4.8 Summary
Table 4.1 summarizes the communication times for various collective communications operations discussed in this chapter. The time for one-to-all broadcast, all-to-one reduction, and the all-reduce operations is the minimum of two expressions. This is because, depending on the message size m, either the algorithms described in Sections 4.1 and 4.3 or the ones described in Section 4.7 are faster. Table 4.1 assumes that the algorithm most suitable for the given message size is chosen. The communication-time expressions in Table 4.1 have been derived in the earlier sections of this chapter in the context of a hypercube interconnection network with cut-through routing. However, these expressions and the corresponding algorithms are valid for any architecture with a Q(p) cross-section bandwidth (Section 2.4.4). In fact, the terms associated with tw for the expressions for all operations listed in Table 4.1, except all-to-all personalized communication and circular shift, would remain unchanged even on ring and mesh networks (or any k-d mesh network) provided that the logical processes are mapped onto the physical nodes of the network appropriately. The last column of Table 4.1 gives the asymptotic cross-section bandwidth required to perform an operation in the time given by the second column of the table, assuming an optimal mapping of processes to nodes. For large messages, only all-to-all personalized communication and circular shift require the full Q(p) cross-section bandwidth. Therefore, as discussed in Section 2.5.1, when applying the expressions for the time of these operations on a network with a smaller cross-section bandwidth, the tw term must reflect the effective bandwidth. For example, the bisection width of a p-node square mesh is Q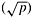 and that of a p-node ring is Q(1). Therefore, while performing all-to-all personalized communication on a square mesh, the effective per-word transfer time would be Q times the tw of individual links, and on a ring, it would be Q(p) times the tw of individual links. and that of a p-node ring is Q(1). Therefore, while performing all-to-all personalized communication on a square mesh, the effective per-word transfer time would be Q times the tw of individual links, and on a ring, it would be Q(p) times the tw of individual links.
Table 4.1. Summary of communication times of various operations discussed in Sections 4.1-4.7 on a hypercube interconnection network. The message size for each operation is m and the number of nodes is p.|
|
One-to-all broadcast,
All-to-one reduction |
min((ts + twm) log p, 2(ts log p + twm)) |
Q(1) | |
All-to-all broadcast,
All-to-all reduction |
ts log p + twm(p - 1) |
Q(1) | |
All-reduce |
min((ts + twm) log p, 2(ts log p + twm)) |
Q(1) | |
Scatter, Gather |
ts log p + twm(p - 1) |
Q(1) | |
All-to-all personalized |
(ts + twm)(p - 1) |
Q(p) | |
Circular shift |
ts + twm |
Q(p) |
Table 4.2. MPI names of the various operations discussed in this chapter.|
|
One-to-all broadcast |
MPI_Bcast | |
All-to-one reduction |
MPI_Reduce | |
All-to-all broadcast |
MPI_Allgather | |
All-to-all reduction |
MPI_Reduce_scatter | |
All-reduce |
MPI_Allreduce | |
Gather |
MPI_Gather | |
Scatter |
MPI_Scatter | |
All-to-all personalized |
MPI_Alltoall |
The collective communications operations discussed in this chapter occur frequently in many parallel algorithms. In order to facilitate speedy and portable design of efficient parallel programs, most parallel computer vendors provide pre-packaged software for performing these collective communications operations. The most commonly used standard API for these operations is known as the Message Passing Interface, or MPI. Table 4.2 gives the names of the MPI functions that correspond to the communications operations described in this chapter.
 |