|
|
7.8 Composite Synchronization ConstructsWhile the Pthreads API provides a basic set of synchronization constructs, often, there is a need for higher level constructs. These higher level constructs can be built using basic synchronization constructs. In this section, we look at some of these constructs along with their performance aspects and applications. 7.8.1 Read-Write LocksIn many applications, a data structure is read frequently but written infrequently. For such scenarios, it is useful to note that multiple reads can proceed without any coherence problems. However, writes must be serialized. This points to an alternate structure called a read-write lock. A thread reading a shared data item acquires a read lock on the variable. A read lock is granted when there are other threads that may already have read locks. If there is a write lock on the data (or if there are queued write locks), the thread performs a condition wait. Similarly, if there are multiple threads requesting a write lock, they must perform a condition wait. Using this principle, we design functions for read locks mylib_rwlock_rlock, write locks mylib_rwlock_wlock, and unlocking mylib_rwlock_unlock. The read-write locks illustrated are based on a data structure called mylib_rwlock_t. This structure maintains a count of the number of readers, the writer (a 0/1 integer specifying whether a writer is present), a condition variable readers_proceed that is signaled when readers can proceed, a condition variable writer_proceed that is signaled when one of the writers can proceed, a count pending_writers of pending writers, and a mutex read_write_lock associated with the shared data structure. The function mylib_rwlock_init is used to initialize various components of this data structure. The function mylib rwlock rlock attempts a read lock on the data structure. It checks to see if there is a write lock or pending writers. If so, it performs a condition wait on the condition variable readers proceed, otherwise it increments the count of readers and proceeds to grant a read lock. The function mylib_rwlock_wlock attempts a write lock on the data structure. It checks to see if there are readers or writers; if so, it increments the count of pending writers and performs a condition wait on the condition variable writer_proceed. If there are no readers or writer, it grants a write lock and proceeds. The function mylib_rwlock_unlock unlocks a read or write lock. It checks to see if there is a write lock, and if so, it unlocks the data structure by setting the writer field to 0. If there are readers, it decrements the number of readers readers. If there are no readers left and there are pending writers, it signals one of the writers to proceed (by signaling writer_proceed). If there are no pending writers but there are pending readers, it signals all the reader threads to proceed. The code for initializing and locking/unlocking is as follows:
1 typedef struct {
2 int readers;
3 int writer;
4 pthread_cond_t readers_proceed;
5 pthread_cond_t writer_proceed;
6 int pending_writers;
7 pthread_mutex_t read_write_lock;
8 } mylib_rwlock_t;
9
10
11 void mylib_rwlock_init (mylib_rwlock_t *l) {
12 l -> readers = l -> writer = l -> pending_writers = 0;
13 pthread_mutex_init(&(l -> read_write_lock), NULL);
14 pthread_cond_init(&(l -> readers_proceed), NULL);
15 pthread_cond_init(&(l -> writer_proceed), NULL);
16 }
17
18 void mylib_rwlock_rlock(mylib_rwlock_t *l) {
19 /* if there is a write lock or pending writers, perform condition
20 wait.. else increment count of readers and grant read lock */
21
22 pthread_mutex_lock(&(l -> read_write_lock));
23 while ((l -> pending_writers > 0) || (l -> writer > 0))
24 pthread_cond_wait(&(l -> readers_proceed),
25 &(l -> read_write_lock));
26 l -> readers ++;
27 pthread_mutex_unlock(&(l -> read_write_lock));
28 }
29
30
31 void mylib_rwlock_wlock(mylib_rwlock_t *l) {
32 /* if there are readers or writers, increment pending writers
33 count and wait. On being woken, decrement pending writers
34 count and increment writer count */
35
36 pthread_mutex_lock(&(l -> read_write_lock));
37 while ((l -> writer > 0) || (l -> readers > 0)) {
38 l -> pending_writers ++;
39 pthread_cond_wait(&(l -> writer_proceed),
40 &(l -> read_write_lock));
41 }
42 l -> pending_writers --;
43 l -> writer ++
44 pthread_mutex_unlock(&(l -> read_write_lock));
45 }
46
47
48 void mylib_rwlock_unlock(mylib_rwlock_t *l) {
49 /* if there is a write lock then unlock, else if there are
50 read locks, decrement count of read locks. If the count
51 is 0 and there is a pending writer, let it through, else
52 if there are pending readers, let them all go through */
53
54 pthread_mutex_lock(&(l -> read_write_lock));
55 if (l -> writer > 0)
56 l -> writer = 0;
57 else if (l -> readers > 0)
58 l -> readers --;
59 pthread_mutex_unlock(&(l -> read_write_lock));
60 if ((l -> readers == 0) && (l -> pending_writers > 0))
61 pthread_cond_signal(&(l -> writer_proceed));
62 else if (l -> readers > 0)
63 pthread_cond_broadcast(&(l -> readers_proceed));
64 }
We now illustrate the use of read-write locks with some examples. Example 7.7 Using read-write locks for computing the minimum of a list of numbers A simple use of read-write locks is in computing the minimum of a list of numbers. In our earlier implementation, we associated a lock with the minimum value. Each thread locked this object and updated the minimum value, if necessary. In general, the number of times the value is examined is greater than the number of times it is updated. Therefore, it is beneficial to allow multiple reads using a read lock and write after a write lock only if needed. The corresponding program segment is as follows:
1 void *find_min_rw(void *list_ptr) {
2 int *partial_list_pointer, my_min, i;
3 my_min = MIN_INT;
4 partial_list_pointer = (int *) list_ptr;
5 for (i = 0; i < partial_list_size; i++)
6 if (partial_list_pointer[i] < my_min)
7 my_min = partial_list_pointer[i];
8 /* lock the mutex associated with minimum_value and
9 update the variable as required */
10 mylib_rwlock_rlock(&read_write_lock);
11 if (my_min < minimum_value) {
12 mylib_rwlock_unlock(&read_write_lock);
13 mylib_rwlock_wlock(&read_write_lock);
14 minimum_value = my_min;
15 }
16 /* and unlock the mutex */
17 mylib_rwlock_unlock(&read_write_lock);
18 pthread_exit(0);
19 }
Programming Notes
In this example, each thread computes the minimum element in its partial list. It then attempts a read lock on the lock associated with the global minimum value. If the global minimum value is greater than the locally minimum value (thus requiring an update), the read lock is relinquished and a write lock is sought. Once the write lock has been obtained, the global minimum can be updated. The performance gain obtained from read-write locks is influenced by the number of threads and the number of updates (write locks) required. In the extreme case when the first value of the global minimum is also the true minimum value, no write locks are subsequently sought. In this case, the version using read-write locks performs better. In contrast, if each thread must update the global minimum, the read locks are superfluous and add overhead to the program. Example 7.8 Using read-write locks for implementing hash tables A commonly used operation in applications ranging from database query to state space search is the search of a key in a database. The database is organized as a hash table. In our example, we assume that collisions are handled by chaining colliding entries into linked lists. Each list has a lock associated with it. This lock ensures that lists are not being updated and searched at the same time. We consider two versions of this program: one using mutex locks and one using read-write locks developed in this section. The mutex lock version of the program hashes the key into the table, locks the mutex associated with the table index, and proceeds to search/update within the linked list. The thread function for doing this is as follows:
1 manipulate_hash_table(int entry) {
2 int table_index, found;
3 struct list_entry *node, *new_node;
4
5 table_index = hash(entry);
6 pthread_mutex_lock(&hash_table[table_index].list_lock);
7 found = 0;
8 node = hash_table[table_index].next;
9 while ((node != NULL) && (!found)) {
10 if (node -> value == entry)
11 found = 1;
12 else
13 node = node -> next;
14 }
15 pthread_mutex_unlock(&hash_table[table_index].list_lock);
16 if (found)
17 return(1);
18 else
19 insert_into_hash_table(entry);
20 }
Here, the function insert_into_hash_table must lock hash_table[table_index].list_lock before performing the actual insertion. When a large fraction of the queries are found in the hash table (i.e., they do not need to be inserted), these searches are serialized. It is easy to see that multiple threads can be safely allowed to search the hash table and only updates to the table must be serialized. This can be accomplished using read-write locks. We can rewrite the manipulate_hash table function as follows:
1 manipulate_hash_table(int entry)
2 {
3 int table_index, found;
4 struct list_entry *node, *new_node;
5
6 table_index = hash(entry);
7 mylib_rwlock_rlock(&hash_table[table_index].list_lock);
8 found = 0;
9 node = hash_table[table_index].next;
10 while ((node != NULL) && (!found)) {
11 if (node -> value == entry)
12 found = 1;
13 else
14 node = node -> next;
15 }
16 mylib_rwlock_rlock(&hash_table[table_index].list_lock);
17 if (found)
18 return(1);
19 else
20 insert_into_hash_table(entry);
21 }
Here, the function insert_into_hash_table must first get a write lock on hash_table[table_index].list_lock before performing actual insertion.
Programming Notes
In this example, we assume that the list_lock field has been defined to be of type mylib_rwlock_t and all read-write locks associated with the hash tables have been initialized using the function mylib_rwlock_init. Using mylib rwlock_rlock_instead of a mutex lock allows multiple threads to search respective entries concurrently. Thus, if the number of successful searches outnumber insertions, this formulation is likely to yield better performance. Note that the insert into_hash_table function must be suitably modified to use write locks (instead of mutex locks as before). It is important to identify situations where read-write locks offer advantages over normal locks. Since read-write locks offer no advantage over normal mutexes for writes, they are beneficial only when there are a significant number of read operations. Furthermore, as the critical section becomes larger, read-write locks offer more advantages. This is because the serialization overhead paid by normal mutexes is higher. Finally, since read-write locks rely on condition variables, the underlying thread system must provide fast condition wait, signal, and broadcast functions. It is possible to do a simple analysis to understand the relative merits of read-write locks (Exercise 7.7). 7.8.2 BarriersAn important and often used construct in threaded (as well as other parallel) programs is a barrier. A barrier call is used to hold a thread until all other threads participating in the barrier have reached the barrier. Barriers can be implemented using a counter, a mutex and a condition variable. (They can also be implemented simply using mutexes; however, such implementations suffer from the overhead of busy-wait.) A single integer is used to keep track of the number of threads that have reached the barrier. If the count is less than the total number of threads, the threads execute a condition wait. The last thread entering (and setting the count to the number of threads) wakes up all the threads using a condition broadcast. The code for accomplishing this is as follows:
1 typedef struct {
2 pthread_mutex_t count_lock;
3 pthread_cond_t ok_to_proceed;
4 int count;
5 } mylib_barrier_t;
6
7 void mylib_init_barrier(mylib_barrier_t *b) {
8 b -> count = 0;
9 pthread_mutex_init(&(b -> count_lock), NULL);
10 pthread_cond_init(&(b -> ok_to_proceed), NULL);
11 }
12
13 void mylib_barrier (mylib_barrier_t *b, int num_threads) {
14 pthread_mutex_lock(&(b -> count_lock));
15 b -> count ++;
16 if (b -> count == num_threads) {
17 b -> count = 0;
18 pthread_cond_broadcast(&(b -> ok_to_proceed));
19 }
20 else
21 while (pthread_cond_wait(&(b -> ok_to_proceed),
22 &(b -> count_lock)) != 0);
23 pthread_mutex_unlock(&(b -> count_lock));
24 }
In the above implementation of a barrier, threads enter the barrier and stay until the broadcast signal releases them. The threads are released one by one since the mutex count_lock is passed among them one after the other. The trivial lower bound on execution time of this function is therefore O (n) for n threads. This implementation of a barrier can be speeded up using multiple barrier variables. Let us consider an alternate barrier implementation in which there are n/2 condition variable-mutex pairs for implementing a barrier for n threads. The barrier works as follows: at the first level, threads are paired up and each pair of threads shares a single condition variable-mutex pair. A designated member of the pair waits for both threads to arrive at the pairwise barrier. Once this happens, all the designated members are organized into pairs, and this process continues until there is only one thread. At this point, we know that all threads have reached the barrier point. We must release all threads at this point. However, releasing them requires signaling all n/2 condition variables. We use the same hierarchical strategy for doing this. The designated thread in a pair signals the respective condition variables.
1 typedef struct barrier_node {
2 pthread_mutex_t count_lock;
3 pthread_cond_t ok_to_proceed_up;
4 pthread_cond_t ok_to_proceed_down;
5 int count;
6 } mylib_barrier_t_internal;
7
8 typedef struct barrier_node mylog_logbarrier_t[MAX_THREADS];
9 pthread_t p_threads[MAX_THREADS];
10 pthread_attr_t attr;
11
12 void mylib_init_barrier(mylog_logbarrier_t b) {
13 int i;
14 for (i = 0; i < MAX_THREADS; i++) {
15 b[i].count = 0;
16 pthread_mutex_init(&(b[i].count_lock), NULL);
17 pthread_cond_init(&(b[i].ok_to_proceed_up), NULL);
18 pthread_cond_init(&(b[i].ok_to_proceed_down), NULL);
19 }
20 }
21
22 void mylib_logbarrier (mylog_logbarrier_t b, int num_threads,
23 int thread_id) {
24 int i, base, index;
25 i=2;
26 base = 0;
27
28 do {
29 index = base + thread_id / i;
30 if (thread_id % i == 0) {
31 pthread_mutex_lock(&(b[index].count_lock));
32 b[index].count ++;
33 while (b[index].count < 2)
34 pthread_cond_wait(&(b[index].ok_to_proceed_up),
35 &(b[index].count_lock));
36 pthread_mutex_unlock(&(b[index].count_lock));
37 }
38 else {
39 pthread_mutex_lock(&(b[index].count_lock));
40 b[index].count ++;
41 if (b[index].count == 2)
42 pthread_cond_signal(&(b[index].ok_to_proceed_up));
43 while (pthread_cond_wait(&(b[index].ok_to_proceed_down),
44 &(b[index].count_lock)) != 0);
45 pthread_mutex_unlock(&(b[index].count_lock));
46 break;
47 }
48 base = base + num_threads/i;
49 i=i*2;
50 } while (i <= num_threads);
51 i=i/2;
52 for (; i > 1; i = i / 2) {
53 base = base - num_threads/i;
54 index = base + thread_id / i;
55 pthread_mutex_lock(&(b[index].count_lock));
56 b[index].count = 0;
57 pthread_cond_signal(&(b[index].ok_to_proceed_down));
58 pthread_mutex_unlock(&(b[index].count_lock));
59 }
60 }
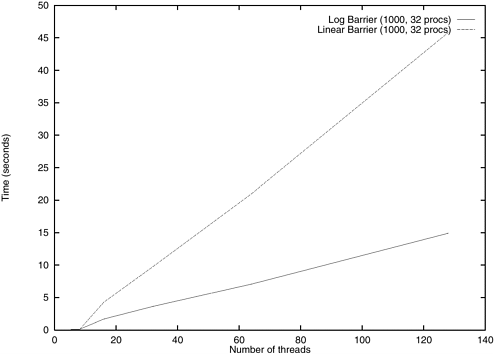
In this implementation of a barrier, we visualize the barrier as a binary tree. Threads arrive at the leaf nodes of this tree. Consider an instance of a barrier with eight threads. Threads 0 and 1 are paired up on a single leaf node. One of these threads is designated as the representative of the pair at the next level in the tree. In the above example, thread 0 is considered the representative and it waits on the condition variable ok_to_proceed_up for thread 1 to catch up. All even numbered threads proceed to the next level in the tree. Now thread 0 is paired up with thread 2 and thread 4 with thread 6. Finally thread 0 and 4 are paired. At this point, thread 0 realizes that all threads have reached the desired barrier point and releases threads by signaling the condition ok_to_proceed_down. When all threads are released, the barrier is complete. It is easy to see that there are n - 1 nodes in the tree for an n thread barrier. Each node corresponds to two condition variables, one for releasing the thread up and one for releasing it down, one lock, and a count of number of threads reaching the node. The tree nodes are linearly laid out in the array mylog_logbarrier_t with the n/2 leaf nodes taking the first n/2 elements, the n/4 tree nodes at the next higher level taking the next n/4 nodes and so on. It is interesting to study the performance of this program. Since threads in the linear barrier are released one after the other, it is reasonable to expect runtime to be linear in the number of threads even on multiple processors. In Figure 7.3, we plot the runtime of 1000 barriers in a sequence on a 32 processor SGI Origin 2000. The linear runtime of the sequential barrier is clearly reflected in the runtime. The logarithmic barrier executing on a single processor does just as much work asymptotically as a sequential barrier (albeit with a higher constant). However, on a parallel machine, in an ideal case when threads are assigned so that subtrees of the binary barrier tree are assigned to different processors, the time grows as O(n/p + log p). While this is difficult to achieve without being able to examine or assign blocks of threads corresponding to subtrees to individual processors, the logarithmic barrier displays significantly better performance than the serial barrier. Its performance tends to be linear in n as n becomes large for a given number of processors. This is because the n/p term starts to dominate the log p term in the execution time. This is observed both from observations as well as from analytical intuition. Figure 7.3. Execution time of 1000 sequential and logarithmic barriers as a function of number of threads on a 32 processor SGI Origin 2000.
|
|
|