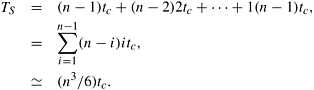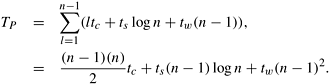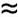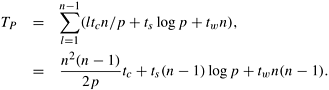|
|
12.5 Nonserial Polyadic DP FormulationsIn nonserial polyadic DP formulations, in addition to processing subproblems at a level in parallel, computation can also be pipelined to increase efficiency. We illustrate this with the optimal matrix-parenthesization problem. 12.5.1 The Optimal Matrix-Parenthesization ProblemConsider the problem of multiplying n matrices, A1, A2, ..., An, where each Ai is a matrix with ri -1 rows and ri columns. The order in which the matrices are multiplied has a significant impact on the total number of operations required to evaluate the product. Example 12.3 Optimal matrix parenthesization Consider three matrices A1, A2, and A3 of dimensions 10 x 20, 20 x 30, and 30 x 40, respectively. The product of these matrices can be computed as (A1 x A2) x A3 or as A1 x (A2 x A3). In (A1 x A2) x A3, computing (A1 x A2) requires 10 x 20 x 30 operations and yields a matrix of dimensions 10 x 30. Multiplying this by A3 requires 10 x 30 x 40 additional operations. Therefore the total number of operations is 10 x 20 x 30 + 10 x 30 x 40 = 18000. Similarly, computing A1 x (A2 x A3) requires 20 x 30 x 40 + 10 x 20 x 40 = 32000 operations. Clearly, the first parenthesization is desirable. The objective of the parenthesization problem is to determine a parenthesization that minimizes the number of operations. Enumerating all possible parenthesizations is not feasible since there are exponentially many of them. Let C [i, j] be the optimal cost of multiplying the matrices Ai ,..., Aj. This chain of matrices can be expressed as a product of two smaller chains, Ai, Ai +1,..., Ak and Ak+1 ,..., Aj. The chain Ai, Ai +1 ,..., Ak results in a matrix of dimensions ri -1 x rk, and the chain Ak+1 ,..., Aj results in a matrix of dimensions rk x rj. The cost of multiplying these two matrices is ri -1rk rj. Hence, the cost of the parenthesization (Ai, Ai +1 ,..., Ak)( Ak+1 ,..., Aj) is given by C [i, k] + C [k + 1, j] + ri -1rk rj. This gives rise to the following recurrence relation for the parenthesization problem:
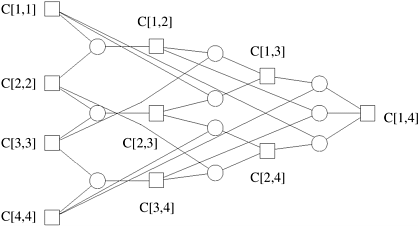
Given Equation 12.7, the problem reduces to finding the value of C [1, n]. The composition of costs of matrix chains is shown in Figure 12.7. Equation 12.7 can be solved if we use a bottom-up approach for constructing the table C that stores the values C [i, j]. The algorithm fills table C in an order corresponding to solving the parenthesization problem on matrix chains of increasing length. Visualize this by thinking of filling in the table diagonally (Figure 12.8). Entries in diagonal l corresponds to the cost of multiplying matrix chains of length l + 1. From Equation 12.7, we can see that the value of C [i, j] is computed as min{C [i, k]+C [k +1, j]+ri -1rk rj}, where k can take values from i to j -1. Therefore, computing C [i, j] requires that we evaluate (j - i) terms and select their minimum. The computation of each term takes time tc, and the computation of C [i, j] takes time (j - i)tc. Thus, each entry in diagonal l can be computed in time ltc. Figure 12.7. A nonserial polyadic DP formulation for finding an optimal matrix parenthesization for a chain of four matrices. A square node represents the optimal cost of multiplying a matrix chain. A circle node represents a possible parenthesization.
Figure 12.8. The diagonal order of computation for the optimal matrix-parenthesization problem.
In computing the cost of the optimal parenthesization sequence, the algorithm computes (n - 1) chains of length two. This takes time (n - 1)tc. Similarly, computing (n - 2) chains of length three takes time (n - 2)2tc. In the final step, the algorithm computes one chain of length n. This takes time (n - 1)tc. Thus, the sequential run time of this algorithm is
The sequential complexity of the algorithm is Q(n3). Consider the parallel formulation of this algorithm on a logical ring of n processing elements. In step l, each processing element computes a single element belonging to the lth diagonal. Processing element Pi computes the (i + 1)th column of Table C. Figure 12.8 illustrates the partitioning of the table among different processing elements. After computing the assigned value of the element in table C, each processing element sends its value to all other processing elements using an all-to-all broadcast (Section 4.2). Therefore, the assigned value in the next iteration can be computed locally. Computing an entry in table C during iteration l takes time ltc because it corresponds to the cost of multiplying a chain of length l + 1. An all-to-all broadcast of a single word on n processing elements takes time ts log n + tw(n - 1) (Section 4.2). The total time required to compute the entries along diagonal l is ltc + ts log n + tw(n - 1). The parallel run time is the sum of the time taken over computation of n - 1 diagonals.
The parallel run time of this algorithm is Q(n2). Since the processor-time product is Q(n3), which is the same as the sequential complexity, this algorithm is cost-optimal. When using p processing elements (1
In order terms, TP = Q(n3/p) + Q(n2). Here, Q(n3/p) is the computation time, and Q(n2) the communication time. If n is sufficiently large with respect to p, communication time can be made an arbitrarily small fraction of computation time, yielding linear speedup. This formulation can use at most Q(n) processing elements to accomplish the task in time Q(n2). This time can be improved by pipelining the computation of the cost C [i, j] on n(n + 1)/2 processing elements. Each processing element computes a single entry c(i, j) of matrix C. Pipelining works due to the nonserial nature of the problem. Computation of an entry on a diagonal t does not depend only on the entries on diagonal t - 1 but also on all the earlier diagonals. Hence work on diagonal t can start even before work on diagonal t - 1 is completed. |
|
|