A database is an organized store of data. Many applications, created in any language, need access to a database. For example, without a database of customers and products, e-commerce applications simply aren't possible.
From the point of view of applications using data in a database, the actual mechanism of storage is usually not important. Whether the data is stored on disk, in memory, or in arrangements of trees on a desert island somewhere, the usage will be the same. What we mean by this is that if an application requests some data concerning a customer and subsequently obtains that data, then where it came from doesn't matter. Of course, performance might be increased if you don't have to keep planting trees....
Three concepts you need to understand before learning about how data is stored in a relational database are entities, attributes, and values. An entity represents some object in reality, such as a person or a product. Entities, as objects, represent a class of "things." A Customers entity describes all possible customers, and then each instance of that object represents a specific customer. Each instance of your Customers entity will have identical attributes that define the meaning of that entity. Consider the following collection of attributes:
Customer first name
Customer last name
Postal address
E-mail address
Phone number
Each of these attributes will store values, and these values are generally different from one Customer instance to another. One Customer instance could store the values Joe, Bloggs, 12 SQL Street, <jbloggs@email.com>, and 012-456-789. Another instance might store completely different values in each attribute.
In the relational database world, roughly speaking, the following is true:
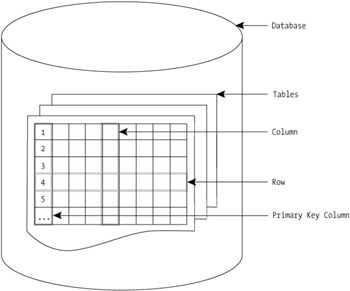
An entity is a table.
An attribute is a column in that table.
A row describes a particular instance of the entity (it contains values for the various columns that comprise the table).
The fundamental data storage unit in a relational database is the table. A single database contains one or more tables. Tables are used to group related data into a single, named unit. For example, an e-commerce application will need to keep track of customers and products. To cater to this, you could use two separate tables, perhaps one called Customers and one called Products, which store relevant information with regard to each entity.
| Note |
There's a general disagreement in the programming community concerning whether table names should have plural names. We tend to think they should be because they're likely to contain multiple data entries, but others have told us they like referring to, say, "the Customer table" because it sounds better. Quite honestly, though, you shouldn't worry about any of this too much as long as the name you choose relates to the table content in a reasonably sensible way. |
Obviously, tables require more than just a name before you can store data in them. What data can and can't go into a table, and in what form it's stored, is defined by the schema information for the table. A database will typically include a single schema defining all the tables it contains, including information concerning columns and data types as described next, relationships between tables, and so on. Schemas are usually stored in the RDBMS in some proprietary format, which is fine because you're unlikely to want to manipulate table schemas directly. Instead, higher-level modifications to table structure will be reflected in schema changes.
Tables consist of a series of columns and rows. Columns define what data can be stored in the table, and rows are where you store the actual data.
Each table in a database is made up of one or more named columns (also known as fields). Each column describes one particular facet of your entity (for example, the name of a customer). For example, an entry in the previous Customers table is likely to have the following columns:
FirstName
LastName
Address
TelephoneNumber
And so on. Columns might be marked as required, in which case they must contain data for a given data item (for example, you'll probably always want to store the customer's name, address, and e-mail), but they might also allow NULL values (where no data is specified) in some circumstances—you don't necessarily need a customer phone number, for example. In most RDBMSs it's also possible to have columns that aren't maintained by you, such as a column that receives an automatically generated value for each data item, for example. You'll learn more about these topics later in this chapter.
Bear in mind that the columns that make up a table uniquely define that table. If you were to take data from somebody else's Customers table (that is, a Customers table in another database), things might not fit right. Instead of an Address column, for example, a different database might contain multiple columns, columns for each line of the address, like City, ZipCode, and others. This is an excellent example of a common problem—deciding which columns you require in a table. With addresses, the single-column model is more versatile because you could put anything you like in there, but using multiple columns makes more sense in terms of identifying and using the different strings that make up a complete address. However, the exact columns used might not fit in with the methods of addressing used worldwide. For example, United Kingdom addresses use postcodes rather than ZIP codes, which, while serving the same purpose, are formatted differently. This could cause problems both for users (who might not know how to enter data in columns with unfamiliar names) and administrators (who might rely on the validation of address information prior to shipment).
Once the columns in a table have been defined, it can be awkward to add more or remove redundant ones while maintaining data integrity, so a well-planned design at the start is essential.
Each column in a database table has a specific data type. This data type determines what information can be stored in the column. We'll return to this topic shortly.
Data in a database table takes the form of individual rows. Each row in a database is a single data entry, or item, and is often referred to as a record. A single row includes information for each column in a table that requires a value.
So, in the Customer table described earlier, a single row will represent a single customer. Joe Bloggs gets his own row, as would Bridget Jones.
A fundamental tenet of storing data in a relational database is that you must be able to uniquely identify each row of data that you store. As such, each table is required to have a column that's known as the primary key for the table. The data in this column is used to uniquely identify rows in a table, so if you ask for the row with a primary key value of seven (or row 2f7dh—keys don't necessarily have to be integers although they tend to be for simplicity), you'll receive one and only one row. It's usual for RDBMSs to keep track of key values, so if you try to add a row with a duplicate key, you'll probably raise an error.
| Note |
Primary keys only need to be unique across a single table. It's perfectly okay to have several tables using the same primary key values. |
Say you had a Friend table where you stored phone numbers for each of your friends. Without primary keys, you could have a Friend table with the following contents:
Name PhoneNumber --------------------------- ------------ Johnny 8989189 Johnny 2328014 Emilio 4235427 Girl nextdoor ???
Of course, this table has a problem. If we were to ask you what Johnny's phone number is, you couldn't answer because you have two records with the same Name value.
The solution is to either make Name a primary key (in which case the database will not allow duplicate values) or add a new column (an ID column) to act as a primary key. With an ID column, the Friend table would look like this:
FriendID Name PhoneNumber ----------- -------------------------- --------------- 1 Johnny 8989189 2 Johnny 2328014 3 Emilio 4235427 4 Girl nextdoor ???
In this example, even if you have two people named Johnny, they're regarded as different people because they have different IDs. Because the primary key is FriendID, this is the column on which you'll do the identifying searches on the table.
Although in practice it's easier to say that FriendID is the primary key column of Friend, technically this isn't accurate—a primary key isn't a column but a constraint that applies to a column.
Constraints are rules that apply to data tables and that form part of the integrity rules of the database. The database itself takes care of its integrity and makes sure that these rules aren't broken. As with data types (when, for example, the database doesn't allow you to insert a string value on a numeric column), you won't be able to insert two records with the same ID value if the ID column is set to be the primary key.
Sometimes choosing the primary key of a table can be a tough decision to make, especially because, in most cases, it has deep impact on the design of the whole database. The philosophy of database design says that the primary key column should represent (uniquely identify) the table rows. It's common to have values assigned to this column automatically by the RDBMS. Alternatively, unique properties of records could be used rather than a random value. You could use the Social Security number of a customer, for example. However, this can make things more complicated, and in general it's better to have a completely separate data facet for the primary key.
Primary keys can be formed by combing more than one column. The groups of columns that form the primary key, taken as a unit, are guaranteed to have unique values, even if the individual columns can have repeating values in the table.
There can be only one primary key on a table. A value must be entered for every row of the primary key (it isn't allowed to contain NULL values—see later), and an index is automatically created on its constituent columns. Indexes affect database performance, and we'll talk more about them in Chapter 12, "Working with Database Objects."
Before moving on, let's recap the terminology you've learned so far (see Figure 1-1).
A table has the power to enforce many rules regarding the data it stores, and it's important that you understand these rules, both when using the DML and when using the DDL portions of SQL. You've already seen what you can achieve by enforcing a primary key constraint on a column. There are many other options available. You'll not look at all of them here (you'll be meeting a fair amount of this when you learn about creating tables in Chapter 12, "Working with Database Objects"), you'll look at some of the most immediately useful areas. Data types are perhaps the most important way to control the stored data, so let's start with them.
Data types are a fundamental topic we need to discuss simply because you can't avoid them. It's always necessary to specify a data type when creating a new table field. This might mean that a given column can only hold integer numbers, for example. The data types used in RDBMSs tend to be a little more versatile than this, though, often allowing you to specify how many bytes of storage are allocated to an entry in a column, which will put a restriction on, say, the maximum value of an integer or the precision to which a floating-point number is represented. Alternatively, they might restrict data to positive values (we're still talking integers here—we've yet to see a database that restricts string-type columns to values such as "hardworking," "good sense of humor," or "team player"). Often, you'll want to restrict the number of characters allowed to store strings. For example, you might decide to limit a Password field to eight characters.
Choosing which data types to use for different columns can impact the performance and scalability of your database. By restricting values, you can ensure that less memory is taken up in the database because you don't allocate memory for values that can't be used. Data types also provide a low-level error checking capability because trying to put a "wrong" value in a database is likely to generate an error. As with variable types in some programming languages, though, this won't always be the case. Sometimes a round peg will fit through a square hole even though the square peg won't fit through the round hole, and you can't rely on this aspect of database storage to validate all your data. In any case, you can achieve far better and more powerful validation by other means.
One important (and occasionally annoying) point here is that column data types tend to vary between RDBMSs. This can make it difficult to transfer data between databases and might also result in having to change source code in order to access the same data in a different database. Often the difference is minor—perhaps an integer data type in one RDBMS is called int in another while retaining the same meaning—but it can still break code if you're not careful. Appendix C, "SQL Data Types," of this book provides an overview of the data types supported by each RDBMS and offers advice on "equivalent" types if a specific type in one RDBMS isn't supported (or called the same thing) in another.
Although in some cases the actual names differ, the main data types are supported by all databases. Let's see which these are.
Numbers are everywhere and probably are the favorite type of each database. Numbers come in different sizes, shapes, and internal storage formats.
Integers are usually represented by the INT or INTEGER data type. Depending on your database, you may have access to other integer data types (which differ by the minimum and maximum values allowed), such as TINYINT, SMALLINT, MEDIUMINT, and BIGINT.
Floating-point numbers are stored using the FLOAT, REAL, or NUMBER (for Oracle) data type.
A common issue regarding numeric data types concerns accurately storing monetary information. With MySQL and DB2, the DECIMAL data type is the way to go; with Oracle you use the general-purpose NUMBER, and SQL Server has a specialized Money data type, but DECIMAL (or NUMERIC) can also be used.
The second important group of types is the one that stores text and character data.
Usual names for string data types are CHAR, VARCHAR, and TEXT. VARCHAR is a variable-length type for which you specify a maximum size, but the actual size occupied in the database depends on the length of the string you're storing (which might be considerably lower than the maximum size defined for that column).
TEXT usually allows for much longer strings but acts considerably slower than CHAR and VARCHAR.
When creating or altering columns of character data types, you need to specify the maximum length of the string to be stored.
Apart from establishing the data types for your columns, you have to decide whether you have to enter a specific value into a column or whether you're allowed to leave it empty. In other words, can a column store NULL values?
What's NULL? Perhaps the best definition of NULL is "undefined"—simply a column for which a value hasn't been specified. The decision of allowing NULL values is a strategic one: Columns that you mark to reject NULL values will always have a value, and the database engine will require you to specify a value for them when adding new rows. On the other hand, if a column is nullable and you don't specify a value for it when adding a new row, NULL will be automatically assigned to it.
| Note |
An empty string ('') and a numeric value of zero are specific values and aren't the same as NULL values. |
Even saying "NULL value," although used frequently, is a bit misleading because NULL isn't a value. NULL specifies the absence of a value, and the database knows that. If you try to find all rows that have NULL for a specific field, searching with something like the following:
SELECT * FROM Customer WHERE PhoneNumber = NULL
you won't get any results. SQL works with a tri-valued logic: TRUE, FALSE, and UNKNOWN. For the previous query, the database engine will search through the rows and evaluate the values found in the PhoneNumber column against the search condition WHERE PhoneNumber = NULL. It'll return a row only if the search condition evaluates to TRUE. However, when a NULL value is compared to any other value— a definite value or another NULL—the answer is always UNKNOWN.
Instead, SQL has its own syntax for searching NULLs. You can retrieve all records that don't have a PhoneNumber specified with the following query:
SELECT * FROM Customer WHERE PhoneNumber IS NULL;
If you want to find all records that do have a value for PhoneNumber, this is the query that does the trick:
SELECT * FROM Customer WHERE PhoneNumber IS NOT NULL;
Often you'll want to create tables that have default values for some columns. In other words, when inserting new records into a table, instead of NULL, the database should insert a predefined value for the columns if the user specified no value.
Most databases support this option, using the DEFAULT constraint, which we'll discuss in detail in Chapter 12, "Working with Database Objects." In some cases you can also supply a function for the default value. With SQL Server, for example, you can supply GETDATE (say, to a column named DateInserted) that always returns the current date and time. This way, when a new row is inserted into the table, GETDATE is called, and the current date and time are supplied as the default value for the DateInserted column.
Like a primary key, UNIQUE is also a constraint that doesn't allow columns containing repeating values. However, there are differences. You can have multiple unique columns in a table—as opposed to a single primary key.
| Note |
Unique columns can sometimes be set to accept NULLs on SQL Server (in which case, the column can only accept one NULL value). MySQL and Oracle can accept NULLs on unique columns and can accept more than one row having a NULL for that column, but any data entered into that column on any row must be unique. DB2, on the other hand, won't let you create a table specifying that a column must be both unique and accept NULL values. |
UNIQUE columns are useful in cases where you already have a primary key but you still have columns for which you want to have unique values. This might the case for a column named Email or MobilePhone in the Customer table, in a scenario where CustomerID is the primary key.
Of course, databases are about much more than stuffing specific types of data in specific columns of a particular table and being able to identify each row. The power of relational databases comes, as the name suggests, from the ability to define relationships between data in different tables. These related tables form the relational database (the database object), which becomes an object with a significance of its own, rather than simply being a group of unrelated data tables. Relational databases store information. It's said that data becomes information only when you give significance to it, and establishing relations with other pieces of data is a good means of doing that. Moving from the concept of a table to that of relational databases isn't a huge leap, but it's a crucial step for any serious SQL programmer.
It helps to think of the entities (the real "things") that database tables need to describe. For example:
You have customers who place orders for certain products.
Straight away, you start to see the sort of entities that you must describe and the relationships that exist between them. You might be able to map these entities directly to tables, creating a Customers table, an Orders table, and a Products table.
In reality, although the underlying concept of identifying entities and their interrelationship is valid, it's likely to be slightly more complex than that. For example, how much information do you store in the Customers table? Do you store customers' billing addresses there? What if they have more than one address?
In fact, there exists a whole bunch of rules that define how you can most effectively store your data to avoid repetition (storing the same information over and over again) and to safeguard against any possible infringement on the integrity of the data. The process is called normalization, and the rules are called normal forms. We aren't going to discuss this in detail in this book because we want to focus on SQL, not on the optimum design for relational databases.
| Note |
You can find a good treatment of normal forms in the book Joe Celko's SQL for Smarties: Advanced SQL Programming, Second Edition (Morgan Kaufmann, 1999). |
However, we do need to introduce some of the fundamental relational data storage concepts that you simply must understand in order to write effective SQL queries against relational databases. For example, you'll investigate how to do the following:
Create relationships between tables (one customer may create many orders...): You can then use SQL to retrieve data that's spread across more than one table (for example, to retrieve all of the orders made by a specific customer).
Safeguard against fundamental data integrity issues: For example, you can ensure that you don't enter the same order twice (the customer would be unhappy to be billed twice for the same purchase) or enter an order for a customer who doesn't exist.
Primary keys are central to your ability to define relationships. For example, a customer row in your Customer table might refer to credit card details stored in a CreditCards table rather than including the information in a single place. The advantage is that is becomes much easier to make more complex associations between data.
Because one customer may own multiple credit cards, it's important to be able to link those cards to that exact customer who owns them, and primary keys help to ensure that this happens. However, there's more to it than this.
As we've discussed, information is rarely stored in a single data table. Most of the time, you try to store relatively independent pieces of information in separate tables—in something that you name to be a normalized form of the data.
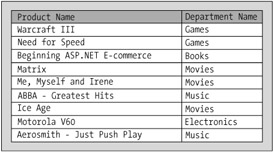
Say that you want to create a database where you need to store information about some products and about the departments to which they belong. In a non-normalized database, you might simply create a table named ProductDepartment, containing the data shown in Figure 1-2.
Having data stored like this generates more problems than it solves—storing information this way is, most importantly, hard to maintain. Imagine that you had also stored descriptions and other attributes for departments and products.
Also, you're storing repeating groups of information. If you want to change the name of a department, instead of changing it in one place, you need to change it in every place it was used. If you want to get a list of all the different departments, you need to do a resources-heavy query on the ProductDepartment table. And the list of potential problems has just begun....
In the process of data normalization, you split tables such as ProductDepartment into separate tables to eliminate repeating groups of information.
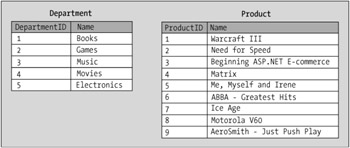
The ProductDepartment table shown earlier contains data about products and departments. In a normalized data structure, you would store them in separate tables, as shown in Figure 1-3.
In a normalized database, having primary keys that uniquely identify the records is a fundamental necessity. The problem with the previous tables is that, based on the data they offer, you can't find out which departments relate to which products.
Depending on the kind of relationship you want between departments and products, you may need to do further modifications to the tables' structures. Let's continue the journey by taking a closer look at table relationships and how you implement them in the database.
So, what types of table relationships are there, after all? You always need to decide how your data relates before designing the database.
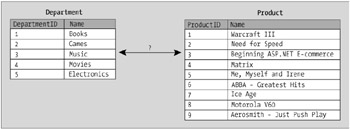
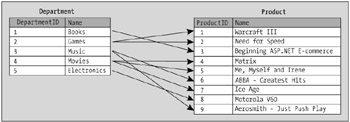
Let's continue with the example. Again, the problem is that, with the current structure, you have no way of knowing which departments relate to which products, as shown in Figure 1-4.
Two tables like the ones you see here can't be very helpful because they don't tell you which products belong to which departments. However, having a figure such as this containing the individual rows without the relationships helps you see what kind of relations should be implemented.
There are two main kinds of table relationships:
The one-to-many relationship: One row in a table is related to one or more rows in the related table.
The many-to-many relationship: Multiple rows in one table match multiple rows in the related table.
Although relatively rare, there's also a one-to-one relationship, whereby one and only one row in a table is matched with a single row in its related table. For example, in a database that allowed patients to be assigned to beds, you would hope that there would be a one-to-one relationship between patients and beds!
With the one-to-many relationship, one record in a table can be associated with multiple records in the related table, but not vice versa.
If you decide that each department can contain more products, but a product belongs to exactly one department (a product can't belong to more departments), then the one-to-many relationship is the best choice for your tables.
This becomes clearer after visualizing the relationship (see Figure 1-5).
With this graphic, you can see that for each department there are more related products: One department relates to many products, and thus you have a one-to-many relationship.
| Note |
The opposite must not be true: A product shouldn't relate to many departments. If it did, you'd have a many-to-many relationship (discussed in the next section). |
Figure 1-5 showed which products belong to which departments using arrows—it's time to see how you can tell the database to store this information.
| Tip |
You implement the one-to-many relationship by adding a column to the table in the many side of the relationship. The new column will store the ID (the primary key value) of the record in the one part of the relationship to which it relates. |
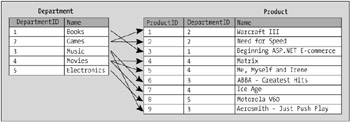
In the sample scenario, you need to add a DepartmentID column to the Product table, as shown in Figure 1-6.
| Note |
The table at the many part of the relation (Product in this case) is called the referencing table, and the other table is called the referenced table. |
You can visual this relationship in the form of a database diagram in different ways. For example, Figure 1-7 shows how SQL Server's Enterprise Manager shows the relationship.
The golden key located next to column names show the primary key of the table. When the primary key is formed using a combination of more than one column, all the columns forming the primary key will be marked with the golden keys; remember that you can't have more than one primary key in a table, but a primary key can be formed from more than one column.
In the relationship line, the golden key shows the table whose primary key is involved in the relationship—in other words, it points to the table on the one side of the relationship. The infinity sign shows the table in the many side of the relationship.
Note that the relationship signs don't also show the table columns involved in the relationship—they only show the kind and direction of the relationship.
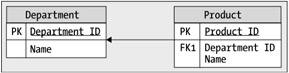
The same diagram looks like Figure 1-8 when drawn differently.
In this figure, primary keys are marked with PK and are listed separately at the beginning of the list, and the foreign keys with FK (foreign keys are discussed in the next section) are listed next. Because there can be more than one foreign key, they're numbered. Columns that don't allow NULLs are displayed in bold. The arrow points to the table at the one side of the relationship.
After DepartmentID is added to Product, the database has all the information it needs to find out which products belong to which departments. You can then query these two tables to see combined information from both tables. You could use the following SQL query to display a list containing the name of each product along with the name of the department to which it belongs:
SELECT Product.Name, Department.Name FROM Product, Department WHERE Product.DepartmentID = Department.DepartmentID
This query returns these results:
Name Name ---------------------------------- ------------------ Warcraft III Games Need for Speed Games Beginning ASP.NET E-Commerce Books Matrix Movies Me, Myself, and Irene Movies ABBA - Greatest Hits Music Ice Age Movies Motorola V60 Electronics Aerosmith - Just Push Play Music
Don't worry too much about how the SQL code works from now, but this should help to show how you can still see the same data you listed before, even though it's now stored in two different but related tables.
You can enforce the one-to-many relationship by the database using foreign key constraints. A column that has a foreign key constraint defined on it is called a foreign key in that table. The foreign key is a column or combination of columns used to establish or enforce a link between data in two tables.
| Tip |
The foreign key constraint is always defined for a column in the referencing table, and it references the primary key of the referenced table. |
Remember, the referencing table is the one at the many side of the relationship, and the referenced table is the one at the one side of the relationship. In the products/departments scenario, the foreign key is defined on the DepartmentID column of the Product table, and it references the DepartmentID column of the Department table.
You need to enforce table relationships in order to maintain the database in a consistent state. Without enforcing table relationships using foreign keys, you could end up deleting rows that are being referenced from other tables or referencing nonexistent rows, thus resulting in orphaned records. This is something you need to avoid (for example, you don't want rows in the Product table referencing nonexistent departments).
Unlike the constraints you learned about in the first part of the chapter, which apply to the table as an independent database object, the foreign key constraint applies restrictions on both referencing and referenced tables. When establishing a one-to-many relationship between the Department and the Product tables by using a foreign key constraint, the database will include this relationship as part of its integrity. It won't allow you to add a category to a nonexistent department, and it won't allow you to delete a department if there are categories that belong to it.
A many-to-many relationship happens when records in both tables of the relationship can have multiple matching records in the other table. While studying the many-to-many relationship, you'll see that depending on how the records in your data tables are related, you may need to implement the database structures to support the relationships differently.
With the one-to-many relationship, one department could contain many products (one department/many products). With the many-to-many relationship, the opposite is also true: One product can belong to more departments (one product/many departments).
You'd need this kind of relationship for the scenario if you want to support adding products that can be part of more than one department, such as a product named Selection of Christmas Games and Music. This product should be found in both the Games and Music departments. So how do you implement this into the database?
| Tip |
Although logically the many-to-many relationship happens between two data tables, in practice you need to add a third table to the mix. This third table, named a junction table (also known as a linking table, associate table, or bridge table), associates records in the two tables you need to relate by implementing two one-to-many relationships, resulting in the many-to-many relationship. |
The theory might sound a bit complicated, but actually it's quite simple. In Figure 1-9, you can see how the junction table associates the departments and products.
This figure shows how the junction table can be used to link products to departments. You can easily see that each department is linked to more products and that the newly added product is also linked to two departments. So, the magic has been done: The junction table successfully allowed you to implement the many-to-many relationship.
Figure 1-10 presents the new database diagram containing the ProductDepartment junction table.
Because the many-to-many relationship is implemented as two one-to-many relationships, the foreign key constraint is all you need to enforce it. The junction table is the referencing table, and it references the two tables that form the many-to-many relationship.
In the junction table, both columns form the primary key, so each (ProductID, DepartmentID) pair is guaranteed to be unique. This makes sense because the junction table associates one product with one department— a product can either be or not be associated with a particular department. It wouldn't make sense to associate a product with a department twice.