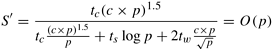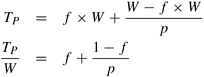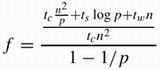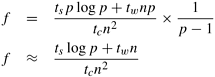|
|
5.7 Other Scalability MetricsA number of other metrics of scalability of parallel systems have been proposed. These metrics are specifically suited to different system requirements. For example, in real time applications, the objective is to scale up a system to accomplish a task in a specified time bound. One such application is multimedia decompression, where MPEG streams must be decompressed at the rate of 25 frames/second. Consequently, a parallel system must decode a single frame in 40 ms (or with buffering, at an average of 1 frame in 40 ms over the buffered frames). Other such applications arise in real-time control, where a control vector must be generated in real-time. Several scalability metrics consider constraints on physical architectures. In many applications, the maximum size of a problem is constrained not by time, efficiency, or underlying models, but by the memory available on the machine. In such cases, metrics make assumptions on the growth function of available memory (with number of processing elements) and estimate how the performance of the parallel system changes with such scaling. In this section, we examine some of the related metrics and how they can be used in various parallel applications. Scaled Speedup This metric is defined as the speedup obtained when the problem size is increased linearly with the number of processing elements. If the scaled-speedup curve is close to linear with respect to the number of processing elements, then the parallel system is considered scalable. This metric is related to isoefficiency if the parallel algorithm under consideration has linear or near-linear isoefficiency function. In this case the scaled-speedup metric provides results very close to those of isoefficiency analysis, and the scaled-speedup is linear or near-linear with respect to the number of processing elements. For parallel systems with much worse isoefficiencies, the results provided by the two metrics may be quite different. In this case, the scaled-speedup versus number of processing elements curve is sublinear. Two generalized notions of scaled speedup have been examined. They differ in the methods by which the problem size is scaled up with the number of processing elements. In one method, the size of the problem is increased to fill the available memory on the parallel computer. The assumption here is that aggregate memory of the system increases with the number of processing elements. In the other method, the size of the problem grows with p subject to an upper-bound on execution time. Example 5.21 Memory and time-constrained scaled speedup for matrix-vector products The serial runtime of multiplying a matrix of dimension n x n with a vector is tcn2, where tc is the time for a single multiply-add operation. The corresponding parallel runtime using a simple parallel algorithm is given by:
and the speedup S is given by:
The total memory requirement of the algorithm is Q(n2). Let us consider the two cases of problem scaling. In the case of memory constrained scaling, we assume that the memory of the parallel system grows linearly with the number of processing elements, i.e., m = Q(p). This is a reasonable assumption for most current parallel platforms. Since m = Q(n2), we have n2 = c x p, for some constant c. Therefore, the scaled speedup S' is given by:
or
In the limiting case, In the case of time constrained scaling, we have TP = O(n2/p). Since this is constrained to be constant, n2 = O(p). We notice that this case is identical to the memory constrained case. This happened because the memory and runtime of the algorithm are asymptotically identical. Example 5.22 Memory and time-constrained scaled speedup for matrix-matrix products The serial runtime of multiplying two matrices of dimension n x n is tcn3, where tc, as before, is the time for a single multiply-add operation. The corresponding parallel runtime using a simple parallel algorithm is given by:
and the speedup S is given by:
The total memory requirement of the algorithm is Q(n2). Let us consider the two cases of problem scaling. In the case of memory constrained scaling, as before, we assume that the memory of the parallel system grows linearly with the number of processing elements, i.e., m = Q(p). Since m = Q(n2), we have n2 = c x p, for some constant c. Therefore, the scaled speedup S' is given by:
In the case of time constrained scaling, we have TP = O(n3/p). Since this is constrained to be constant, n3 = O(p), or n3 = c x p (for some constant c). Therefore, the time-constrained speedup S" is given by:
This example illustrates that memory-constrained scaling yields linear speedup, whereas time-constrained speedup yields sublinear speedup in the case of matrix multiplication. Serial Fraction f The experimentally determined serial fraction f can be used to quantify the performance of a parallel system on a fixed-size problem. Consider a case when the serial runtime of a computation can be divided into a totally parallel and a totally serial component, i.e.,
Here, Tser and Tpar correspond to totally serial and totally parallel components. From this, we can write:
Here, we have assumed that all of the other parallel overheads such as excess computation and communication are captured in the serial component Tser. From these equations, it follows that:
The serial fraction f of a parallel program is defined as:
Therefore, from Equation 5.34, we have:
Since S = W/TP , we have
Solving for f , we get:
It is easy to see that smaller values of f are better since they result in higher efficiencies. If f increases with the number of processing elements, then it is considered as an indicator of rising communication overhead, and thus an indicator of poor scalability. Example 5.23 Serial component of the matrix-vector product From Equations 5.35 and 5.32, we have
Simplifying the above expression, we get
It is useful to note that the denominator of this equation is the serial runtime of the algorithm and the numerator corresponds to the overhead in parallel execution. In addition to these metrics, a number of other metrics of performance have been proposed in the literature. We refer interested readers to the bibliography for references to these. |
|
|