|
|
4.3 Doing Software Correctly: Enterprise Architecture DevelopmentSolving complex problems with teams of people requires planning. For enterprise software systems, some of the most important planning is highly technical (i.e., planning system architecture). Planning generates artifacts, but planning (as an activity) is much more important than project management plans, the typical artifacts. In other words, a document-driven process is not recommended because its priorities focus on paper artifacts, whereas the real product of any software development project is software. Instead, planning is seen in a broader context, with multiple levels of formality and technical detail. For example, developing a software architecture requires planning, as well as analyzing requirements, modeling designs, and generating plans. The level of formality should be tied to the longer term usefulness of the documentation. In architecture-centered development, planning is pragmatic (Figure 4.2). Project plans and design models are throwaway documentation because their accuracy is short lived. Once a plan or specification is out of date, it is essentially useless. For example, source-code changes can quickly make design models obsolete. Figure 4.2. Without Planning, It Becomes Apparent That Many Individual Successes Are Not Sufficient for Overall Project Success
In addition, software methods and standards should be treated as guidelines, not mandates. Project teams are encouraged to think for themselves and tailor the process to meet the project's needs. Pragmatics is a fundamental principle of software modeling: for requirements, architecture, and design. Every model has a purpose and focus, suppressing unimportant details. Models should document important decisions, based upon project assumptions and priorities. Deciding what's important is an essential decision skill that is part of being a competent architect. Architecture-Centered ProcessFigure 4.3 shows the ten-step process for architecture-centered development that covers the full system life cycle. This process is based upon key software standards and best-practice patterns proven in practice. Figure 4.3. Architecture-Centered Development Process
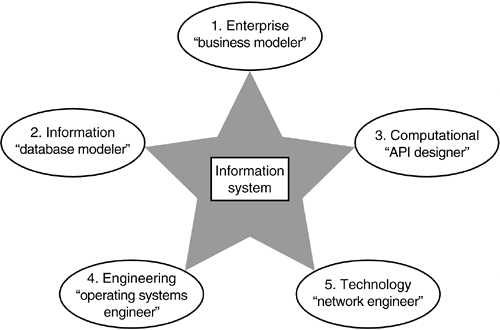
A key objective is to facilitate productivity in Step 7 for parallel iterative development (i.e., coding and testing). In this discussion, the activities preceding Step 7 are emphasized because these steps comprise the architectural planning activities where the key issues reside in current enterprise development. This process is inherently iterative and incremental; consequently, it may necessitate revisions to artifacts from previous steps. However, the predevelopment steps do have a waterfall progression because of their interdependencies. The entire process is quality driven, with the ultimate goal of satisfying end-user needs by establishing a stable description of the architecture and a working software codebase that can accommodate change. Step 1: System EnvisioningIn discussing modeling, the key words purpose, focus, assumptions, and priorities are mentioned. These are all essential elements of a systemwide Vision Statement. If they change during system development, the project is at risk of making its own models obsolete. Therefore, the first step of architecture-centered development is to establish a Vision Statement, with the binding assumption that the Vision Statement cannot change after development begins (Step 7). Any changes must be reflected in key project plans-in particular, the System Architecture (Step 4). In effect, the Vision Statement is a binding agreement between the system developers and the system users. It should be short and to the point, typically fewer than 10 pages of text, depending on the system. The Vision Statement establishes the context for all subsequent project activities, starting with requirements analysis. Step 2: Requirements AnalysisThe requirements should define the external behavior and appearance of the system, without designing the internal structure of the system. The external behavior includes internal actions (such as persistence or calculation) that are required to ensure desired external behavior. The external appearance comprises the layout and navigation of the user interface screens. An effective approach for capturing behavioral requirements is through use cases. A use case comprises a top-level diagram and extensive textual description. A typical use case diagram is shown in Figure 4.2, for an information retrieval architecture. Use case notation is deceptively simple, but it has one invaluable quality: It enforces abstraction. Use case notation is one of the most effective notations ever devised for expressing complex concepts. Hence, it's great for ensuring simplicity and clarity in representing top-level requirements concepts. For each individual use case, there is an extensive textual description of the relevant requirements. This write-up takes the form of a long list, containing a sequence of actions, described in domain-specific prose. The definition of use cases should be done jointly with domain experts. Without continuous involvement of domain experts, the exercise is a common AntiPattern called Pseudo Analysis (i.e., something to be avoided). Use cases provide a model of the end-user's view of the system for the purpose of defining project scope. Use cases also have a downstream role. In development (Step 7) use cases are extended with system-specific scenario diagrams. Eventually, these scenarios are elaborated into software tests. The appearance, functionality, and navigation of the user interface are closely related to the use cases. An effective approach to defining the screens is called low-fidelity prototyping. In this approach, the screens are drawn out with paper and pencil. Again, the end-user domain experts are continuously involved in the screen definition process. With the use cases and user interfaces defined, a context for architectural planning has been established. In addition to generating documentation (including paper and pencil sketches), the architecture team acquires a deep understanding of the desired system capabilities in the context of the end-user domain. A final product of requirements analysis is a project glossary, which should be extended during architectural planning (Step 4). Step 3: Mockup PrototypeThe screen definitions from Step 2 are used to create an online mockup of the system. Dummy data and simple file input/output (I/O) can be used to provide more realistic interface simulation in key parts of the user interface. The mockup is demonstrated to end-users and management sponsors. End-users and architects should jointly review the mockups and run through the use cases (Step 2) to validate requirements. Often, new or modified requirements will emerge during this interchange. Screen dumps of any modified screens should be generated and marked up for subsequent development activities. Any modifications to requirements should then be incorporated by the other architectural activities. Through the mockup, management can see visible progress, a politically important achievement for most projects. This step is an example of an external (or vertical) increment, which is used for risk reduction, in terms of both politics and system requirements. With rapid prototyping technologies such as screen generation wizards, mockups can be generated in less than a staff month for most systems. Step 4: Architectural PlanningArchitecture bridges the huge semantic gap between requirements and software. Because requirements notation is prose, requirements are inherently ambiguous, intuitive, and informal. It's right-brain stuff. Software, on the other hand, has the opposite characteristics. Software source code is a formal notation. Software is interpreted unambiguously by a machine, and its meaning is logically unintuitive (i.e., hard to decipher). It's left-brain stuff. Architecture's first role is to define mapping between these two extremes. Architecture captures the intuitive decisions in a more formal manner (which is useful to programmers), and it defines internal system structure before it is hardwired into code (so that current and future requirements can be satisfied). Architecture is a plan that manages system complexity in a way that enables system construction and accommodates change. Architecture has another significant role: defining the organization of the software project (see Step 6). Architectural planning is the key missing step in many current software projects, processes, and methods. One cause for this gap is the ongoing debate about the question: "What is architecture?" Fortunately, this question has already been answered definitively, by the software architecture profession, in a formal ISO standard for Open Distributed Processing. Architecture is a set of rules to define the structure of a system and the interrelationships between its parts [ISO 1996]. ODP, a powerful way to think about complex systems, simplifies decision making (i.e., working smarter, not harder). It organizes the system architecture in terms of five standard viewpoints, describing important aspects of the same system. These viewpoints include business enterprise, logical information, computational interface, distributed engineering, and technology selection (Figure 4.4). Figure 4.4. ODP Viewpoints
For each viewpoint, it is important to identify conformance to architectural requirements. If conformance has no objective definition, then the architecture is meaningless because it will have no clear impact upon implementation. ODP facilitates this process because ODP embodies a pervasive conformance approach. Only simple conformance checklists are needed to identify conformance points in the architecture. The following paragraphs summarize each of these viewpoints. Using ODP, a typical architectural specification is concise, comprising about 100 pages, depending upon the system. Each viewpoint comprises 5 to 20 pages. It is expected that every developer will read this document, cover to cover, and know its contents. The content should be used not only to create tutorials but also to be communicated to developers, in detail, through a multiday kickoff meeting. (See Step 7.) Business Enterprise ArchitectureThe Business Enterprise Architecture (the enterprise viewpoint) defines the business purpose and policies of the system in terms of high-level enterprise objects. These business object models identify the key constraints on the system, including the system objective and important system policies. Policies are articulated in terms of three categories: (1) obligations-what business objects must do, (2) permissions-what business objects may do, and (3) prohibitions-what business objects must not do. A typical Business Enterprise Architecture comprises a set of logical object diagrams (in UML notation) and prose descriptions of the diagram semantics. Logical Information ArchitectureThe Logical Information Architecture (the information viewpoint) identifies what the system must know. This architecture is expressed in terms of an object model with an emphasis on attributes that define the system state. Because ODP is an object-oriented approach, the models also include key information processes, encapsulated with the attributes (i.e., the conventional notion of an object). A key distinction is that architectural objects are not programming objects. For example, the information objects do not denote objects that must be programmed. On the other hand, the architecture does not exclude this practice. Architectural objects represent positive and negative constraints on the system. Positive constraints identify things that the system's software must do. Negative constraints are things that the system's software does not have to do. Knowledge of these constraints is extremely useful to programmers because it eliminates much of the guesswork in translating requirements to software. The architects should focus their modeling on those key system aspects of greatest risk, complexity, and ambiguity, leaving straightforward details to the development step. The information model does not constitute an engineered design. In particular, engineering analysis, such as database normalization, is explicitly delegated to the development activities (Step 7). Computational Interface ArchitectureOften neglected by architects, the computational interface architecture (the computational viewpoint) defines the top-level Application Program Interfaces. These are fully engineered interfaces for subsystem boundaries. In implementation, the developers will program their modules to these boundaries, thus eliminating major design debates involving multiple developers and teams. The architectural control of these interfaces is essential to ensuring a stable system structure that supports change and manages complexity. An ISO standard notation ODP computational architecture is the OMG Interface Definition Language. IDL is a fundamental notation for software architects because it is completely independent of programming-language and operating-system dependencies. IDL can be automatically translated to most popular programming languages for both CORBA and Microsoft technology bases (i.e., COM/DCOM) through commercially available compilers. Related techniques for defining computational architectures include architectural mining and domain analysis. Distributed Engineering ArchitectureDistributed engineering architecture (the engineering viewpoint) defines the requirements on infrastructure, independent of the selected technologies (Figure 4.5). The engineering viewpoint resolves some of the most complex system decisions, including physical allocation, system scalability, and communication qualities of service (QoS). Figure 4.5. ODP Engineering Viewpoint
One of the key benefits of ODP is its separation of concerns (i.e., design forces). Fortunately, the previous viewpoints resolved many other complex issues that are of lesser concern to distributed systems architects, such as APIs, system policies, and information schemas. Conversely, these other viewpoints were able to resolve their respective design forces, independent of distribution concerns. Many software and hardware engineers find this part of architectural modeling to be the most interesting and enjoyable. Fascinating decisions must be made regarding system aspects such as object replication, multithreading, and system topology. Technology Selection ArchitectureTechnology Selection Architecture (the technology viewpoint) identifies the actual technology selection. All other viewpoints are fully independent of these decisions. Because the majority of the architectural design is independent, commercial technology evolution can be readily accommodated. A systematic selection process includes initial identification of conceptual mechanisms (such as persistence or communication). The specific attributes (requirements) of the conceptual mechanism are gathered from the other viewpoints. Concrete mechanisms are identified (such as DBMS, OODBMS, and flat files). Then specific candidate mechanisms are selected from available technologies (such as Sybase, Oracle, and Object Design databases). Based upon initial selections from candidates, this process is iterated with respect to project factors such as product price, training needs, and maintenance risks. The rationale behind these selections must be retained because it is important to record the rationale for all viewpoints as future justification of architectural constraints. This recording can be done in an informal project notebook maintained by the architecture team for future reference. Step 5: Architectural PrototypeThe architectural prototype is a simulation of the system architecture. System API definitions are compiled and stub programs written to simulate the executing system. The architectural prototype is used to validate the computational and engineering architectures, including flow of control and timing across distribution boundaries. Using technologies like CORBA, a computational architectural specification can be automatically compiled into a set of programming header files with distributed stubs (calling side) and skeletons (service side). Dummy code is inserted in the skeletons to simulate processing. Simple client programs are written to send invocations across computational boundaries with dummy data. A handful of key (e.g., high-risk) use cases are simulated with alternative client programs. Prototype execution is timed to validate conformance with engineering constraints. Changes to the computational, engineering, or technology architectures are proposed and evaluated. Step 6: Project PlanningAs the final step in the predevelopment process, project management plans are defined and validated to resolve resource issues, including staffing, facilities, equipment, and commercial technology procurement. A schedule and a budget are established, according to the availability (lead time) for resources and project activities. The schedule for Step 7 is planned in terms of parallel activities for external and internal increments. External increments support risk reduction with respect to requirements and management support (see Step 4). Internal increments support the efficient use of development resources-for example, the development of back-end services used by multiple subsystems. Current best practices are to perform several smaller internal increments supporting larger-scale external increments, called VW staging. Ideally, several project teams of up to four programmers are formed, with three-month deliverable external increments. In practice, this has proven to be the most effective team size and increment duration. The three-month increment includes design, code, and unit testing, not the operations and maintenance portions of the life cycle such as deployment and support. The architecture-centric process enables the parallel increments. Because the system is partitioned with well-defined computational boundaries, development teams can work independently, in parallel with other teams, within their assigned boundaries. Integration planning includes increments that span architectural boundaries. The detail in the project plan should not be inconsistent. The plan should be very detailed for early increments and should include replanning activities for later in the project. This approach recognizes the reality that project planners don't know everything up front. A risk mitigation plan is also prepared with identification of technical alternatives. The development team involved in mockup and architecture prototyping should continue to develop experimental prototypes with high-risk technologies in advance of the majority of developers. This is called the "run-ahead team" and is a key element of risk mitigation. The final activity in project management planning is the architectural review and startup decision. Up to this point, the enterprise sponsors have made relatively few commitments, compared to the full-scale development (about 5% of system cost, depending on the project). Executive sponsors of the project must make a business decision about whether to proceed with building the system. This executive commitment will quickly lead to many other commitments that are nearly impossible to reverse (e.g., technology lock-in, expenses, and vendor-generated publicity). At this point, the system architects are offering the best possible solution and approach, in the current business and technology context. If the system concept still makes business sense, compared to the opportunity costs, the enterprise is in an excellent position to realize the system because they're doing software correctly. Step 7: Parallel DevelopmentDevelopment project kickoff involves several key activities. The developers must learn and internalize the architecture and requirements. An effective way to achieve this is with a multiday kickoff meeting, which includes detailed tutorials from domain experts and architects. The results of all previous steps are leveraged to bring the developers up to speed quickly and thoroughly. The lectures ideally should be videotaped so that staff turnover replacements can be similarly trained. Each increment involves a complete development process, including designing, coding, and testing. Initially, the majority of the increments will be focused on individual subsystems. As the project progresses, an increasing number of increments will involve multiple subsystem integration. A project rhythm that enables coordination of development builds and tests is established. For most of the software development activity, the architecture is frozen, except at some planned points, where architectural upgrades can be inserted without disruption. Architectural stability enables parallel development. For example, at the conclusion of a major external increment, an upgrade to the computational architecture can be inserted, before the next increment initiates. The increment starts with an upgrade of the software, conformant with the changes. In practice, the need and frequency of these upgrades decreases as the project progresses. The architect's goal is to increase the stability and quality of the solution, based upon feedback from development experience. A typical project would require two architectural refactorings (upgrades) before a suitably stable configuration is achieved for deployment. Step 8: System TransitionDeployment of the system to a pilot group of end-users should be an integral part of the development process. Based upon lessons learned in initial deployment, development iterations might be added to the plan. Schedule slips are inevitable, but serious quality defects are intolerable for obvious reasons. Improving quality by refactoring software (improving software structure) is an important investment in the system that should not be neglected. In this step, an important role for the architect involves system acceptance. The architect should confirm that the system implementation is conformant with the specifications and fairly implements the end-users' requirements. This task is called architectural certification. In effect, the architect should be an impartial arbitrator between the interests of the end-users and those of the developers of the system. If the end-users define new requirements that have an impact on architectural assumptions, the architect assesses the request and works with both sides to plan feasible solutions. Step 9: Operations and MaintenanceOperations and Maintenance (O&M) is the real proving ground for architecture-centered development. Whether or not "doing software correctly" was effective will be proven in this step. The majority of system cost will be expended here. As much as 70% of the O&M cost will be caused by system extensions-requirements and technology changes that are the key sources of continuing development. Typically, half of a programmer's time will be expended trying to figure out how the system works. Architecture-centered development resolves much of this confusion with a clear, concise set of documentation: the system architecture. Step 10: System MigrationSystem migration to a follow-on target architecture occurs near the end of the system life cycle. Two major processes for system migration are called big bang and chicken little. A big bang is a complete, overnight replacement of the legacy. In practice, the big bang seldom succeeds; it is a common AntiPattern for system migration. The chicken little approach is more effective and ultimately more successful. Chicken little involves simultaneous, deployed operation of both target and legacy systems. The initial target system users are the pilot group (as in Step 8). Gateways are integrated between the legacy and target systems. Forward gateways allow legacy users to have access to data that are migrated to the target system. Reverse gateways allow target system users to have transparent access to legacy data. Data and functionality are migrated incrementally from the legacy to the target system. In effect, system migration is a continuous evolution. As time progresses, new users are added to the target system and taken off the legacy environment. In the long term, switching off the legacy system will become feasible. By that time, it is likely that the target system will become the legacy in a new system migration. The target system transition (Step 8) overlaps the legacy system migration (Step 10). In the chicken little approach, Steps 8, 9, and 10 are part of a continuous process of migration. |
|
|