
Bárhogyan is nevezzük őket, a számítástechnikában a szöveges típus rendkívül fontos, hiszen a legtöbb adatot leírhatjuk szövegként is.
A szöveges több típus eltérő néven fut, a szakirodalom néhol sztringként, néhol karakterláncként is említi - ezen cikkben is többféle néven is előfordulhat.
- A szöveges mód
- Egyetlen karakter beolvasása/kiírása a standard csatornákon
- Egyetlen karakter beolvasása - getchar, fgetc
- Egyetlen karakter kiírása - putchar, fputc
- A puffer törlése - fflush
- Egy nagyon egyszerű szöveges alkalmazás
- Egy egész karakterlánc beolvasása/kiírása a standard csatornákon
- Műveletek karakterláncokkal
- A jackpot utasítások - a printf, a scanf, és változataik
- A C++ egyszerűsítései
1, A szöveges mód
A mai grafikus operációs rendszerek alatt, alapvetően kétféle alkalmazástípussal találkozhatunk - az első a szöveges módú alkalmazás, a másik a grafikus rendszerű.
A szöveges módú alkalmazásoknál talán a legfontosabb gondolat hogy mindig egyablakosak - és csak szöveg által tudnak kommunikálni a felhasználóval:

Ugyanakkor léteznek speciális keretező (boxing) karakterek is, és ezek színezésével grafikusnak ható kezelőfelület is előállítható:

A szöveges módú alkalmazások, mindig csak egy betűtípust használhatnak egyszerre, amit a grafikus rendszerben lehet beállítani. A színek is korlátozottak, legfeljebb 16 szín használatára van lehetőség:

A karakterek elhelyezése korlátolt, a szöveges felületet táblázatszerűen kell elképzelni, ahol minden cellába csak egy karakter mehet. Ennek megfelelően a karakterek állandó szélességűek lesznek, ellentétben a szövegszerkesztővel, ahol változó szélességű karakterek vannak.
| állandó szélességű karakterek | változó szélességű karakterek |
| W . ; i S _ | W . ; i S _ |
Az hogy mekkora a képernyőterület, és hány színünk van, az régen a grafikus hardvertől (videókártya) függött, most attól hogy mennyit állítunk be:
| eszköz | színek | képernyőterületek |
| fekete-fehér | 40 oszlop, 25 sor | |
| legalább CGA | 16 színű | 40 oszlop, 25 sor |
| fekete-fehér | 80 oszlop, 25 sor | |
| EGA/VGA kompatibilis | 16 színű | 80 oszlop, 25 sor |
| MDA/Hercules | monokróm | 80 oszlop, 25 sor |
| EGA/VGA kompatibilis | 16 színű | rögzített 8x8 képpontos méretű
betűk: EGA esetén: 40 oszlop, 43 sor VGA estén: 40 oszlop, 50 sor |
Ezek közül, mivel a jelenleg legelterjedtebb videokártya szabvány a VGA, a kékkel jelölt szöveges mód az, amivel a leggyakrabban találkozhatunk.
Ugyanakkor grafikus rendszerek alatt lehetőség van arra is, hogy a szöveges mód területe lényegesen nagyobb legyen mint amit látunk - ilyenkor görgetősáv által tudjuk elérni a nem látható részt - és nem feltétlenül a 80x25 méret lesz a korlát:

A szöveges módban látható egy kurzor is - egy aláhúzás ("_") karakter ami villog - ez jelöli hogy éppen, ha most elkezdenénk írni a képernyőre, honnan kezdené. A kurzor elrejthető (pl. színes kezelőfelülettel bíró szöveges alkalmazásoknál szokták). Minden kiírás után a kurzor új helyre kerül, a kiírt szöveg végére.
Az adott képernyőterületen mozgathatjuk is a kurzort, ezáltal meghatározott helyekre is kiírhatjuk a szöveget. A kurzor koordináta rendszere az az alábbi módon működik:

Ezáltal ha a kurzor pozícióját a [13,42] koordinátára állítjuk, akkor a 14. sorban lesz, a 43. oszlopban (ha az adott üzemmód ezt támogatja) - ez nagyjából annak felel meg mintha mátrixszal dolgoznánk.
A szöveges mód később bővült egérhasználattal is - az egér úgy jelent meg hogy ahol állt, ott az adott karakter színei invertáltak voltak:
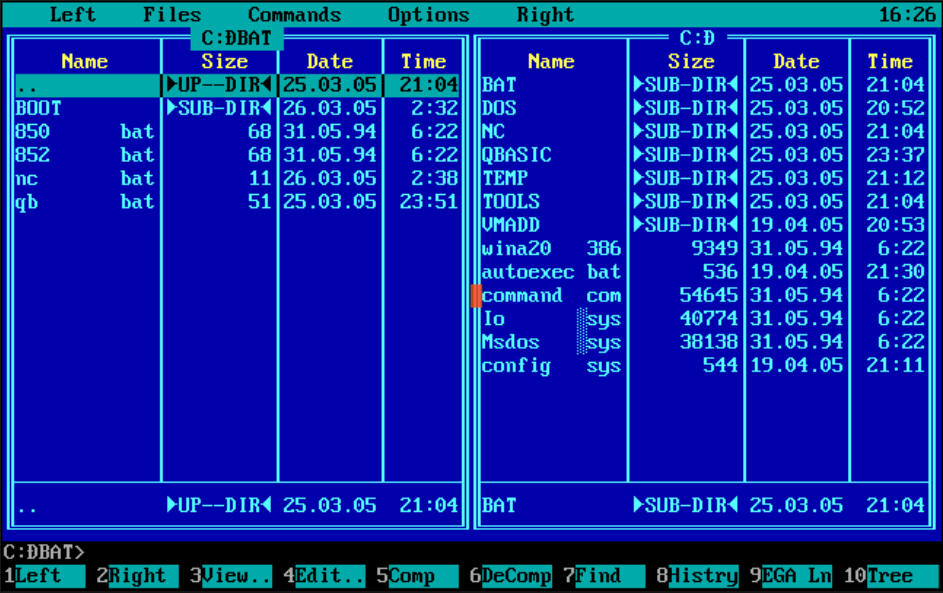
Végül pedig grafikus rendszerek alatt, választható opció volt sokáig hogy az adott szöveges módú alkalmazást ablakban, illetve teljes képernyőn kívánjuk futtatni.
Ez az opció legutoljára Windows XP alatt volt elérhető, azóta csak ablakos módban futtathatóak a szöveges módú programok.
Megjegyzés: A szöveges módú alkalmazás nem ugyanaz mint az DOS alapú
alkalmazás.
Jelenleg Windows alá is készíthetünk olyan alkalmazást, ami csak ilyen
kezelőfelülettel bír, ennek ellenére DOS alatt nem fut el. Az hogy a DOS
alkalmazások egy része, és a szöveges módú alkalmazások hasonlóan néznek ki,
csak a Windowsnak köszönhető.
Továbbá léteznek olyan DOS alkalmazások (pl. régi játékok) amik valódi
640x480 képpontos grafikus felületet teremtenek, és így futnak - mivel ezek megkövetelik a
teljes képernyőt, legfeljebb Windows XP alatt futnak el.
A Windows rendszerek 32 bites verziói a mai napig képesek szöveges DOS
alkalmazások futtatására, de a 64 bites verziók már nem - ugyanakkor Windows
alapú, szöveges módú alkalmazásokat mindkét rendszer képes futtatni.
Érdekesség: Az hogy a DOS és a BIOS hasonló szöveges üzemmódot használ, az nem véletlen - a DOS rendszer szándékosan olyan egyszerű hogy nagyon nagy részben a BIOS-ra épül, így innen örökli ezeket a beállításokat. Később plusz illesztőprogramokkal ezt már meg lehetett változtatni, de ha készítünk egy egyszerű rendszerindító floppyt, akkor ott ez az öröklődés igaz lesz.
1a, A standard be/kimenetek
Bármilyen szöveges módú alkalmazást is készítünk, három ki/illetve bemenettel tudunk operálni:
- standard input (stdin): erre a bemenetre kerül minden lenyomott billentyű, amiket később ki lehet olvasni - a lenyomás sorrendjében
- standard output (stdout): az erre a kimenetre kiírt adatok megjelennek a képernyőn - ha elértük annak a szélét akkor sortörést csinál a rendszer, ha pedig a jobb alsó sarkát akkor törli a legfelső sort, felcsúsztat mindent, és alul beszúr egy újat.
- standart error output (stderr): az erre a kimenetre kiírt adatok alapvetően ugyanúgy megjelennek a képernyőn mintha a standard outputot használnánk, de ezek akkor is megjelennek ha a standard output el van rejtve
A dolog szépsége, hogy ezen kimenetek nem csak a programnyelv alól érhetőek el, hanem az operációs rendszer alól is:
- standard input/output (CON): lásd fentebb
- null input/output (NUL): működése
megegyezik a standard inputéval/outputével néhány különbséget
kivéve:
- bemenetként használva soha nem fog rajta semmilyen adat megjelenni
- kimenetként használva az adatok amik rákerülnek, soha sem kerülnek kiírásra
- soros input/output (AUX, COM<sorszám>):
kétirányú csatorna, az adott számú soros/kommunikációs portot használva:
- bemenetként adatot olvas a soros portról
- kimenetként adatot ír a soros portra
- párhuzamos input/output (PRN, LPT<sorszám>):
kétirányú csatorna, az adott számú párhuzamos/nyomtatóportot használva:
- bemenetként adatot olvas a párhuzamos portról
- kimenetként adatot ír a párhuzamos portra
Ennek a csatornának a DOS alatt volt jelentősége, a legutolsó rendszerek amin még működtek a Windows 98/ME.
- tetszőleges fájl: ennek a kétirányú
csatornának a mai napig jelentősége van, segítségével a fájlokat
elképesztően könnyen lehet kezelni szöveges módú alkalmazásokkal
- pl.
- egy mappa tartalma azonnal kilistázható egy fájlba egy régi parancssori parancs, illetve átirányítás által
- ha a programunk adatokat olvas be a képernyőről, és van egy fájlunk ami a megfelelő sorrendben tartalmazza ezeket megadható hogy a program a képernyő helyett a fájlból olvasson be mindent, lényegében minimális módosításokkal
- másik alkalmazás: ha van egy másik szöveges
módú alkalmazás, megadható hogy az egyik kimenete legyen a másik
bemenete, illetve fordítva - pl.
- a parancssori formázás során a gép rákérdez arra hogy biztos szeretnénk-e (I/N) - ha van egy programunk ami I betűket ír ki - a formázó paranccsal összekapcsolva a formázás automatizálható
Ezen be/kimeneteknek csak egy része érhető el közvetlenül a programozás folyamán - ilyen a három standart ki/bemenet, illetve a fájlok. A többi kimenet elérése komolyabb programozást igényelhet.
Ezen csatornák puffereltek, ami azt jelenti hogyha begépelünk sok-sok adatot, és valamilyen módon gyorsabbak lennénk mint a program, akkor sincs gond - mivel a rendszer eltárolja minden karakterünket egy ideiglenes tárolóba (puffer), amiből a program akkor olvashatja ki, amikor jól esik neki.
Megjegyzés: Mivel a Windows őrzi a DOS okozta korlátok egy részeit, kompatibilitási okok miatt, mind a mai napig nem lehet pl. CON, NUL, PRN, stb. névvel mappákat/fájlokat létrehozni. Ezt egyszerűen le lehet tesztelni személyesen is.
1b, Másolás fájlok és be/kimenetek között parancssor alól
Ez most egy kis parancssori alapozásnak tekinthető, hiszen ezen kimenetek helyes megértéséhez szükséges az hogy a parancssort tudjuk használni. A leírás jelen esetben MS-DOS alapú parancssorhoz illeszkedik - a Linux terminálja jelentősen eltérhet ettől.
Ezeket a példákat a Parancssor segítségével tudjuk kipróbálni (Start Menü > Kellékek > Parancssor).
Elsőként ismerkedjünk meg a másolás parancsával a copy-val. A copy parancs használáta:
copy <forrás> <cél>
Természetesen ennél lényegesen többet tud, de kezdetnek elég ennyi is (a "help copy" parancs teljes leírást ad).
Íme néhány példa:
- copy "D:\Teszt.txt" "D:\Adatok\Teszt.txt"
- copy "D:\Adatok\T*.tx?" "D:\Szövegfájlok\*.*"
- copy CON: "D:\ÚjAdat.txt"
- copy "D:\ÚjAdat.txt" CON:
- copy "D:\ÚjAdat.txt" NUL:
Megjegyzés: Ha nincs D:\ meghajtónk, vagy az CD-meghajtó, akkor is kerüljük hogy a C:\ gyökérkönyvtárát használjuk - Windows XP-nél újabb rendszereken ehhez rendszergazdai jog szükséges.
Az első példa elég érthető, lemásol egy fájlt, az egyik helyről a másikra. Természetesen grafikus rendszerben ezt könnyebb kivitelezni, akár az Intéző segítségével, akár egy Total Commander által.
A második példa már egy kicsit érdekesebb lehet, ha itt találkozunk először a fájlmaszkokkal. Itt két új jellel lehet megismerkedni, ezek a csillag, és a kérdőjel.
- Ha nem ismerjük a fájlnév egyetlen betűjét, akkor a kérdőjel jelöli hogy az bármi lehet.
- Ha nem ismerjük a fájlnév hátralévő részét, akkor a csillag jelöli azt hogy innentől bármilyen szöveg állhat. Érvényessége vagy a fájlnév végéig tart, vagy a pontig.
Ezeket felhasználva megállapítható, hogy melyik fájlokat fogja átmásolni, és melyiket nem:
Adatok.txt
Film.AVI
ÚjAdat.TXT
teszt.txt
teszt.tx_
Toll.TDT
Toll.TXT
Tartók.TXT3
Tetőépítés.bmp
Weboldal.HTML
Első kritériumunk az volt hogy a fájlnév kezdődjön T betűvel. Ez már alapból kizár egy pár lehetőséget.
A második kritériumunk az volt, hogy a kiterjesztése (a pont utáni rész), három betűs legyen, amiből az első kettő TX, a harmadik teljesen mindegy. Ennek megfelel a TXT és a TX_, de kizárja a TDT, illetve a TXT3 lehetőségeket.
Természetesen MS-DOS/Windows alatt a kis és nagybetűk nem számítanak, így a txt, illetve tx_ kiterjesztés is szóba jöhet - illetve a fájlnév kezdődhet kis "t" betűvel is.
A harmadik példánál a forrás a standard input. Ennek hatására az "1 fájl másolása megtörtént." üzenetünk elmarad, és a kurzor villog.
Jelen esetben a parancssor arra vár, hogy begépeljük a szöveget, amit az ÚjAdat.txt fájlba fogunk másolni - készítettünk egy szövegszerkesztőt egyetlen paranccsal.
A probléma csak az, hogyha begépeljük a szövegünket, nem jön rá magától hogy mi befejeztük. Ezt két módon történhet:
-
Ctrl+C: félbeszakít bármilyen kiadott parancsot, a szöveg amit begépeltünk el fog veszni - ha fájlok másolása közben nyomnánk le, azt is félbehagyná
-
Ctrl+Z: "end-of-file" jel - ha ezt leütjük, majd esetleg egy új sorba is lépünk utána, a copy parancs lementi amit begépeltünk a fájlba.
A Ctrl+Z lenyomása után megjelenik az óhajtott "1 fájl másolása megtörtént." üzenet, és ha megnézzük a txt fájlunk tartalmát, valóban benne van amit begépeltünk (az ékezetek eltérhetnek, erről később).
Ha a harmadik példa sikerült, a negyedik kimásolja a fájl a standard outputra.
Elvileg, ékezethelyesen ki kell írnia amit az ÚjAdat.txt fájlba begépeltünk.
Ha létezik az ÚjAdat.txt, akkor kapunk egy "1 fájl másolása megtörtént." üzenetet, de semmi mást.
Most a null outputra küldtük a fájl tartalmát, így ebből semmit nem fogunk látni.
Megjegyzés:
Azért van az hogy ami a Parancssorban jól néz ki ékezetes karakter, a
Jegyzettömbben zagyvaság és fordítva, mert a két program kódlapja eltér.
Ez angol nyelvterületen nem gond, de itt igen. A Parancssor, a DOS-szal
való kompatibilitási okok miatt a "852-es
kódlapot" (ami a
437-es ASCII egyik változata) használja, míg a Windows az
ANSI-t (ami közel megegyezik az a
437-es ASCII-val).
Ennek a következménye hogy egyes karakterek sorszámai el fognak térni
egymástól, és ezek főként a nyelvspecifikus karakterek lesznek. Erről a témáról
már érintőlegesen esett szó itt.
Ha a szövegek kiíratása során emiatt zagyvaságokat kapunk, össze-vissza
annyi a teendő hogy a
Notepad++ segítségével át kell alakítani a .C fájlunkat 852-es
kódlapúra. Így a szöveges módú alkalmazások helyesen fognak megjelenni (így a
grafikus alapúak nem).
1c, Az átirányítás
Ha az előző szakaszt sikeresen értelmeztük, akkor megismerkedünk egy újabb parancssal, aminek a célja hogy fájlokat ír ki a standard outputra - a neve type. A használata elég egyszerű:
type <forrás>
Íme néhány újabb kipróbálható példa:
- type "D:\ÚjAdat.txt"
- type CON:
- type NUL:
Az első példa egyszerű, kiíratja a korábban létrehozott fájlunkat.
A második példa a standard inputról fog adatokat beolvasni, és kiírja a képernyőre - lényegében megismétli amit beírunk, amíg fájl vége (Ctrl+Z) jelet nem kap.
A harmadik példa a null inputról olvas - de mivel itt sosincs adat, ezért nem fog csinálni semmit.
Ahhoz hogy valami értelmeset kezdjünk ezzel a paranccsal, bevezetjük az átirányítási operátort. Ennek lényege hogy összecserélhetjük vele a parancs által használt standard ki/bemeneteket.
Ez által például megadható, hogy az eredményt ne a képernyőre, hanem a nyomtatóportra küldje a parancs, illetve hogy ha adatokat olvas be, akkor azt ne a képernyőről tegye, hanem pl. egy fájlból.
Az átirányítás jele:
- < : ha a standard inputot szeretnénk lecserélni
- > : ha a standard outputot szeretnénk lecserélni, átírásra
- >> : ha a standard outputot szeretnénk lecserélni, hozzáfűzésre
- 2> : ha a standard error outputot szeretnénk lecserélni
Íme még néhány példa:
- type CON: > "D:\ÚjAdat2.txt"
- type "D:\ÚjAdat.txt" > NUL:
Az első variáció megint a rögtönzött szövegszerkesztőnket eredményezi. A mentést itt is Ctrl+Z segítségével érhetjük el.
A második példa pedig a fájlt ezúttal nem a képernyőre, hanem a null kimenetre írja ki.
1d, Az összekapcsolás
Két program összekapcsolásáról is szó volt a be/kimenetek felsorolásánál, így erre is nézhetünk egy példát.
A parancssori formázást a format paranccsal lehet elvégezni, használata:
format <meghajtó>:
Természetesen megint csak többet is tud (lásd "help format"), de nekünk most ennyi is elég. Egyéb tudnivaló, hogy a futtatáshoz rendszergazdai parancssor kell (jobbklikk a Parancssor ikonjára > Futtatás rendszergazdaként).
Szintén egy másik szükséges parancs az echo, ami megismétli a beírt szöveget:
echo <szöveg>
Ha elindítjuk a formázást pl. a C:\ meghajtóra, ezt az üzenetet kapjuk:
C:\Users\Laci bá'\> format C:
A fájlrendszer típusa NTFS.
FIGYELEM! A NEM CSERÉLHETŐ LEMEZEN (C:) MINDEN ADAT ELVÉSZ!
Folytatja a formázást? (I/N) n
Természetesen mi az N betűt fogjuk lenyomni, mivel nem szeretnénk megtenni ezt - de a két parancs összekapcsolásával ez automatizálható.
A következő parancs amit kiadunk az legyen ez:
C:\Users\Laci bá'\> echo N
N
Amint láthattuk valóban megismétli a beírtakat - így már csak össze kell dobni a kettőt - ehhez pedig az összekapcsolás (pipe) operátor fog kelleni, ami a "|" lesz:
C:\Users\Laci bá'\>
echo N | format C:
A fájlrendszer típusa NTFS.
FIGYELEM! A NEM CSERÉLHETŐ LEMEZEN (C:) MINDEN ADAT ELVÉSZ!
Folytatja a formázást? (I/N)
Mivel a format, most egy másik parancsból kapja a választ, ezért nem fog megjelenni az n betű a képernyőn - de le fog állni a formázás előtt.
Persze ennek így nincs értelme, de pl. egy operációs rendszer telepítőprogramjában, ha I betűt íratunk ki, akkor annak már van - viszont egy ilyen próbálkozásért gondolom egyik olvasó sem tenné tönkre a gépét.
2, Egyetlen karakter beolvasása/kiírása a standard csatornákon
Mielőtt egy egész karakterláncot beolvasnánk, nézzük meg hogyan lehet egyetlen karaktert beolvasni/kiírni.
Az itt található utasítások nagyon nagy százaléka az stdio.h fájlban lesz megtalálható.
2a, Egyetlen karakter beolvasása - getchar, fgetc
char getchar()
char fgetc(FILE* source)
Ezen két utasítás, egy-egy karaktert olvas be - a getchar a standard inputról (képernyőről), míg az fgetc egy megadott csatornáról.
source: Az adott csatornát jelképező struktúramutató (akár fájl is lehet, akár a fentebb megismert csatorna).
A függvények visszatérési értéke a kiolvasott karakter ha sikeres volt az olvasás, egyébként pedig fájlvége jel (EOF).
Példa:
| char c =
getchar(); char d = fgetc(stdin); |
A két utasítás, a példában használt módon egyenértékű.
Megjegyzés:
A karakterek beolvasására még számtalan utasítás van, pl. getch, getche,
fgetchar, stb. - mivel nagyjából egyenértékűek mindegy melyiket használjuk.
Mivel a C/C++ nyelvben a char változó jelöli a byteokat is, ezért ezek
segítségével bármilyen adat kiolvasható, mint byteok sorozata (pl. fájlból
olvasáskor).
2b, Egyetlen karakter kiírása - putchar, fputc
char putchar(char ch)
char fputc(char ch, FILE* dest)
Ezen két utasítás, egy-egy karaktert ír ki - a putchar a standard outputra (képernyőre), míg az fputc egy megadott csatornáról.
char: Az a karakter, amit ki
szeretnénk írni az adott kimenetre.
dest: Az adott csatornát jelképező struktúramutató (akár fájl is lehet,
akár a fentebb megismert csatorna).
A függvények visszatérési értéke a kiírt karakter ha sikeres volt az írás, egyébként pedig fájlvége jel (EOF).
Példa:
| putchar('A'); fputc('A', stdout); |
A két utasítás, az ebben a példában használt módon egyenértékű.
Ugyanakkor az fputc segítségével könnyen elérhető a hibakimenet is:
| fputc('A', stderr); |
Megjegyzés:
A karakterek kiírására még számtalan utasítás van, pl. putch, fputchar,
stb. - mivel nagyjából egyenértékűek mindegy melyiket használjuk.
Mivel a C/C++ nyelvben a char változó jelöli a byteokat is, ezért ezek
segítségével bármilyen adat átmásolható egy kimenetre, mint byteok sorozata (pl.
fájlba íráskor).
2c, A puffer törlése - fflush
Gyakran szükségessé válhat, hogy az adott csatornához tartozó puffert kiürítsük.
Ilyen példa amikor két getchar után a második már nem működik, mert az első után <ENTER> billentyűt ütöttünk, és ez bennmaradt a pufferban. Emiatt a második getchar már csak az <ENTER> billentyűt fogja kiolvasni.
Érdekesség: az <ENTER> alapvetően két karakter a programozásban:
- '\xD': Ez a sorszám jelképezi az új sorba [new line] lépést - vízszintesen még nem kerül odébb a kurzor [13-as számú karakter]
- '\xA': Ez a sorszám jelképezi a "kocsi vissza" [carriage return] lépést - mikor vízszintesen a sor elejére kerül a kurzor [10-es számú karakter]
Ez az írógépből származtatható dolog - viszont a két karakter egyidejű kezelése problémákat okozhatna - erre a C megoldást is nyújt, csak kiíráskor írja ki mind a kettőt, míg a memóriában csak a '\xD' változat lesz tárolva.
Ezen problémák orvoslására van bevezetve az fflush függvény:
char fflush(FILE* dest)
Ez az utasítás törli a puffert az adott csatornán.
dest: Az adott csatornát jelképező struktúramutató (akár fájl is lehet, akár a fentebb megismert csatorna).
A függvény visszatérési értéke a nulla ha sikeres volt a művelet, egyébként pedig fájlvége jel (EOF).
Példa:
| char c =
getchar(); fflush(stdin); char d = getchar(); |
2d, Egy nagyon egyszerű szöveges alkalmazás
Nézzük meg mit csinál ez az alkalmazás:
EGYSZERU.C
| #include <stdio.h> int main() { char c; do { c = getchar(); putchar(c); } while (c != EOF); return 0; } |
Ha elindítjuk amit beírunk megduplázza, egészen addig amíg nem nyomunk fájl vége jelet (Ctrl+Z).
Ennek így első pillanatra nincs sok értelme, de átirányítással nagyon sok dologra alkalmas (persze parancssor alól):
EGYSZERU.EXE > teszt.txt
Ilyenkor kapunk egy szövegszerkesztőt, kissé hasonló mint amit a type illetve a copy által előállítottunk. De íme egy másik felhasználás:
EGYSZERU.EXE < teszt.txt
Ilyenkor kiírja a teszt.txt tartalmát.
A zseniális ebben a programban hogy közvetlenül együtt dolgozik az operációs rendszerrel, és emiatt nem több mint 12 sor kód elég az elkészítéséhez (tagolással együtt).
Megjegyzés: A parancssor nem mindig abban a mappában van amire szükségünk van. Például nekem most el kéne navigálnom a D:\Progik\ mappába - ezt így lehet megtenni
C:\Users\Laci bá'> D:
D:> cd "D:\Progik\"
D:\Progik> egyszeru.exe > teszt.txt
Szerintem a példa nem szorul magyarázatra - meghajtó váltásához be kell írni a betűjelet, a mappába lépéshez pedig a cd (change directory) parancsot kell használni.
3, Egy egész karakterlánc beolvasása/kiírása a standard csatornákon
Mielőtt a karakterlánc beolvasásával kezdenénk, érdemes újra átnézni annak a felépítését C/C++ alatt:
| A | z | a | l | m | a | z | ö | l | d | . | |||
| 65 | 122 | 32 | 97 | 108 | 109 | 97 | 32 | 122 | 246 | 108 | 100 | 46 | 0 |
Amint ezt már korábban tárgyaltuk, a dinamikus tömbök hosszait tudni kell - túlindexelésük összeomlást okozhat, illetve szó esett arról is hogy a sztringek végén van egy '\0' (nulla sorszámú) zárókarakter.
Ennek lesz az a lényege, hogy általa meghatározható a sztring hossza - ennek hiányában könnyedén omlaszthatjuk össze a programot. Erre oda kell figyelni ha pl. ismétlődő getchar() hívásokkal rakjuk össze a szöveget.
A dinamikus tömbök esetében lehetett tervezni a hosszukat, hiszen pl. beolvassuk a képernyőről - sztring esetén nem fogjuk előre tudni hogy a felhasználó mennyit fog gépelni. Erre két megoldás van:
- Olyan karaktertömböt veszünk fel, ami sokkal hosszabb mint a bekérendő szöveg (pl. egy névhez 200 karakter elég kell legyen) - kerülve a túllógó részeket
- Olyan utasítást használunk amely odafigyel a hosszra is, pl. fgets (később) - ilyenkor a túllógó rész lemarad
A karaktertömböt felvenni az alábbi módon tudjuk:
| char sz[50]; |
Ez 49 betűt jelent +1 zárókaraktert ('\0').
A karaktertömbök egyik másik lehetséges megadása a char*, amikor a tömb vagy dinamikus, vagy függvényeken át kapjuk meg, és így már nem tudjuk az eredeti hosszát. Természetesen a zárókarakter miatt ez meghatározható.
Az itt található utasítások nagyon nagy százaléka az stdio.h fájlban lesz megtalálható.
3a, Egy karakterlánc beolvasása - gets, fgets
char* gets(char*
str)
char* fgets(char* str,
int num, FILE* source)
Ezek az utasítások beolvasnak egy egész karakterláncot, - a gets a standard bementről, az fgets a megadott csatornáról.
str: Azon tömb memóriacíme, amibe szeretnénk
a beolvasást elvégezni (lehet statikus, dinamikus)
num: A megadott tömb hossza - legfeljebb hány karaktert tud tárolni
source: Az adott csatornát jelképező struktúramutató (akár fájl is
lehet, akár a fentebb megismert csatorna).
A függvények visszatérési értéke a nulla ha sikeres volt a művelet, egyébként pedig fájlvége jel (EOF).
Fontos:
Ha nem vagyunk biztosak benne hogy a tömbünkben el fog férni a begépelt
szöveg, kerüljük a gets használatát - a túlfutás miatt hibákat okozhat. Ezen
felül a gets lehagyhatja a zárókaraktert is néha - amit kézzel kell pótolnunk
ilyenkor.
Példa:
| char
sz[50]; gets(sz); char _sz[50]; fgets(_sz, 50, stdin); |
Az itt látható két példa közel egyenértékű, de ha egy 60 karakteres szöveget gépelek be, az első összeomlasztja a programot, míg a második nem. Ettől eltekintve funkciójuk megegyezik.
Megjegyzés:
Érdemes lehet két gets hívás között a puffert kiűríteni az fflush által.
3b, Egy karakterlánc kiírása - puts, fputs
int puts(char*
str)
int puts(char* str,
FILE* dest)
Ezek az utasítások kiírnak egy egész karakterláncot, - a puts a standard kimenetre, az fputs a megadott csatornára.
str: Azon karakterlánc, amit ki szeretnénk
íratni az adott csatornára.
dest: Az adott csatornát jelképező struktúramutató (akár fájl is lehet,
akár a fentebb megismert csatorna).
A függvények visszatérési értéke egy nem negatív szám, egyébként pedig fájlvége jel (EOF).
Fontos:
A zárókarakter hiánya összeomlaszthatja a programot, ezen függvények
hívásakor.
Példa:
| char
sz[] =
"Helló világ!"; puts(sz); fputs(sz, stdin); |
Az itt látható két példa közel egyenértékű, egy különbség mégis van. A puts a kiírás után új sorba lép, míg az fputs nem.
| char
sz[] =
"Helló világ!"; fputs(sz, stderr); |
Az fputs alkalmas arra is hogy a hibakimenetre írja a szöveget. Az ilyen üzenetek átirányítása a parancssori "2>" operátorral lehetséges.
4, Műveletek karakterláncokkal
Miután a szövegeket ki tudjuk olvasni/írni a különféle alap csatornákon, érdemes megnézni - milyen műveletek végezhetőek velük.
Az itt található utasítások nagyon nagy százaléka az string.h fájlban lesz megtalálható.
4a, Egy szöveg hossza - strlen
unsigned int strlen(const char* str)
Megméri egy sztring hosszát a zárókaraktere alapján. (Calculates a string's length). A zárókaraktert már nem számolja a hosszba.
str: Azon karakterlánc, amin a műveletet elvégzi.
A függvény visszatérési értéke a szöveg hossza.
Fontos:
A zárókarakter hiánya összeomlaszthatja a programot, ezen függvények
hívásakor.
Példa:
| char
sz[50]
= "Helló világ!"; int n = strlen(sz); //n = 12 |
4b, Két szöveg összehasonlítása - strcmp
int strcmp(const char* str1, const char* str2)
Összehasonlítja betűrend szerint a két szöveget. (Compares two strings.)
str1, str2: Azon karakterláncok, amiket összehasonlít.
A függvény visszatérési értéke:
- < 0: ha a sorrendben a második van előrébb
- = 0: ha pontosan megegyeznek
- > 0: ha a sorrendben az első van előrébb
Fontos:
A zárókarakter hiánya összeomlaszthatja a programot, ezen függvények
hívásakor.
Példa:
| char
sz[50]
= "Helló világ!"; char ss[50]; fgets(ss, 50, stdin); if (strcmp(sz, ss) == 0) puts("Eltaláltad!"); |
Megjegyzés:
A betűrend szimplán az adott kódlap alapján fog előállni - emiatt az
ékezetes betűk a z után jönnek, illetve a számozás is hulladék lesz (1, 10, 11,
12, 13, 2, 3, 4, ...).
Mindezek figyelembe vételéhez érdemes használni az ezzel egyenértékű
StrCmpLogicalW utasítást, ami a Windows része, de használata
ezzel megegyezik - ez ékezeteket is sorba tesz, illetve jól számoz (PCWSTR =
wchar_t*).
4c, Szöveg lemásolása - strdup
char* strdup(const char* str)
Ha van egy szövegünk, és le akarjuk másolni - használhatjuk az strdup utasítást - ami egy dinamikus tömböt készít, és belemásolja a megadott szöveget. (Duplicates a string.)
Ez azért szükséges, mert ha felveszünk 3db char* változót, és egy adott tömb címét belerakjuk mindháromba, bármelyiket írjuk/olvassuk a tömböt írjuk/olvassuk.
Az strdup megszünteti ezt az anomáliát, és így pl. megháromszorozható a szöveg, hogy mindegyik char* változónkhoz egy-egy saját szöveg tartozzon.
str: Azon karakterlánc, amit le fog másolni.
A függvény visszatérési értéke a másolat karakterlánc címe ha sikerül a művelet, egyébként NULL.
Fontos:
A zárókarakter hiánya összeomlaszthatja a programot, ezen függvények
hívásakor.
Példa:
| char
sz1[50]
= "Helló
világ!"; char* sz2, sz3; sz2 = sz1; //az sz2 egy hivatkozás lesz az sz1-re sz3 = sz2; //az sz3 is egy hivatkozás lesz az sz1-re sz2[0] = 'B'; sz3[0] = 'C'; puts(sz1); //kiírja: Celló világ! puts(sz2); //kiírja: Celló világ! puts(sz3); //kiírja: Celló világ! |
| char
sz1[50]
= "Helló
világ!"; char* sz2, sz3; sz2 = strdup(sz1); //az sz2 egy önálló másolata lesz az sz1-nek sz3 = strdup(sz2); //az sz3 egy önálló másolata lesz az sz2-nek sz2[0] = 'B'; sz3[0] = 'C'; puts(sz1); //kiírja: Helló világ! puts(sz2); //kiírja: Belló világ! puts(sz3); //kiírja: Celló világ! |
Megjegyzés: Az első példa nem helytelen, ha pont a hivatkozás létrehozása a cél - de ha ez nem célunk, egy ilyen kivitel meglepő eredményt hozhat.
4d, Két szöveg összekapcsolása - strcat
char* strcat(const char* dest, const char* str)
Összekapcsolja a két szöveget. (Concatenates two strings.)
dest: Az amihez hozzákapcsolja a második
tagot. A hossza akkora kell legyen, hogy a kettő együtt is
elférjen benne.
str: Azon karakterlánc, amit hozzákapcsol a dest-hez.
A függvény visszatérési értéke a dest.
Fontos:
A zárókarakter hiánya összeomlaszthatja a programot, ezen függvények
hívásakor.
Példa:
| char
sz[50]
= "Helló "; char s2[10] = "világ!"; strcat(sz, s2); puts(sz); //kiírja: Helló világ! |
Megjegyzés:
Hiába tárolunk számokat a karakterláncban, azokat csak karakterenként
fogja összeadni, pl. "516" + "546" = "516546". Lényegében csak összemásolja a
két szöveget.
Ha a számok összegére vagyunk kíváncsi akkor előbb át kell alakítani int
típusúvá a két szöveget, és úgy összeadni (lásd alább).
4e, Szöveg átalakítása más típusokká - atoi, atol, atof
int atoi(const
char* str)
long int atol(const char* str)
double atof(const char* str)
A szöveg átalakítása más típussá nem megy sima típuskonverzió alapján (visszafele sem), hanem ki kell elemezni a szöveget, és különféle algoritmussal kell átalakítani. Ezek a függvények ezt végzik el. (ansi-to-int, ansi-to-long, ansi-to-float)
str: Azon karakterlánc amit átalakítunk.
A függvények visszatérési értéke az átalakított érték, egyébként nulla.
Fontos:
A zárókarakter hiánya összeomlaszthatja a programot, ezen függvények
hívásakor.
Példa:
| char
sz[50]
= "64.51654"; double f = atof(sz); puts("Kérek egy egész számot: "); gets(sz); long int l = atol(sz); f += l; |
5, A jackpot utasítások - a printf, a scanf, és változataik
A fentebbi utasítások összekombinálásának eredménye ez a két zseniális utasítás. Alapvetően az első cikkben már találkozhattunk velük - adatok behelyettesítései végzik el, illetve kiíratást/beolvasást.
A helyettesítés a formátumsztring alapján történik, amiről érdemes kicsit többet is beszélni, mert az eddig bemutatott példákhoz képest, sokkal komolyabb megoldások is kivitelezhetőek általa.
Az utasításpár annyira sikeres, hogy sok más programnyelvre is átírták ezeket az utasításokat (pl. Free Pascal, Delphi) - hihetetlen rugalmasságának köszönhetően.
5a, A formátumsztring
A formátumsztring alapvetően csak a helyettesítést szolgálja - azokat a jelöléseket amivcl pl. új sort szúrunk be vezérlőkaraktereknek nevezzük - ezekről később lesz szó.
Amikor először esett szó a helyettesítésről, fel volt sorolva ~5 db lehetőség, amelyekkel néhány gyakori változót beírhattunk - pl. arról szót sem ejtve hogy milyen formázási lehetőségek vannak.
Egyetlen helyettesítés így nézhet ki teljes pompájában:
%[jelzők][szélesség][.pontosság][hossz]típus
Most az egyes mezők lehetséges értékeit fogjuk tárgyalni (a szögletes zárójelben lévő adatok nem kötelezőek).
5b, A helyettesíthető változók típusa
%[jelzők][szélesség][.pontosság][hossz]típus
A helyettesítés során fontos megjegyezni, hogy egy adott helyre bármilyen típus helyettesíthető, ha a típusa közelítőleg megegyezik - így pl. egy enum is kiírható számként a %d által.
Fontos hogy ez a sorszámozott típusokra érvényes, ha a sizeof(<egyik>) = sizeof(<másik>) - de azonos méret esetén sem cserélhető össze pl. az egész szám a valóssal. Az váratlan eredményeket okozhat, netán összeomlást is.
Íme tehát az egyes típusokhoz tartozó helyettesítési jelek:
| típus | helyettesíthető változók | példa |
|---|---|---|
| %d vagy %i | előjeles egész szám | 392 |
| %u | előjel nélküli egész szám | 7235 |
| %o | előjel nélküli egész szám nyolcas számrendszerben | 610 |
| %x | előjel nélküli egész szám tizenhatos számrendszerben (kisbetűs) | 7fa |
| %X | előjel nélküli egész szám tizenhatos számrendszerben (nagybetűs) | 7FA |
| %f | valós szám tizedestörtként (kisbetűs) | 392.65 |
| %F | valós szám tizedestörtként (nagybetűs) | 392.65 |
| %e | valós szám normálalakban (kisbetűs) | 3.9265e+2 |
| %E | valós szám normálalakban (nagybetűs) | 3.9265E+2 |
| %g | valós szám legrövidebb alakja (%e vagy %f közül) | 392.65 |
| %G | valós szám legrövidebb alakja (%E vagy %F közül) | 392.65 |
| %a | valós szám tizenhatos számrendszerben (kisbetűs) | -0xc.90fep-2 |
| %A | valós szám tizenhatos számrendszerben (nagybetűs) | -0XC.90FEP-2 |
| %c | karakter | a |
| %s | karakterlánc, sztring, szöveg | pelda |
| %p | mutató által kijelölt memóriacím | b8000000 |
| %n | nem ír ki semmit, a hozzá tartozó változónak egy int* típusnak kell lennie - ebbe belemásolja az eddig kiírt karakterek számát | |
| %% | az operátorként lefoglalt százalékjelet pótolja - által százalékjel is kiírható | % |
Ez már alapvetően jól lehatárolja a helyettesíthető adatokat, de pl. valós szám esetén nem mindegy hogy float, double, vagy long double típussal dolgozunk, és ezt is jelölni kell. Erre való a hossz mező:
| típus | |||||||
|---|---|---|---|---|---|---|---|
| hossz | d i | u o x X | f F e E g G a A | c | s | p | n |
| (nincs) | int | unsigned int | float, double | char | char* | void* | int* |
| hh | signed char | unsigned char | signed char* | ||||
| h | short int | unsigned short int | short int* | ||||
| l | long int | unsigned long int | wchar_t | wchar_t* | long int* | ||
| ll | long long int | unsigned long long int | long long int* | ||||
| j |
a platformra jellemző legnagyobb kezelhető int típus (intmax_t, uintmax_t) |
intmax_t*, uintmax_t* |
|||||
| z, t |
a platformra jellemző általános előjel nélküli egész típus (unsigned int = size_t = ptrdiff_t) |
unsigned int* = size_t* = ptrdiff_t* |
|||||
| L | long double | ||||||
A p esetén csak a void* van felsorolva - de bármilyen típusos mutató is kiíratható.
A d, i oszlopban bár nincs kiírva - de az int signed típusként lesz értelmezve, vagyis bármelyik elé odaírható a signed kulcsszó.
A c esetében, az adott karakterkódot tartalmazhatja int típus is - ha a hossza megfelelő. Ilyenkor nem számként lesz kiírva, hanem az értékhez tartozó betűként. Az általános esetben a hosszokat figyelembe véve:
char = unsigned char ~ unsigned short short int
, ezen felül,
signed char ~ signed short short int = short short int
Természetesen ez a megállapítás az Unicode karakterre is megtehető:
wchar_t = unsigned wchar_t ~ unsigned long int
, illetve,
signed char ~ signed long int = long int
A platformfüggő típusok esetében a számítógép kiépítése a fontos, ez meghatározza a sima int típusok hosszát, emiatt az alap hosszjelet is (a z, és a t sora):
- 8 bit: int = short short int = char
- 16 bit: int = short int
- 32 bit: int = long int = wchar_t
- 64 bit: int = long long int
Ezen megállapítások igazak mind signed, mind unsigned típusokra is.
Az adott platformon használható szokott lenni eggyel nagyobb típus is, vagyis egy 32 bites rendszer még éppen fog tudni számolni egy 64 bites számmal, de sokkal lassabban mint egy 64 bites rendszer. Egy 16 bites rendszer legfeljebb 32 bites számmal tud számolni, és így tovább...
Azt a számot, amivel legfeljebb tud számolni a gép, azt a j esetén kapjuk - az ide tartozó típusok pedig az intmax_t, uintmax_t. Így hát:
- 8 bit: intmax_t = short int
- 16 bit: intmax_t = long int
- 32 bit: intmax_t = long long int
- 64 bit: intmax_t = long long int
Továbbá ez megint igaz lesz, mind a signed, mind az unsigned típusra is. A 64 bites rendszerek esetén akkora a legnagyobb kezelhető szám, hogy a mindennapokban még nem volt szükség 128 bites számérték bevezetésére, így 64 bites rendszernél pillanatnyilag 64 bites számokkal tudunk számolni legfeljebb - de nem a hardver korlátaiból adódóan.
Példa:
| char
sz[50]
= "Helló világ!"; long long int nagyszam = -1; long double pontos_szam = 3.1416; printf("%s, %lld, %Lf", sz, nagyszam, pontos_szam); |
5c, A helyettesíthetés elrendezése, a jelzők
%[jelzők][szélesség][.pontosság][hossz]típus
Ha kiválasztottuk a megfelelő típusjelölést (pl. %llX), akkor már csak azt kell meghatározni - ha szeretnénk - hogy milyen elrendezéssel írjuk ki a változót.
Az elrendezés megadására két lehetőségünk van, a pontosság és a hossz. A pontosság azt adja meg hogy az adott szám hány tizedes pontossággal legyen kiírva, míg a hossz az adott szám teljes hosszát jelenti.
Ha nem adunk meg semmit, a pontosság 6 értékes jegy kiírását kéri (ha van annyi), míg a hossz nincs korlátozva.
Ha a hossz nagyobb mint az átalakított szám, akkor alapesetben szóköz karakterekkel lesz feltöltve a szükséges hely, míg ha kevesebb akkor nem történik semmi (nem vágja le).
Példa:
| double szam =
3.1416; printf("%.2f", szam); //3.14 printf("%7.2f", szam); // 3.14 |
Előállhat olyan eset is, amikor nem tudjuk előre hogy milyen pontossággal/hosszal szeretnénk formázni a szöveget, ilyenkor ezt változó/konstans által is át lehet adni:
| double szam =
3.1416; unsigned int hossz = 8, pontossag = 4; printf("%*.2f", hossz, szam); // 3.14 printf("%.*f", pontossag, szam); //3.1416 printf("%*.*f", hossz, pontossag, szam); // 3.1416 |
%[jelzők][szélesség][.pontosság][hossz]típus
Miután kialakítottuk a megfelelő elrendezést, a kész értéket még módosíthatjuk néhány jelzővel:
| - | A kívánt szélességet nem jobbra igazítással fogja elérni, hanem balra igazítással. A plusz karakterek nem a szöveg elé, hanem után fognak kerülni. |
| + | Kiváltja az előjelek minden esetben történő kiírását. Alapesetben csak a negatív előjel kerül kiírásra, de ennek hatására a pozitív is ki lesz írva. |
| # | Hatására a számok a C/C++
programozás során használt
pontos alakját kapjuk meg. Ha o, x vagy X típusjelzőt használunk a szám elé fog kerülni a programozás során szükséges 0, 0x illetve 0X szöveg is, ha a szám nem nulla (más számrendszernél kellenek ezek, pl. int i = 0xF7;). Ha a, A, e, E, f, F, g vagy G típusjelzőt használunk, kiváltja a tizedesjel kiírását még akkor is ha az egész rész után, már nincs tizedes szám. (ha egy konstansról szeretnénk hogy valós legyen, akkor is ki kell írni a pontot - ha nincs tizedesrész pl. float f = i / 3.;) |
| 0 | A kívánt szélességet szóközök helyett nullákkal fogja elérni. |
Példák:
| double f =
3.1416; int i = 8, j = 4; printf("%#*.2x", i, j); // 0x4 printf("%08d", i); //00000008 printf("%+*.*f", i, j, f); // +3.1416 |
5d, A vezérlőkarakterek
Mint erről már korábban szó esett, a karakterek megadhatóak sorszámaik által is - ha ismerjük a megfelelő kódlapot., pl.:
| char c = 'A', d = '\101'; //65 nyolcas számrendszerben = 101 |
A vezérlőkarakterek, azok a karakterek, amelyeknek fontos szerepük van (pl. sortörés, tabulátor, ...), saját karakterkóddal rendelkeznek - de megjelenítendő képpel nem - általában az operációs rendszerre hatnak, ami hatásukra különböző feladatokat végezhet el (pl. program leállítása, fájl lezárása, stb...).
Léteznek olyan elnevezések, amelyek nevezetes vezérlőkaraktereket látnak el névvel, mint a tabulátor, a sortörés, vagy a hangjelzés. Jellemzőjük hogy mindig \ jellel kezdődnek a C/C++ alatt.
Megjegyzés: Míg a helyettesítésnek csak a printf/scanf esetén van értelme, vezérlőkaraktereket bármikor alkalmazhatunk - pl:
| puts("Ez\negy\ntobbsoros\nszoveg."); /* Ez egy tobbsoros szoveg. */ |
Íme néhány vezérlőkarakter a teljesség igénye nélkül (a teljes lista itt megtalálható):
| jelölés |
tizenhatos szr. alak |
rövidítés | angol név | a karakter leírása | billenytű(k) |
|---|---|---|---|---|---|
| \a | 0x07 | BEL | bell, alarm | hangjelzés | |
| \b | 0x08 | BS | Backspace |
 |
|
| \f | 0x0C | FF | form feed | laptörés |
 + +
 |
| \n | 0x0A | LF | line feed | sortörés |
 |
| \r | 0x0D | CR | carriage return | "kocsi vissza" | |
| \t | 0x09 | HT | horizontal tab | vízszintes tabulátor |
 |
| \v | 0x0B | VT | vertical tab | függőleges tabulátor |
+
 |
| \\ | 0x5C | backslash | balra dőlő törésjel |
 + +
 |
|
| \' | 0x27 | single comma | egyszeres idézőjel |
 + +
 |
|
| \" | 0x22 | double comma | kétszeres idézőjel |
+
 |
|
| \? | 0x3F | question mark | kérdőjel |
+
 |
|
| \0 | 0x00 | NUL | null | szöveg zárókaraktere | |
| \e | 0x1B | ESC | Escape |
 |
|
| \177 | 0x7F | DEL | Delete |
 |
|
| \4 | 0x04 | EOT | end-of-transmission | átvitel vége jel |
+
 |
| \32 | 0x1A | EOF | end-of-file | fájl vége jel |
+
 |
| \3 | 0x03 | ETX / SIGINT | end-of-text / interruption signal | szöveg vége / megszakítási jel |
+
 |
| \nnn | bármilyen | a karakter sorszáma nyolcas számrendszerben megadva | |||
| \xhh… | bármilyen | a karakter sorszáma tizenhatos számrendszerben megadva | |||
A hangjelzés karakter régi programokban sípolást adott ki a belső hangszórón, míg ma az operációs rendszer standard hangjelzéseinek egyikét használja fel.
A backspace karakter az előtte álló karaktert törli.
A laptörés karakter a nyomtatót arra utasítja hogy hagyja abba a nyomtatást, és dobja ki a lapot, húzza be a következőt - míg szöveges módú alkalmazásokban törli a képernyőt.
A Microsoft rendszerek a CR/LF billentyűt használják az <ENTER> lenyomása után, míg Unix alapú rendszerekben (pl. Linux), ez csak önállóan a LF lesz. További információ visszább.
A vízszintes tabulátor a billentyűzet bal oldalán van, a kód tagolásában gyakori - a függőleges legtöbb esetben nem működik.
A backslash karakter azért kapott külön kódot, mert amint látható, igénybe van véve a vezérlőkarakterek kiírásához.
Az egyszeres idézőjel használatához nem szükséges a speciális jel, de a dupláéhoz igen - mivel ez jelöli a szöveges konstans elejét/végét.
A kérdőjel karakter is simán használható a jele nélkül.
A null karakter nem adható meg máshogy, csak így, mint erről már szó esett - ez a szöveg zárókaraktere.
Az escape karakternek a régi rendszerekben speciális jelentése volt, segítségével escape szekvenciák vitelezhetőek ki, amikkel a rendszer parancsokat kap - pl.:
| puts("\e1;31m"); |
Ez a sor MS-DOS alatt, ha be van töltve az ANSI.SYS illesztőprogram is, a szöveget pirosra - a hátteret feketére állítja. Windows alatt ezt függvényhívással lehet elérni, a SetConsoleTextAttribute utasítás által.
A DEL billentyű a mögötte álló karaktert törli.
Az EOT jel Unix alapú rendszerekben fontos, itt pl. a kijelentkezéshez, egy folyamat végének a jelzéséhez szükséges a használata. Billentyűje: Ctrl+D
Az EOF jel jelzi a fájl végét - vagy mint korábban láthattuk csatornákkal operáló parancsok esetén, visszatérési értékekben a hibát. A C/C++ esetén létezik egy EOF konstans is, nem kell a jelét használni. Billentyűje: Ctrl+Z
Az ETX/SIGINT jel megszakítja az aktuális program futását szöveges módban. Billentyűje: Ctrl+C
Természetesen ha egy külső táblázatban találjuk meg a kívánt karakter kódját - nyolcas ill. tizenhatos szr.-be átváltva használható is - még ha nem is tudjuk begépelni konstansként (mint az Ctrl+C-t pl.).
5e, A printf, és változatai
int
printf(const
char* format, const
változó1, ... , const
változóN)
int fprintf(FILE*
dest, const
char* format,
const változó1, ... ,
const változóN)
int snprintf(char*
str, unsigned int
length,
char*
format, const
változó1, ... , const
változóN)
Egy formátumsztringet megfelelő helyettesítés után kiír az adott helyre.
format: Maga a formátumsztring. (lásd
visszább)
dest: Az a csatorna, amire kérjük a kiírást.
str: Az a karakterlánc, amibe kérjük a kiírást.
length: A megadott karakterláncban lévő hely - legfeljebb hány
karaktert tud tárolni.
változó1 ... változóN: Azok a változók amiket be kell
helyettesíteni a formátumsztringbe.
A visszatérési érték a kiírt karakterek száma, hiba esetén negatív szám.
A több változat több lehetőséget biztosít:
- Az első verzió továbbra is arra van, amire eddig használtuk - képernyőre írás
- A másodiknak akkor van szerepe, ha más csatornára szeretnénk írni, pl. stderr
- A harmadiknak akkor van szerepe, ha az eredményt nem akarjuk most kiírni, netán további műveleteket szeretnénk végezni velük (egy kevésbé biztonságos változata az sprintf - a gets-nél leírt túlírás előfordulhat nála)
Példák:
| printf("%+.2f\n%08.3f",
3.1416,
2.7681); /* +3.14 0002.768 */ short short int c = 126; fprintf(stderr, "Hiba tortént, hibakod: %08hhx", c); //Hiba tortént, hibakod: 000000F6 char szoveg[50]; snprintf(szoveg, 50, "A pi erteke: %.2f", 3.1416); puts(szoveg); //A pi erteke: 3.14 |
5f, A scanf és változatai
int
scanf(const
char* format, const*
változó1, ... , const*
változóN)
int fscanf(FILE*
dest, const
char* format,
const* változó1, ... ,
const* változóN)
int sscanf(char*
str, const
char* format,
const* változó1, ... ,
const* változóN)
Egy formátumsztringet értelmezve, kiolvas belőle egy vagy több változót - a megfelelő konverziókat automatikusan elvégezve.
format: Maga a formátumsztring. (lásd
visszább)
dest: Az a csatorna, amiből olvassuk a adatokat.
str: Az a karakterlánc, amiből olvassuk az adatokat.
változó1 ... változóN: Azon változók címe, amiket ki kell
szedni a forrásból, a formátumsztring szerint. (mivel itt címszerinti átadás
történik, ne hagyjuk le az & jelet, kivéve tömbök esetén)
A visszatérési érték a feltöltött változók száma (lehet kevesebb is mint amennyi meg lett adva), hiba esetén EOF.
Fontos:
A zárókarakter hiánya összeomlaszthatja a programot, ezen függvények
hívásakor.
A több változat itt is több lehetőséget ad, a variációk ugyanazok - itt most nincs length paraméter, mert a zárókarakter megadja a szöveg végét.
Példa:
| long int d; fscanf(stdin, "%ld", &i); |
A scanf ugyanakkor ennél sokkal többet is tud - szövegrészletek értelmezését is el tudja végezni.
Példa (dátum beolvasása):
| int ev, honap,
nap; scanf("%d.%d.%d", &ev, &honap, &nap); |
Példa (szöveg értelmezése):
| char
mondat[] =
"Rudolf 12 eves."; char szoveg[20]; int ev; sscanf(mondat, "%s %d", szoveg, &ev); printf("%d eves most %s.", ev, szoveg) |
Az fscanf-re megfelelő példa majd a fájlkezelésnél lesz, ahol csatornának megadható a fájl - most az egyetlen ismert input csatorna az stdin.
Fontos:
Az scanf változatok, alkalmasak több változó bekérésére, de
csak egy adott alakú kifejezésből. Ha olyan bekérést szeretnénk megvalósítani
mint az első C programnál (téglalapos példa), akkor ismételt hívásokra lesz
szükség mindig.
6, A C++ egyszerűsítései
Természetesen ezen a duón még lehet fejleszteni használhatóságon - meg is tették.
6a, A C++ szövegkezelése - std::string
Mivel a karaktertömb nem biztonságos, bevezették a std::string objektumot. Ez hasonló az std::vector objektumhoz, de kifejezetten szövegekhez van elkészítve. Használatához kell a string függvénytár.
Egy ilyen változó felvétele:
std::string szoveg;
std::string szoveg2("Hello vilag!");
Az egyik előnye ennek a típusnak, hogy szemben az alap tömbbel, működik rajta az operátorok egy része.
std::string szoveg3 = "Teszt " + szoveg2; //Teszt Hello vilag!
szoveg3 += endl; //Teszt Hello vilag!\n
Ez a sor pl. összefűzi a két szöveget - alapesetben ez csak az strcat által lenne kivitelezhető, vagy még bonyolultabban.
Az összehasonlítás is ki van vitelezve, bármikor összehasonlíthatjuk egy hagyományos konstanssal:
if (szoveg2 == "Teszt szoveg") { ... }
A hosszának a lekérdezése is sokkal egyszerűbb:
int i =
szoveg2.length();
int j =
szoveg2.size();
A két utasítás egyenértékű.
Az egyes elemek elérése a megszokott módon történhet:
szoveg2[0] = 'B'; //Bello vilag!
Az elemek elrendezéséből adódóan bármikor átalakítható sima karakterlánccá:
char* sz = &szoveg2[0];
A megszokott elérés miatt nem kell módosítani a régi for ciklusokat, de lehet ha úgy gondoljuk - íme mindkét változat (szerintem az újabb bonyolultabb):
|
#include <string> int main() { std::string sz("Hello vilag!"); int i; for (i = 0; i < sz.length(); i++) sz[i] = 'A'; return 0; } #include <string> int main() { std::string sz("Hello vilag!"); std::string::iterator i; for (i = sz.begin(); i != sz.end(); i++) (*sz[i]) = 'A'; return 0; } |
Ennek ellenére mégis szokni kell az új for ciklust az új lehetőségek eléréséhez mint a keresés:
| #include <string> int main() { std::string sz("Ez egy teszt szoveg, tele egy nehany egy szoval."); int i, darab; for (i = sz.find("egy"); i != sz::npos; i = sz.find("egy", i)) { darab++; i++; } return 0; } |
Ha egy szövegrészlet kivágása lenne a célunk, használhatjuk a substr utasítást is:
std::string abece =
"abcdefghijklmnopqrstuvwxyz";
std::string elso_tiz_betu = abece.substr(abc,
10); //abcdefghij
Szintén lehetőség van a kivágásra is, mint az std::vector esetén:
abece.erase(10, 5); //abcdefghijpqrstuvwxyz
Illetve beszúrásra is:
abece.insert(10, "klmno"); //abcdefghijklmnopqrstuvwxyz
Többet az strdupra sincs szükség, a stringek értékadásakor egyből másolás történik:
elso_tiz_betu = abece;
elso_tiz_betu[0] =
'A';
/*
abece == "abcdefghijklmnopqrstuvwxyz"
elso_tiz_betu == "Abcdefghijklmnopqrstuvwxyz"
*/
Ha pedig nem megfelelő hogy a string char típusokból áll készíthetünk egyedi string típust is:
std::basic_string<wchar_t> nemzetkozi_szoveg(L"Привет, мир!");
A C++ sztringkezelése azért nagy dobás mert sokat egyszerűsít a karakterláncos bohóckodáson, de emellett teljesen védett - pl. nem kell odafigyelni a zárókarakterre mert önmaga kezeli, az strdup használatát sem kell elsajátítani ahhoz hogy a szöveget lemásoljuk, stb.
6b, A C++ csatornakezelése - std::cin, std::cout, ...
A C++ a csatornákat egy rugalmasabb módon kezeli, ám ehhez használnunk kell az iostream függvénytárat.
Ez a függvénytár bevezet négy új változót:
- std::cin ~ stdin
- std::cout ~ stdout
- std::cerr ~ stderr
- std::clog
és ezek Unicode változatait:
- std::wcin
- std::wcout
- std::wcerr
- std::wclog
A csatornák használatához csak az parancssori átirányítás operátort kell használnunk:
| #include <iostream> int main() { std::cout << "Hello vilag!\n"; std::cout << 3.1416; std::cout << "Ez egy mondat" << ", ami tobb reszbol" << " all.\n"; int i = 5; std::cout << "Az i szam erteke: " << i << endl; //endl == "\n" return 0; } |
A beolvasáshoz csak meg kell fordítani az operátort:
| #include <iostream> using namespace std; //nagyon fontos, ezért int main() { int a_oldal, b_oldal; cout << "Teglalap jellemzoinek szamitasa\n\n"; cout << "Kerem az 'a' oldalt: "; cin >> a_oldal; cout << "Kerem a 'b' oldalt: "; cin >> b_oldal; cout << "A teglalap kerulete " << 2 * (a_oldal + b_oldal) << "\nA teglalap terulete: " << a_oldal * b_oldal << endl; return 0; } |
Az std::cin több változót is ki tud olvasni egymás után, ha közte nem kell semmit kiírni: std::cin >> a >> b;
A std::cin által szöveget is be lehet olvasni:
string
szoveg;
std::cin >> szoveg;
Ez a megoldás csak szavak beolvasására alkalmas. Egy teljes sor beolvasásához a getline(<csatorna>, <cél>) eljárás kell:
| #include <iostream> #include <string> using namespace std; int main() { string sz; cout << "Kerek egy szoveget: "; getline(cin, sz); return 0; } |
Ez a megoldás nagyon jelentős, nem kell előre megadni a méretét a szövegnek, így nagyon hatékony és dinamikus.
Ha pl. egy tabulátorig szeretnénk csak olvasni, az is megtehető:
getline(std::cin, sz, "\t");
Az egyéb változók és szövegek közötti konverzió is leegyszerűsödött az std::stringstream által (sstream függvénytár):
| #include <iostream> #include <string> #include <sstream> using namespace std; int main() { string sz; int szam; cout << "Kerek egy szamot: "; getline(cin, sz); stringstream(sz) >> szam; return 0; } |
Ez akkor jó, ha az értéket nem beolvassuk, hanem a memóriában van egy karakterlánc formájában, és csak át kell alakítani.
A csatornakezelés és a sztringkezelés a C++ alatt együtt nagyon hatékony - és ami a legjobb hogy végig védettek maradunk, pl. a túlindexelés, a túlírás, a zárókarakter hiánya, a mutatók másolása, stb. csúnya dolgoktól - amikkel a sima C alatt számolnunk kell.