|
|
Table of Contents |
|
1.1 Modern Computing and the Role of ClustersBecause of the expanding role that clusters are playing in distributed computing, it is worth considering this question briefly. There is a great deal of ambiguity, and the terms used to describe clusters and distributed computing are often used inconsistently. This chapter doesn't provide a detailed taxonomy-it doesn't include a discussion of Flynn's taxonomy or of cluster topologies. This has been done quite well a number of times and too much of it would be irrelevant to the purpose of this book. However, this chapter does try to explain the language used. If you need more general information, see the Appendix A for other sources. High Performance Computing, Second Edition (O'Reilly), by Dowd and Severance is a particularly readable introduction. When computing, there are three basic approaches to improving performance-use a better algorithm, use a faster computer, or divide the calculation among multiple computers. A very common analogy is that of a horse-drawn cart. You can lighten the load, you can get a bigger horse, or you can get a team of horses. (We'll ignore the option of going into therapy and learning to live with what you have.) Let's look briefly at each of these approaches. First, consider what you are trying to calculate. All too often, improvements in computing hardware are taken as a license to use less efficient algorithms, to write sloppy programs, or to perform meaningless or redundant calculations rather than carefully defining the problem. Selecting appropriate algorithms is a key way to eliminate instructions and speed up a calculation. The quickest way to finish a task is to skip it altogether. If you need only a modest improvement in performance, then buying a faster computer may solve your problems, provided you can find something you can afford. But just as there is a limit on how big a horse you can buy, there are limits on the computers you can buy. You can expect rapidly diminishing returns when buying faster computers. While there are no hard and fast rules, it is not unusual to see a quadratic increase in cost with a linear increase in performance, particularly as you move away from commodity technology. The third approach is parallelism, i.e., executing instructions simultaneously. There are a variety of ways to achieve this. At one end of the spectrum, parallelism can be integrated into the architecture of a single CPU (which brings us back to buying the best computer you can afford). At the other end of the spectrum, you may be able to divide the computation up among different computers on a network, each computer working on a part of the calculation, all working at the same time. This book is about that approach-harnessing a team of horses. 1.1.1 Uniprocessor ComputersThe traditional classification of computers based on size and performance, i.e., classifying computers as microcomputers, workstations, minicomputers, mainframes, and supercomputers, has become obsolete. The ever-changing capabilities of computers means that today's microcomputers now outperform the mainframes of the not-too-distant past. Furthermore, this traditional classification scheme does not readily extend to parallel systems and clusters. Nonetheless, it is worth looking briefly at the capabilities and problems associated with more traditional computers, since these will be used to assemble clusters. If you are working with a team of horses, it is helpful to know something about a horse. Regardless of where we place them in the traditional classification, most computers today are based on an architecture often attributed to the Hungarian mathematician John von Neumann. The basic structure of a von Neumann computer is a CPU connected to memory by a communications channel or bus. Instructions and data are stored in memory and are moved to and from the CPU across the bus. The overall speed of a computer depends on both the speed at which its CPU can execute individual instructions and the overhead involved in moving instructions and data between memory and the CPU. Several technologies are currently used to speed up the processing speed of CPUs. The development of reduced instruction set computer (RISC) architectures and post-RISC architectures has led to more uniform instruction sets. This eliminates cycles from some instructions and allows a higher clock-rate. The use of RISC technology and the steady increase in chip densities provide great benefits in CPU speed. Superscalar architectures and pipelining have also increased processor speeds. Superscalar architectures execute two or more instructions simultaneously. For example, an addition and a multiplication instruction, which use different parts of the CPU, might be executed at the same time. Pipelining overlaps the different phase of instruction execution like an assembly line. For example, while one instruction is executed, the next instruction can be fetched from memory or the results from the previous instructions can be stored. Memory bandwidth, basically the rate at which bits are transferred from memory over the bus, is a different story. Improvements in memory bandwidth have not kept up with CPU improvements. It doesn't matter how fast the CPU is theoretically capable of running if you can't get instructions and data into or out of the CPU fast enough to keep the CPU busy. Consequently, memory access has created a performance bottleneck for the classical von Neumann architecture: the von Neumann bottleneck. Computer architects and manufacturers have developed a number of techniques to minimize the impact of this bottleneck. Computers use a hierarchy of memory technology to improve overall performance while minimizing cost. Frequently used data is placed in very fast cache memory, while less frequently used data is placed in slower but cheaper memory. Another alternative is to use multiple processors so that memory operations are spread among the processors. If each processor has its own memory and its own bus, all the processors can access their own memory simultaneously. 1.1.2 Multiple ProcessorsTraditionally, supercomputers have been pipelined, superscalar processors with a single CPU. These are the "big iron" of the past, often requiring "forklift upgrades" and multiton air conditioners to prevent them from melting from the heat they generate. In recent years we have come to augment that definition to include parallel computers with hundreds or thousands of CPUs, otherwise known as multiprocessor computers. Multiprocessor computers fall into two basic categories-centralized multiprocessors (or single enclosure multiprocessors) and multicomputers. 1.1.2.1 Centralized multiprocessorsWith centralized multiprocessors, there are two architectural approaches based on how memory is managed-uniform memory access (UMA) and nonuniform memory access (NUMA) machines. With UMA machines, also called symmetric multiprocessors (SMP), there is a common shared memory. Identical memory addresses map, regardless of the CPU, to the same location in physical memory. Main memory is equally accessible to all CPUs, as shown in Figure 1-1. To improve memory performance, each processor has its own cache. Figure 1-1. UMA architecture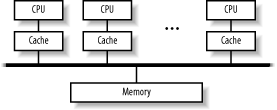 There are two closely related difficulties when designing a UMA machine. The first problem is synchronization. Communications among processes and access to peripherals must be coordinated to avoid conflicts. The second problem is cache consistency. If two different CPUs are accessing the same location in memory and one CPU changes the value stored in that location, then how is the cache entry for the other CPU updated? While several techniques are available, the most common is snooping. With snooping, each cache listens to all memory accesses. If a cache contains a memory address that is being written to in main memory, the cache updates its copy of the data to remain consistent with main memory. A closely related architecture is used with NUMA machines. Roughly, with this architecture, each CPU maintains its own piece of memory, as shown in Figure 1-2. Effectively, memory is divided among the processors, but each process has access to all the memory. Each individual memory address, regardless of the processor, still references the same location in memory. Memory access is nonuniform in the sense that some parts of memory will appear to be much slower than other parts of memory since the bank of memory "closest" to a processor can be accessed more quickly by that processor. While this memory arrangement can simplify synchronization, the problem of memory coherency increases. Figure 1-2. NUMA architecture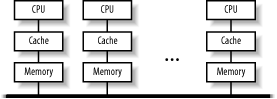 Operating system support is required with either multiprocessor scheme. Fortunately, most modern operating systems, including Linux, provide support for SMP systems, and support is improving for NUMA architectures. When dividing a calculation among processors, an important concern is granularity, or the smallest piece that a computation can be broken into for purposes of sharing among different CPUs. Architectures that allow smaller pieces of code to be shared are said to have a finer granularity (as opposed to a coarser granularity). The granularity of each of these architectures is the thread. That is, the operating system can place different threads from the same process on different processors. Of course, this implies that, if your computation generates only a single thread, then that thread can't be shared between processors but must run on a single CPU. If the operating system has nothing else for the other processors to do, they will remain idle and you will see no benefit from having multiple processors. A third architecture worth mentioning in passing is processor array, which, at one time, generated a lot of interest. A processor array is a type of vector computer built with a collection of identical, synchronized processing elements. Each processor executes the same instruction on a different element in a data array. Numerous issues have arisen with respect to processor arrays. While some problems map nicely to this architecture, most problems do not. This severely limits the general use of processor arrays. The overall design doesn't work well for problems with large serial components. Processor arrays are typically designed around custom VLSI processors, resulting in much higher costs when compared to more commodity-oriented multiprocessor designs. Furthermore, processor arrays typically are single user, adding to the inherent cost of the system. For these and other reasons, processor arrays are no longer popular. 1.1.2.2 MulticomputersA multicomputer configuration, or cluster, is a group of computers that work together. A cluster has three basic elements-a collection of individual computers, a network connecting those computers, and software that enables a computer to share work among the other computers via the network. For most people, the most likely thing to come to mind when speaking of multicomputers is a Beowulf cluster. Thomas Sterling and Don Becker at NASA's Goddard Space Flight Center built a parallel computer out of commodity hardware and freely available software in 1994 and named their system Beowulf.[1] While this is perhaps the best-known type of multicomputer, a number of variants now exist.
First, both commercial multicomputers and commodity clusters are available. Commodity clusters, including Beowulf clusters, are constructed using commodity, off-the-shelf (COTS) computers and hardware. When constructing a commodity cluster, the norm is to use freely available, open source software. This translates into an extremely low cost that allows people to build a cluster when the alternatives are just too expensive. For example, the "Big Mac" cluster built by Virginia Polytechnic Institute and State University was initially built using 1100 dual-processor Macintosh G5 PCs. It achieved speeds on the order of 10 teraflops, making it one of the fastest supercomputers in existence. But while supercomputers in that class usually take a couple of years to construct and cost in the range of $100 million to $250 million, Big Mac was put together in about a month and at a cost of just over $5 million. (A list of the fastest machines can be found at http://www.top500.org. The site also maintains a list of the top 500 clusters.) In commodity clusters, the software is often mix-and-match. It is not unusual for the processors to be significantly faster than the network. The computers within a cluster can be dedicated to that cluster or can be standalone computers that dynamically join and leave the cluster. Typically, the term Beowulf is used to describe a cluster of dedicated computers, often with minimal hardware. If no one is going to use a node as a standalone machine, there is no need for that node to have a dedicated keyboard, mouse, video card, or monitor. Node computers may or may not have individual disk drives. (Beowulf is a politically charged term that is avoided in this book.) While a commodity cluster may consist of identical, high-performance computers purchased specifically for the cluster, they are often a collection of recycled cast-off computers, or a pile-of-PCs (POP). Commercial clusters often use proprietary computers and software. For example, a SUN Ultra is not generally thought of as a COTS computer, so an Ultra cluster would typically be described as a proprietary cluster. With proprietary clusters, the software is often tightly integrated into the system, and the CPU performance and network performance are well matched. The primary disadvantage of commercial clusters is, as you no doubt guessed, their cost. But if money is not a concern, then IBM, Sun Microsystems, or any number of other companies will be happy to put together a cluster for you. (The salesman will probably even take you to lunch.) A network of workstations (NOW), sometimes called a cluster of workstations (COW), is a cluster composed of computers usable as individual workstations. A computer laboratory at a university might become a NOW on the weekend when the laboratory is closed. Or office machines might join a cluster in the evening after the daytime users leave. Software is an integral part of any cluster. A discussion of cluster software will constitute the bulk of this book. Support for clustering can be built directly into the operating system or may sit above the operating system at the application level, often in user space. Typically, when clustering support is part of the operating system, all nodes in the cluster need to have identical or nearly identical kernels; this is called a single system image (SSI). At best, the granularity is the process. With some software, you may need to run distinct programs on each node, resulting in even coarser granularity. Since each computer in a cluster has its own memory (unlike a UMA or NUMA computer), identical addresses on individual CPUs map different physical memory locations. Communication is more involved and costly. 1.1.2.3 Cluster structureIt's tempting to think of a cluster as just a bunch of interconnected machines, but when you begin constructing a cluster, you'll need to give some thought to the internal structure of the cluster. This will involve deciding what roles the individual machines will play and what the interconnecting network will look like. The simplest approach is a symmetric cluster. With a symmetric cluster (Figure 1-3) each node can function as an individual computer. This is extremely straightforward to set up. You just create a subnetwork with the individual machines (or simply add the computers to an existing network) and add any cluster-specific software you'll need. You may want to add a server or two depending on your specific needs, but this usually entails little more than adding some additional software to one or two of the nodes. This is the architecture you would typically expect to see in a NOW, where each machine must be independently usable. Figure 1-3. Symmetric clusters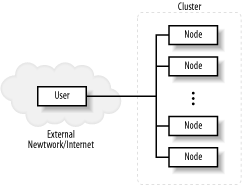 There are several disadvantages to a symmetric cluster. Cluster management and security can be more difficult. Workload distribution can become a problem, making it more difficult to achieve optimal performance. For dedicated clusters, an asymmetric architecture is more common. With asymmetric clusters (Figure 1-4) one computer is the head node or frontend. It serves as a gateway between the remaining nodes and the users. The remaining nodes often have very minimal operating systems and are dedicated exclusively to the cluster. Since all traffic must pass through the head, asymmetric clusters tend to provide a high level of security. If the remaining nodes are physically secure and your users are trusted, you'll only need to harden the head node. Figure 1-4. Asymmetric clusters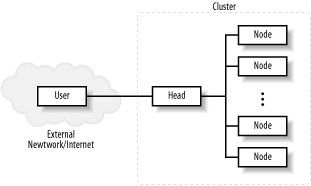 The head often acts as a primary server for the remainder of the clusters. Since, as a dual-homed machine, it will be configured differently from the remaining nodes, it may be easier to keep all customizations on that single machine. This simplifies the installation of the remaining machines. In this book, as with most descriptions of clusters, we will use the term public interface to refer to the network interface directly connected to the external network and the term private interface to refer to the network interface directly connected to the internal network. The primary disadvantage of this architecture comes from the performance limitations imposed by the cluster head. For this reason, a more powerful computer may be used for the head. While beefing up the head may be adequate for small clusters, its limitations will become apparent as the size of the cluster grows. An alternative is to incorporate additional servers within the cluster. For example, one of the nodes might function as an NFS server, a second as a management station that monitors the health of the clusters, and so on. I/O represents a particular challenge. It is often desirable to distribute a shared filesystem across a number of machines within the cluster to allow parallel access. Figure 1-5 shows a more fully specified cluster. Figure 1-5. Expanded cluster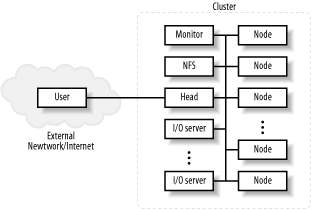 Network design is another key issue. With small clusters, a simple switched network may be adequate. With larger clusters, a fully connected network may be prohibitively expensive. Numerous topologies have been studied to minimize connections (costs) while maintaining viable levels of performance. Examples include hyper-tree, hyper-cube, butterfly, and shuffle-exchange networks. While a discussion of network topology is outside the scope of this book, you should be aware of the issue. Heterogeneous networks are not uncommon. Although not shown in the figure, it may be desirable to locate the I/O servers on a separate parallel network. For example, some clusters have parallel networks allowing administration and user access through a slower network, while communications for processing and access to the I/O servers is done over a high-speed network. |
|
|
Table of Contents |
|