _h_RetVal = b > 0 ? (int)sqrt(fabs(pow(a, -1))) : (int)sqrt(fabs(pow(a, 0) - 1)); return _h_RetVal; } int main() { int i = szamol(-1, 1), j = szamol(-1, -1); printf("A hanyados: %d", i / j); return 0; } |
Ezek a változók nem változtatnak a kódon, de lehetővé teszik a kiolvasását egy olyan értéknek, amit amúgy nem tudunk kiolvasni. Ezeket optimalizálás során érdemes eltávolítani, ezért célszerű megkülönböztetni őket (pl. "_h_" jellel kezdeni).

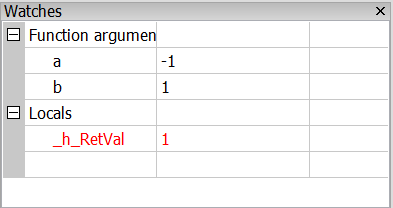
Mivel a szamol utasítást meghívjuk, ezek a töréspont kétszer is le fog futni:
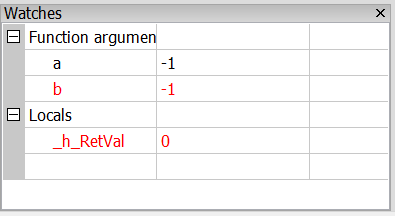
Összességében tehát így használható a Watches ablak. Azért azt érdemes tudni hogy mindenre ez sem képes:
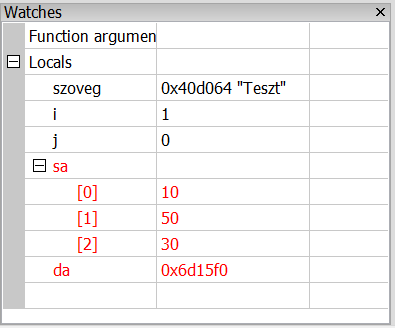
A szoveg egy char* típusú változó, ezzel még elboldogul, az i, j ugye int így egyértelmű, az sa egy statikus tömb - ezzel is egész jól boldogul, viszont a da egy dinamikus tömb - ezzel már nem, csak a memóriacímét kapjuk meg.
2b, A hívási verem (call stack)
Habár már szó esett róla mikor felugrott a hibánál, érdemes egy kicsit megnézni ezt is.
Először is, arról hogy mi az a verem programozási szempontból:

Ez egy üres verem - de mi van ha teszünk bele elemeket?
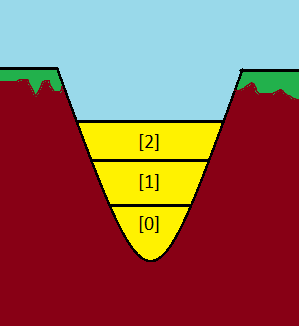
Ezeket képzeljük el mint fóliával elválasztott homokrétegeket. Evidens hogy a mélyebben lévőket csak akkor tudjuk kivenni ha a felette lévőket kivettük - ez a verem lényege, ez egy LILO adatszerkezet (last-in, last-out).
A programozás során a gép a meghívott függvényekben hogy hol járt, egy ugyanilyen veremben tárolja - elindul egy fv. - elindít egy alfüggvényt - ha lefutott kiveszi a veremből - folytatja ahol abbahagyta az fv.-t. Ez a hívási verem.
A hívási verem tehát szépen meg fogja nekünk mutatni hogy melyik függvény, melyiket, milyen paraméterekkel hívta meg.
A fenti példára értelmezve, a szamol függvényben lévő töréspontra:
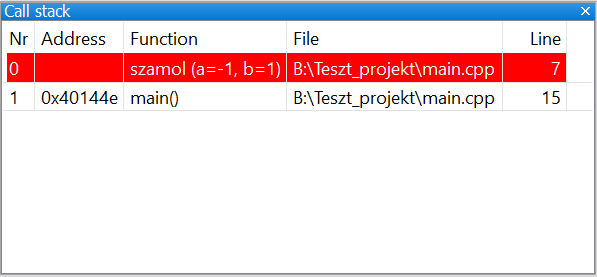
A hívási veremből jól látható hogy a main(), a teljes kód 15. sorában meghívja a szamol(-1, 1) utasítást. Ha esetleg a paraméterekben kifejezés van, itt már a kiértékelt kifejezést láthatjuk.
Összetett programokban a hívási verem nagyon sokat segíthet, hiszen mint ezt láthattuk a kivétel nem mindig a helytelen adatoknál keletkezik, és ilyenkor ezáltal visszakövethető a helytelen adatok útja.
Korábban már foglalkoztunk a rekurzióval, és szó esett arról a faktorialis() függvény kapcsán, hogy miként néz ki a hívási verme. Nézzük ezt meg valójában (lásd a függvényt):
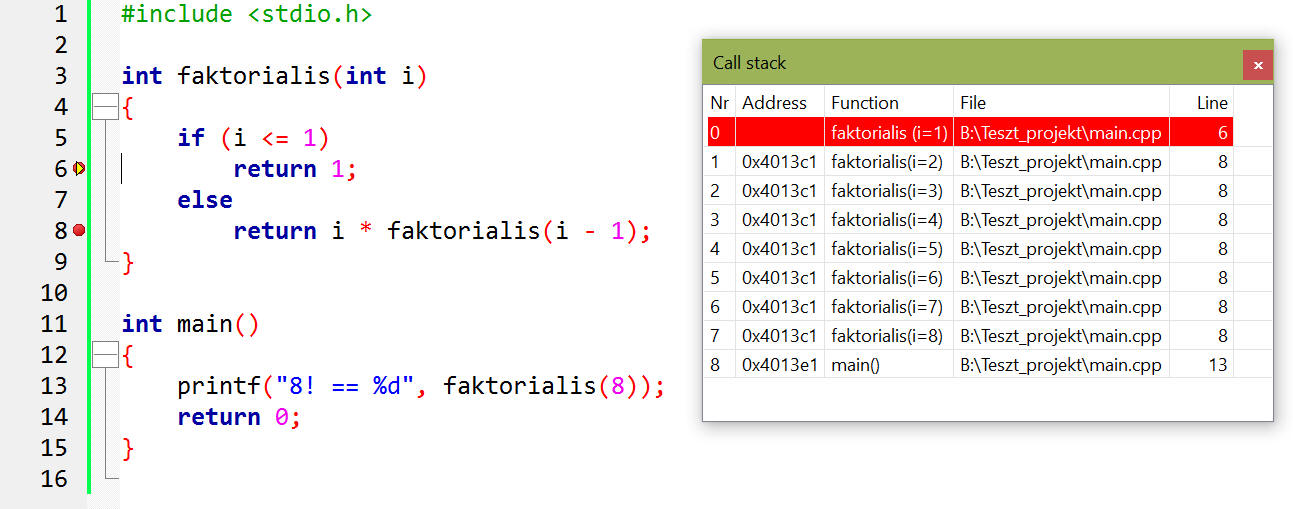
Így egyértelműen jól követhető, hogy mindig kiszámolja az eggyel kisebb faktoriálist, és azt szorozza meg azzal a számmal ahanyadik éppen kell - de a kisebb szám esetén is ezt csinálja - egészen amíg 1-et el nem érjük, mert akkor 1! == 1.
2c, További hibakeresési ablakok
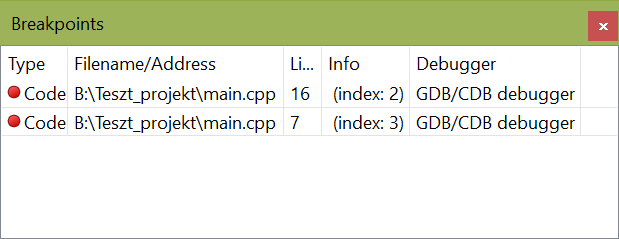
Ha sok fájlunk van a Breakpoints ablak kiírja az adott fájlokban lévő töréspontok helyét.
Ha egy egyszerű dinamikus szerkezeten lévő adatokat szeretnénk megtekinteni akkor használható a Memory dump ablak.
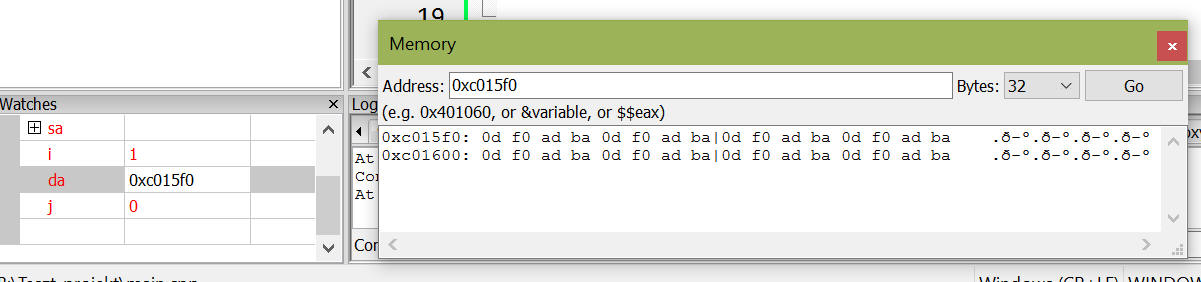
A hátránya hogy az adatokat mint karakterek, illetve mint byteok halmaza tizenhatos számrendszerben kapjuk meg - ami relatíve nehezen értelmezhető.
Ha a program lefordított gépi kódja érdekelne minket, akkor az is elérhető Assembly nyelven a Disassembly ablakban.
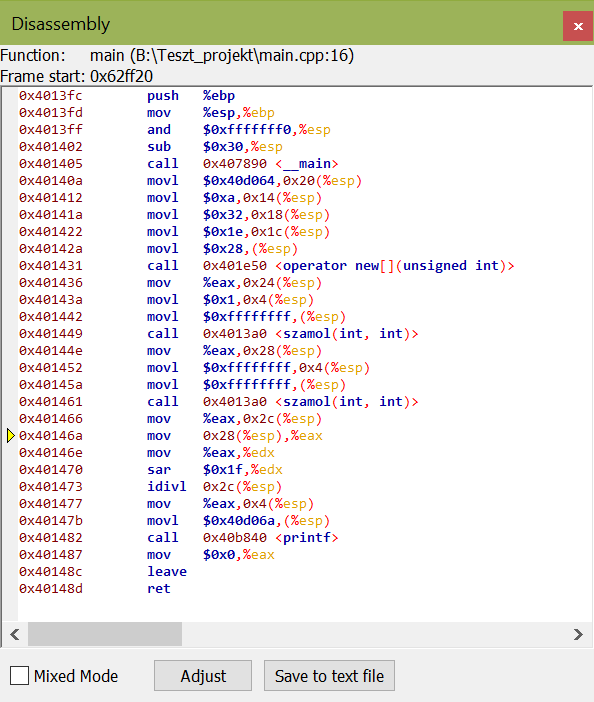
Természetesen ha már ennyire érdekel minket hogy a processzor mit csinál, belepillanthatunk a regiszterekbe is a CPU Registers ablak által:
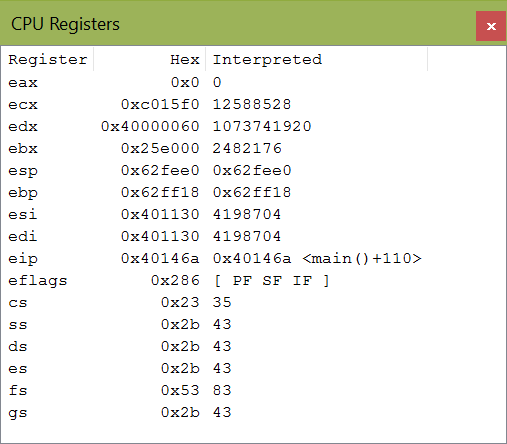
Ezek mind-mind természetesen töréspontokra értelmezettek.
3, A try-catch szerkezet
Mint erről már szó esett a hibákat el is kell hárítani, aminek eddig az első két megoldásával ismerkedtünk meg:
- a program leakasztása, hibakemeneti üzenettel + hibakóddal (lásd itt)
- a hibák elkerülése, menet közbeni ellenőrzésekkel, és feltételes műveletvégzéssel (lásd itt)
- kivételkezelés: a hibák észlelése, jelzése - de közben figyelmen kívül hagyása/vészleakasztás
Ehhez a try-catch szerkezet lesz a segítségünkre, amivel a program elején bemutatott kivételeket lehet elkapni, és kezelni.
| try { // kritikus sorok // ha valami nem jó akkor: throw <hibakod>; } catch (<típus> hibakod) { // mit csináljon a hibakóddal a program } // a program futása folytatódni fog, nem áll meg mint eddig... |
Fontos: Ez a szerkezet csak C++ alatt érhető el - amiért a projektet is ilyennek választottuk. A try-catch kivételeket kezel, de kivételek csak C++ alatt lesznek. (kesőbb leírom miként lehet C alatt is ilyen szerkezetet használni).
Ahhoz hogy a try-catch szerkezetet megvalósíthassuk, egyszerre kell az első két pont megoldását használni - figyelni kell a hibát, és visszajelezni ha baj van.
Ez az egyszerű példa magyarázatot adhat a dolgokra:
| #include
<stdio.h> int main() { int i = 1, j = 0; try { if (j == 0) throw 1; printf("A hanyados: %d", i / j); } catch(int hibakod) { fprintf(stderr, "A program futasa soran hiba tortent. Hibakod: %d.", hibakod); } return 0; } |
A throw szerepe hasonló a returnéhoz, de csak az adott try blokkot fogja megszakítani, és egyből ugrani fog a catch blokkra. Azt hogy a thrownak milyen típusú adatot kell visszadania, a catchben megadott típus dönti el, a példában ez most int.
Ha több try-catch blokkot ágyazunk egybe, akkor van lehetőségünk arra - hogy a belsőben történő kivételt kiirányítsuk a külsőbe.
| try { try { //nagyon kritikus szakasz } catch (<típus> hibakod) { throw; //kiküldés a külső szintre } catch (<típus> hibakod) { printf("Hiba tortent."); //a belső, és külső hibákat is itt kezeljük } |
3a, A kivétel objektumok
A kivétélek érkezhetnek objektumként is (std::exception típus), ekkor a what() utasítás fogja megadni a hibaüzenetet. Egy ilyen objektum elkészítését jelenleg nem firtatnám, amíg nem esik szó arról, hogy hogyan készíthetünk objektumokat.
| try { } catch (exception& kivetel) { fprintf(stderr, "%s", kivetel.what()); } |
Sok esetben külön ellenőrzés nélkül kapunk ilyen kivétel objektumokat, pl.:
| név | oka |
| bad_alloc | ha a new[] utasításnak nem sikerül a foglalás |
| bad_cast | ha a típuskonverzió helytelen |
| bad_exception | általános hibák esetére |
| bad_typeid | típusazonosítókkal kapcsolatos hiba |
| bad_function_call | függvények hívása során fellépő hiba |
| bad_weak_ptr | az ún."weak_ptr" objektummal kapcsolatos hiba |
| logic_error | belső logikai hiba esetére |
| runtime_error | bármely futásidejű hiba esetére |
Maga a kivétel objektum, és ezek a standard kivételek az <exception> fájl beszerkesztését igénylik. Példa:
| #include
<stdio.h> #include <exception> int main() { try { int* nagy_tomb = new int[0xFFFFFFFF]; } catch(exception& kivetel) { fprintf(stderr, "A program futasa soran kivetel tortent: %s", kivetel.what()); } return 0; } |
Attól nem kell félni, hogy ez a program véletlenül sikeresen lefoglalja a tömböt - a tömb mérete ~16GB lenne, 32 bites fordítóval pedig az előállított program legfeljebb ~2GB memóriát tud összesen lefoglalni.
A futás eredménye:
A program futasa soran kivetel tortent: std::bad_alloc
Process returned 0 (0x0) execution time : 0.000 s
Press any key to continue.
3b, A kivételek C alatt
Mint ígértem a C alatt is megmutatom, miként kivitelezhetőek ezek a try-catch szerkezetek. Beépítve nincsenek a nyelvbe, de ezen makrókkal pótolhatóak (forrás itt):
| #include
#define TRY do{ jmp_buf ex_buf__; switch( setjmp(ex_buf__) ){ case 0: #define CATCH(x) break; case x: #define ETRY } }while(0) #define THROW(x) longjmp(ex_buf__, x) |
Ezeket csak be kell másolni, és már is összeüthető egy egyszerű példa:
| #include
<stdio.h> #include #define TRY do { jmp_buf ex_buf__; switch( setjmp(ex_buf__) ) { case 0: while(1) { #define CATCH(x) break; case x: #define ETRY break; } } }while(0) #define THROW(x) longjmp(ex_buf__, x) int main() { int i = 1, j = 0; TRY { if (j == 0) THROW(1); printf("A hanyados: %d", i / j); } CATCH(int hibakod) { fprintf(stderr, "A program futasa soran hiba tortent. Hibakod: %d.", hibakod); } ETRY return 0; } |
Mivel a C alapból nem ismeri az objektumokat, a kivételobjektumokat is elfelejthetjük, de definiálhatunk hasonlóakat:
| #define DIVIDE_EXCEPTION (1) ... THROW(DIVIDE_EXCEPTION); |
4, Optimalizálás
Ha már a programunk minden hibának ellenáll, és képtelenség összeomlasztani akkor megkezdődhet az optimalizálás.
Az optimalizálás során fontos eldönteni, hogy a program célplatformja mi lesz. Ha szervergépre írjuk a programot, akkor minél kevesebb számítást kell végezni, inkább sok változó árán, míg hogyha otthoni számítógépre írjuk, akkor a korlátos memória miatt a változók száma épelméjű keret közé kell szoruljon.
4a, A változók, hibakeresési adatok optimalizálása
Néhány dolgot ennek ellenére meg lehet ejteni platformtól függetlenül:
- A fölösleges segédváltozók eltávolítása (pl. hibakeresési segédváltozók)
- A felesleges kommentek kiszedése az átláthatóság javításáért
- A hibakeresést segítő kódrészletek eltávolítása
- A program fordítása Release módban
4b, A függvényhasználat optimalizálása
Szintén minden esetben használható optimalizálást végezhetünk a függvények esetén.
Bármikor, ha meghívunk egy függvényt, az lefut - következésképpen, a visszatérési értékére ha többször is szükség van, akkor azt mindenféleképpen tároljuk el a memóriában.
pl.:
|
#include <stdio.h> #include <new> #include <math.h> int* szamol(int a, int b) { int* tomb = new int[100000], i; tomb[0] = 0; for (i = 1; i < 100000; i++) tomb[i] = lround(sqrt((fabs(pow(a, i)) - 1) / (fabs(pow(b, i)) + 1))) + tomb[i - 1]; return tomb; } |
Legyen ez a függvény, ami előállít egy 100 000 számból álló számsort. Ezen számsornak szeretnénk megtudni a 2048., és 4096. elemének az összegét, ha a=3, b=2.
|
int main() { printf("%d", szamol(3, 2)[2047] + szamol(3, 2)[4095]); return 0; } |
Ebben a kódban remekül megjelenik a fentebb leírt hiba:
- A szamol(3, 2) lefut és kiszámolja mind a 100 000 elemet.
- Eredményül ad egy dinamikus tömböt, amiből mi kiveszünk egy elemet, de b*sszuk felszabadítani
- A szamol(3, 2) lefut és megint kiszámolja mind a 100 000 elemet
- Eredményül ad egy dinamikus tömböt, amiből mi kiveszünk egy elemet, de b*sszuk felszabadítani
- A két kivett elemet összeadjuk, és kiírjuk
A felszabadítások hiánya miatt a program alapból vérzik, de tetézzük ezt azzal hogy duplán kiszámoltatjuk a géppel (feleslegesen) ugyanazt. Íme egy javított megoldás:
|
int main() { int* adatok = szamol(3, 2); printf("%d", adatok[2047] + adatok[4095]); delete [] adatok; return 0; } |
A javított változat, egy tömböt használ végig, és azt fel is szabadítja - ráadásul mindössze két sorral hosszabb.
A futásideje az elsőnek 301ms, míg a másodiknak 153ms. Ha belegondolunk hogy mondjuk egy játéknak ez az összefüggés egy apró kis elemét számítja, nagyon nem mindegy hogy fele, vagy dupla annyi ideig tart a segédszámítás, hiszen 1000x lefuttatva már percekről beszélünk.
4c, A pufferelés (gyorsítótárazás)
Az előző példában lényegében egy puffert csináltunk a main függvényben adatok néven. A puffer/gyorsítótár egy olyan memóriaterület, amire ideiglenesen, a számítást lényegesen meggyorsító adatok kerülnek.
Képzeljük el, hogy szeretnénk leábrázolni egy matematikai függvényt, pl. y=f(x)=x*x
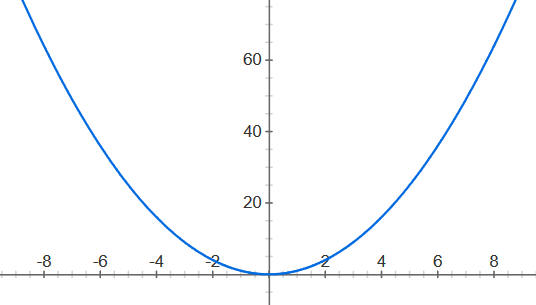
Ennek a legegyszerűbb módja számítógéppel, hogy behelyettesítünk bizonyos x értékekre, és megkapjuk az y magasságot. Ezeket a P(x,y) pontpárokat összekötve kapunk egy ábrát.
pl.:
| x | -4 | -3 | -2 | -1 | 0 | 1 | 2 | 3 | 4 |
| y | 16 | 9 | 4 | 1 | 0 | 1 | 4 | 9 | 16 |
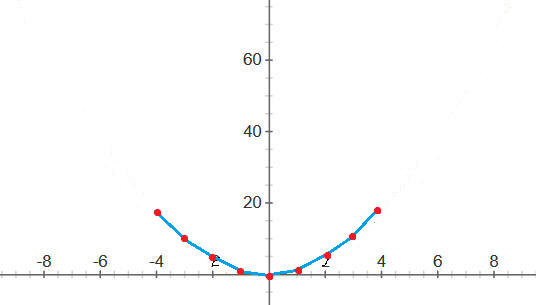
Azért az észrevehető, hogy az összekötő vonalak egyenesek, és nem ívek mint fenn - ezért egyrészt pontosabb vizsgálat kéne, másrészt nagyobb tartomány.
A másik dolog, hogy a kirajzolásról azt érdemes tudni, hogy a Borland C++ grafikáján kívül, rendesen ez egy ismétlődő művelet lenne. Ez azt jelenti, hogyha odébbmozdul az ablak, átméretezzük, stb. akkor mindig újra kell rajzolni.
Ha a rajzolás közben számítjuk a pontokat, az ablak villogni fog, és lassú lesz a program. Ilyenkor érdemes bevezetni a puffert.
| int
main() { float* puffer[2], f; int i; puffer[0] = new int[1000]; puffer[1] = new int[1000]; for (f = -10; f < 10; f += 0.01) { i = (f + 10) * 100; //az indexet sokszor használjuk, ne kelljen mindig számolni puffer[0][i] = f; puffer[1][i] = f * f; } //...a függvény kirajzolása számtalan alkalommal a pufferből... delete [] puffer[0]; delete [] puffer[1]; return 0; } |
A grafikai résznél később még azt is felhasználjuk, animáláshoz, hogy csak azt a részt rajzoljuk át - ami megváltozott, ezzel is lényegesen gyorsítva azt.
5, A program közzététele
Ha rendelkezünk egy Release fordítású, optimalizált programmal már csak egy dolog maradt - a közzététel.
Erre alkalmas egyrészt a sourceforge.net, ha nyílt kódú megoldásban gondolkozunk, ha pedig nem akkor a saját weboldalunk.
Bármelyiket is választjuk, a közzététel előtt érdemes az alábbiakat elkészíteni:
- az alkalmazás tömörítése
- valamilyen súgó
- [/?] kapcsolóval szöveges módban
- .hlp/.chm fájl segítségével grafikus alkalmazásnál
- egy erre fenntartott külön weboldal (akár Wiki jellegű)
- egy telepítőkészlet (pl. Inno Setup által)
- egy hordozható csomag (pl. zip állományban)
- a forráskód szépen összerendezve, és becsomagolva (pl. tar.gz állományban)
Ha kész vagyunk, a kívánt oldalra feltölthetjük ezután - illetve saját oldal esetén, célszerű egy Google Drive, vagy hasonló dologra feltenni a programokat, és belinkelni.
5a, Az alkalmazás tömörítése
Az elkészített alkalmazások sok esetben elég nagyok is lehetnek, ilyenkor érdemes a Release fordítás mellett tömöríteni is őket.
Erre való az UPX parancssori eszköz. Letöltése után érdemes valamely PATH környezeti változóbeli mappába kibontani, hogy bárhol elérhető legyen.
Használata elég egyszerű, de a súgója felvilágosítást nyújthat még ezen felül is:
b:\Teszt_projekt\bin\Debug>upx "Teszt projekt.exe"
Ultimate Packer for eXecutables
Copyright (C) 1996 - 2013
UPX 3.91w Markus Oberhumer, Laszlo Molnar & John Reiser Sep 30th 2013
File size
Ratio Format Name
-------------------- ------ ----------- -----------
172938 -> 92042 53.22% win32/pe Teszt
projekt.exe
Packed 1 file.
Jól látható hogy a fájl mérete közel a felére csökkent az UPX hatására, és ezt az arányt képes tartani akkor is, ha a fájl sokkal nagyobb (akár több 100MB).
Talán a nevéből is kitalálható, hogy csak futtatható fájlokhoz jó, így tehát .DLL, .EXE, .OCX fájlokat képes tömöríteni - mást nem nagyon.
5b, A súgó elkészítése
A kapcsolós megoldásról már esett szó, ezért ezt nem részletezném.
A súgófájlok előállításához én személy szerint a HelpMaker 7 alkalmazást ajánlom (ami nyílt kódú). Használata nagyon egyszerű, sok magyarázatot nem igényel - és mind .hlp, mind .chm, és kész weboldal mentésére is képes.
Ha Wiki jellegű oldalt készítünk akkor értelemszerűen nincs szükség külön alkalmazásra.
5c, A telepítőkészlet előállítása
Itt is több lehetőség van, pl. az NSIS, az InstallShield, de én itt a szintén nyílt kódú Inno Setupot tudom ajánlani.
A varázslószerű adatmegadással, pikk-pakk kaphatunk az összes állományt tartalmazó, manapság is divatos telepítőkészletet. A példa telepítők és a program súgója magáért beszél.
Íme egy általa csinált telepítő:
Az elkészített telepítő, beépített eltávolítóval fog rendelkezni, így emiatt sem kell aggódni.
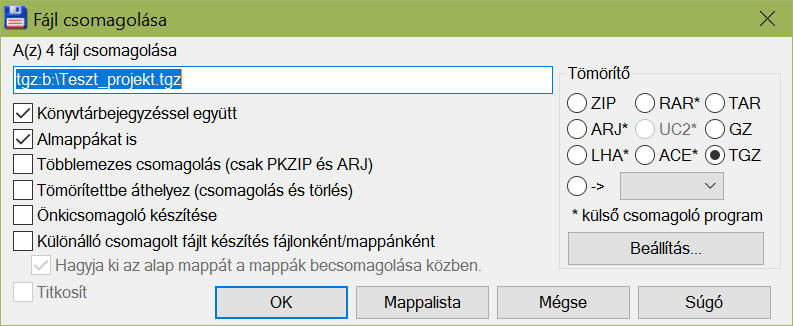
5d, A hordozható csomag/programkód összekészítése
Elsőrendben nem kell mást tenni, csak a programot és a hozzá szükséges fájlokat egy mappába tenni, majd becsomagolni egy .ZIP-be. Ezt akár Windows Intézővel (jobbklikk > Küldés > Tömörített mappa) is megcsinálhatjuk, illetve Total Commander által.
A tar.gz előállítása érdekesebb, de ez sem vészes - a Total Commander erre képes alapból - csak a becsomagolás során át kell állítani a pöttyöt: