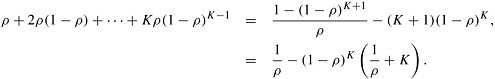|
|
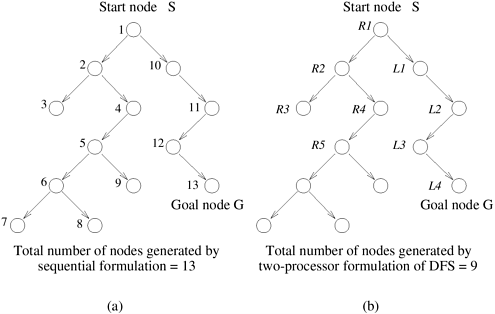
11.6 Speedup Anomalies in Parallel Search AlgorithmsIn parallel search algorithms, speedup can vary greatly from one execution to another because the portions of the search space examined by various processors are determined dynamically and can differ for each execution. Consider the case of sequential and parallel DFS performed on the tree illustrated in Figure 11.17. Figure 11.17(a) illustrates sequential DFS search. The order of node expansions is indicated by node labels. The sequential formulation generates 13 nodes before reaching the goal node G. Figure 11.17. The difference in number of nodes searched by sequential and parallel formulations of DFS. For this example, parallel DFS reaches a goal node after searching fewer nodes than sequential DFS.
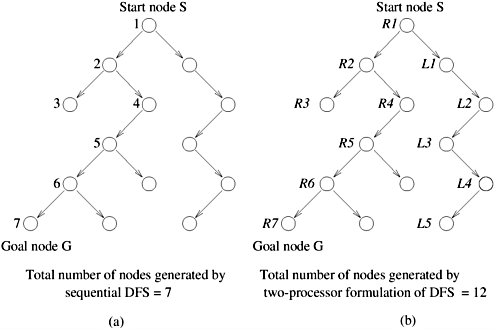
Now consider the parallel formulation of DFS illustrated for the same tree in Figure 11.17(b) for two processors. The nodes expanded by the processors are labeled R and L. The parallel formulation reaches the goal node after generating only nine nodes. That is, the parallel formulation arrives at the goal node after searching fewer nodes than its sequential counterpart. In this case, the search overhead factor is 9/13 (less than one), and if communication overhead is not too large, the speedup will be superlinear. Finally, consider the situation in Figure 11.18. The sequential formulation (Figure 11.18(a)) generates seven nodes before reaching the goal node, but the parallel formulation generates 12 nodes. In this case, the search overhead factor is greater than one, resulting in sublinear speedup. Figure 11.18. A parallel DFS formulation that searches more nodes than its sequential counterpart.
In summary, for some executions, the parallel version finds a solution after generating fewer nodes than the sequential version, making it possible to obtain superlinear speedup. For other executions, the parallel version finds a solution after generating more nodes, resulting in sublinear speedup. Executions yielding speedups greater than p by using p processors are referred to as acceleration anomalies. Speedups of less than p using p processors are called deceleration anomalies. Speedup anomalies also manifest themselves in best-first search algorithms. Here, anomalies are caused by nodes on the open list that have identical heuristic values but require vastly different amounts of search to detect a solution. Assume that two such nodes exist; node A leads rapidly to the goal node, and node B leads nowhere after extensive work. In parallel BFS, both nodes are chosen for expansion by different processors. Consider the relative performance of parallel and sequential BFS. If the sequential algorithm picks node A to expand, it arrives quickly at a goal. However, the parallel algorithm wastes time expanding node B, leading to a deceleration anomaly. In contrast, if the sequential algorithm expands node B, it wastes substantial time before abandoning it in favor of node A. However, the parallel algorithm does not waste as much time on node B, because node A yields a solution quickly, leading to an acceleration anomaly. 11.6.1 Analysis of Average Speedup in Parallel DFSIn isolated executions of parallel search algorithms, the search overhead factor may be equal to one, less than one, or greater than one. It is interesting to know the average value of the search overhead factor. If it is less than one, this implies that the sequential search algorithm is not optimal. In this case, the parallel search algorithm running on a sequential processor (by emulating a parallel processor by using time-slicing) would expand fewer nodes than the sequential algorithm on the average. In this section, we show that for a certain type of search space, the average value of the search overhead factor in parallel DFS is less than one. Hence, if the communication overhead is not too large, then on the average, parallel DFS will provide superlinear speedup for this type of search space. AssumptionsWe make the following assumptions for analyzing speedup anomalies:
Analysis of the Search Overhead FactorConsider the scenario in which the M leaf nodes are statically divided into p regions, each with K = M/p leaves. Let the density of solutions among the leaves in the ith region be ri. In the parallel algorithm, each processor Pi searches region i independently until a processor finds a solution. In the sequential algorithm, the regions are searched in random order.
Theorem 11.6.1 Let r be the solution density in a region; and assume that the number of leaves K in the region is large. Then, if r > 0, the mean number of leaves generated by a single processor searching the region is 1/r. Proof: Since we have a Bernoulli distribution, the mean number of trials is given by
For a fixed value of r and a large value of K, the second term in Equation 11.5 becomes small; hence, the mean number of trials is approximately equal to 1/r. Sequential DFS selects any one of the p regions with probability 1/p and searches it to find a solution. Hence, the average number of leaf nodes expanded by sequential DFS is
This expression assumes that a solution is always found in the selected region; thus, only one region must be searched. However, the probability of region i not having any solutions is (1 - ri)K. In this case, another region must be searched. Taking this into account makes the expression for W more precise and increases the average value of W somewhat. The overall results of the analysis will not change. In each step of parallel DFS, one node from each of the p regions is explored simultaneously. Hence the probability of success in a step of the parallel algorithm is
Inspecting the above equations, we see that W = 1/HM and Wp = 1/AM, where HM is the harmonic mean of r1, r2, ..., rp, and AM is their arithmetic mean. Since the arithmetic mean (AM) and the harmonic mean (HM) satisfy the relation AM
The assumption that each node can be a solution independent of the other nodes being solutions is false for most practical problems. Still, the preceding analysis suggests that parallel DFS obtains higher efficiency than sequential DFS provided that the solutions are not distributed uniformly in the search space and that no information about solution density in various regions is available. This characteristic applies to a variety of problem spaces searched by simple backtracking. The result that the search overhead factor for parallel DFS is at least one on the average is important, since DFS is currently the best known and most practical sequential algorithm used to solve many important problems. |
|
|
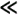 1.
1.