|
|
Table of Contents |
|
15.4 Other ConsiderationsThe issues we have examined up to this point are fairly generic. There are other programming-specific issues that may need to be addressed as well. In this section, we will look very briefly at two of the more common of these-parallel I/O and random numbers. These are both programming tasks that can cause particular problems with parallel programs. You'll need to take care whenever your programs use either of these. In some instances, dealing with these issues may drive program design. 15.4.1 Parallel I/OLarge, computationally expensive problems that require clusters often involve large data sets. Since I/O is always much more costly than computing, dealing with large data sets can severely diminish performance and must be addressed. There are several things you can do to improve I/O performance even before you start programming. First, you should buy adequate I/O hardware. If your cluster will be used for I/O-intensive tasks, you need to pay particular attention when setting up your cluster to ensure you are using fast disks and adequate memory. Next, use a fast filesystem. While NFS may be an easy way to get started with clusters, it is very slow. Other parallel filesystems optimized for parallel performance should be considered, such as PVFS, which is described in Chapter 12. When programming, if memory isn't a problem, it is generally better to make a few large requests rather than a larger number of smaller requests. Design your programs so that I/O is distributed across your processes. Because of historical limitations in parallel I/O systems, it is typical for parallel programs to do I/O from a single process. Ideally, you should use an interface, such as MPI-IO, that spreads I/O across the cluster and has been optimized for parallel I/O. The standard Unix or POSIX filesystem interface for I/O provides relatively poor performance when used in a parallel context, since it does not support collective operations and does not provide noncontiguous access to files. While the original MPI specification avoided the complexities of I/O, the MPI-2 specification dealt with this issue. The MPI-2 specification for parallel I/O (Chapter 9 of the specification) is often known as the MPI-IO. This standard was the joint work of the Scalable I/O Initiative and the MPI-IO Committee through the MPI Forum. ROMIO, from Argonne National Laboratory, is a freely available, portable, high-performance implementation of the MPI-IO standard that runs on a number of different architectures. It is included with MPICH and LAM/MPI and provides interfaces for both C and FORTRAN. MPI-IO provides three types of data access mechanisms-using an explicit offset, using individual file pointers, or using shared file pointers. It also provides support for several different data representations. 15.4.2 MPI-IO FunctionsMPI-IO optimizations include collective I/O, data sieving, and hints. With collective I/O, larger chunks of data are read with a single disk access. The data can then be distributed among the processes as needed. Data sieving is a technique that combines a number of smaller noncontiguous reads into one large read. The system selects and returns the sections requested by the user and discards the rest. While this can improve disk performance, it can put a considerable strain on memory. Hints provide a mechanism to inform the filesystems about a program's data access patterns, e.g., desired caching policies or striping. The following code fragment shows how MPI-IO functions might be used: ...
#define BUFFERSIZE 1000
...
int buffer[BUFFERSIZE];
MPI_File filehandle;
...
MPI_File_open(MPI_COMM_WORLD, "filename", MPI_MODE_RDONLY, MPI_INFO_NULL,
&filehandle);
MPI_File_seek(filehandle, processId*BUFFERSIZE*sizeof(int), MPI_SEEK_SET);
MPI_File_read(filehandle, buffer, BUFFERSIZE, MPI_INT, &status);
MPI_File_close(&filehandle);
...The last four function calls would be executed by each process and, like all MPI functions, would be sandwiched between calls to MPI_Init and MPI_Finalize. In this example, each process opens the file, moves to and reads a block of data from the file, and then closes it. 15.4.2.1 MPI_File_openMPI_File_open is used to open a file. The first argument is the communication group. Every process in the group will open the file. The second argument is the file name. The third argument defines the type of access required to the file. MPI_MODE_RDONLY is read-only access. Nine different modes are supported including MPI_MODE_RDWR (reading and writing), MPI_MODE_WRONLY (write only), MPI_MODE_CREATE (create if it doesn't exist), MPI_MODE_DELETE_ON_CLOSE (delete file when done), and MPI_MODE_APPEND (set the file pointer at the end of the file). C users can use the bit-vector OR (|) to combine these constants. The next to last argument is used to pass hints to the filesystem. The constant MPI_INFO_NULL is used when no hint is available. Using hints does not otherwise change the semantics of the program. (See the MPI-2 documentation for the rather complex details of using hints.) The last argument is the file handle (on type MPI_File), an opaque object used to reference the file once opened. 15.4.2.2 MPI_File_seekThis function is used to position the file pointer. It takes three arguments: the file handle, an offset into the file, and an update mode. There are three update modes: MPI_SEEK_SET (set pointer to offset), MPI_SEEK_CUR (set pointer to current position plus offset), and MPI_SEEK_END (set pointer to end of file plus offset). In this example we have set the pointer to the offset. Notice that processId is used to calculate a different offset into the file for each process. 15.4.2.3 MPI_File_readMPI_File_read allows you to read data from the file specified by the first argument, the file handle. The second argument specifies the address of the buffer, while the third element gives the number of elements in the buffer. The fourth element specifies the type of the data read. The options are the same as with other MPI functions, such as MPI_Send. In this example, we are reading BUFFERSIZE integers into the array at buffer. The last argument is a structure describing the status of read operation. For example, the number of items actually read can be determined from status with the MPI_Get_count function. 15.4.2.4 MPI_File_closeMPI_File_close closes the file referenced by the file handle. The four new functions in this sample example, along with MPI_File_write, are the core functions provided by MPI-IO. However, a large number of other MPI-IO functions are also available. These are described in detail in the MPI-2 documentation. 15.4.3 Random NumbersGenerating random (or pseudorandom) numbers presents a particular problem for parallel programming. Pseudorandom number generators typically produce a stream of "random" numbers where the next random number depends upon previously generated random numbers in some highly nonobvious way.[3] While the numbers appear to be random, and are for most purposes, they are in fact calculated and reproducible provided you start with the same parameters, i.e., at the same point in the stream. By varying the starting parameters, it will appear that you are generating a different stream of random numbers. In fact, you are just starting at different points on the same stream. The period for a random number generator is the number of entries in the stream before the stream starts over again and begins repeating itself. For good random number generators, the periods are quite large and shouldn't create any problems for serial programs using random number generators.
For parallel programs, however, there are some potential risks. For example, if you are using a large number of random numbers on a number of different processors and using the same random number generator on each, then there is a chance that some of the streams will overlap. For some applications, such as parallel Monte Carlo simulations, this is extremely undesirable. There are several ways around this. One approach is to have a single process serve as a random number generator and distribute its random numbers among the remaining processes. Since only a single generator is used, it is straightforward to ensure that no random number is used more than once. The disadvantage to this approach is the communication overhead required to distribute the random numbers. This can be minimized, somewhat, by distributing blocks of random numbers, but this complicates programming since each process must now manage a block of random numbers. An alternative approach is to use the same random number generator in each process but to use different offsets into the stream. For example, if you are using 100 processes, process 0 would use the 1st, 101st, 201st, etc., random numbers in the stream. Process 1 would use the 2nd, 102nd, 202nd, etc., random numbers in the stream, etc. While this eliminates communication overhead, it adds to the complexity of the program. Fortunately, there are libraries of random number generators designed specifically for use with parallel programs. One such library is Scalable Parallel Random Number Generators (SPRNG). This library actually provides six different state-of-the-art random number generators (Table 15-1). SPRNG works nicely with MPI. (You'll need to download and install SPRNG before you can use it. See Chapter 9 for details.)
To give you an idea of how to use SPRNG, we'll look at a simple Monte Carlo simulation that estimates the value of (in case you've forgotten). The way the simulation works is a little like throwing darts. Imagine throwing darts at a dart board with a circle in the center like the one in Figure 15-5. Assuming that you are totally inept, the darts could land anywhere, but ignore those that miss the board completely. If you count the total number of darts thrown (total) and if you count those that land in the circle (in), then for random tosses, you'd expect the ratio in/total to be just the ratio of the area of the circle to the square. If the square is 1 foot on a side, the area of the circle is /4 square feet. Using this information, you can estimate as 4*in/total, i.e., four times the ratio of the area of the circle to the area of the square. Figure 15-5. Monte Carlo dartboard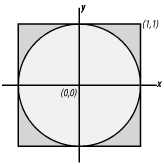 You'll need to throw a lot of darts to get a reasonable estimate. If you know a lot of inept dart enthusiasts, you can recruit them. Each one throws darts and keeps track of their total. If you add the results, you should get a better estimate. The code that follows uses this technique to estimate the value of . Multiple processes are used to provide a larger number of tosses and a better estimate. The code uses SPRNG to generate separate streams of random numbers, one for each process. #include <stdio.h>
#include <math.h>
#include "mpi.h"
#define SIMPLE_SPRNG /* simple interface */
#define USE_MPI /* MPI version of SPRNG */
#include "sprng.h"
main(int argc, char *argv[ ])
{
int i, in, n, noProcesses, processId, seed, total;
double pi;
n = 1000;
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &noProcesses);
MPI_Comm_rank(MPI_COMM_WORLD, &processId);
seed = make_sprng_seed( );
init_sprng(3, seed, SPRNG_DEFAULT);
print_sprng( );
in = hits(n);
MPI_Reduce(&in, &total, 1, MPI_INT, MPI_SUM, 0, MPI_COMM_WORLD);
/* estimate and print pi */
if(processId = = 0)
{ pi = (4.0 * total) / (n * noProcesses);
printf("Pi estimate: %18.16f \n", pi);
printf("Number of samples: %12d \n", n * noProcesses);
}
MPI_Finalize( );
}
/* count darts in target */
int hits(int n)
{
int i, in = 0;
double x, y;
for (i = 0; i < n; i++)
{ x = sprng( );
y = sprng( );
if (x * x + y * y < 1.0) in++;
}
return in;
}For simplicity, this code considers only the top right-hand corner (one-fourth) of the board. But since the board is symmetric, the ratio of the areas is the same. The code simulates randomly throwing darts by generating a pair of random numbers for the coordinates of where the dart might land, and then looks to see if they are within the circle by calculating the distance to the center of the circle.[4] This is done in the function hits.
Apart from the SPRNG code, shown in boldface, everything should look familiar. For MPI programming, before including the SPRNG header file, you need to define two macros. In this example, the macro SIMPLE_SPRNG is used to specify the simple interface, which should be adequate for most needs. The alternative or default interface provides for multiple streams per process. The macro USE_MPI is necessary to let the init_sprng routine make the necessary MPI calls to ensure separate streams for each process. Before generating random numbers, a seed needs to be generated and an initialization routine called. The routine make_sprng_seed generates a seed using time and date information from the system. When used with MPI, it broadcasts the seed to all the processes. init_sprng initializes the random number streams. (This call can be omitted if you want to use the defaults.) The first argument to init_sprng is an integer from 0 to 5 inclusive, specifying which of the random number generators to use. Table 15-1 gives the possibilities. The second argument is the seed, an encoding of the start state for the random number generator, while the third argument is used to pass additional parameters required by some generators. The call to print_sprng, also optional, will provide information about each of the streams as shown in the output below. Finally, to generate random numbers, a double between 0 and 1, the call sprng is used as seen in the hits routine. Here is an example of compiling the code. On this system, SPRNG has been installed in the directory /usr/local/src/sprng2.0. [sloanjd@fanny SPRNG]$ mpicc pi-mpi.c -I/usr/local/src/sprng2.0/include \ > -L/usr/local/src/sprng2.0/lib -lsprng -lm -o pi-mpi Note the inclusion of path and library information. (Look at the Makefile file in the EXAMPLES subdirectory in the installation tree for more hints on compiling.) Here is part of the output for this program. [sloanjd@fanny SPRNG]$ mpirun -np 4 pi-mpi
Combined multiple recursive generator
seed = 88724496, stream_number = 0 parameter = 0
Pi estimate: 3.0930000000000000
Number of samples: 4000
Combined multiple recursive generator
seed = 88724496, stream_number = 2 parameter = 0
...The output for two of the streams is shown. It is similar for the other streams. If rounded, the answer is correct to two places. That's using 4,000 darts. The documentation for SPRNG provides a number of the details glossed over here. And the installation also includes a large number of detailed examples. These two examples, I/O and random numbers, should give you an idea of the types of problems you may encounter when writing parallel code. Dealing with problem areas like these may be critical when determining how your programs should be designed. At other times, performance may hinge on more general issues such as balancing parallelism with overhead. It all depends on the individual problem you face. While good design is essential, often you will need to tweak your design based on empirical measurements. Chapter 17 provides the tools you will need to do this. |
|
|
Table of Contents |
|