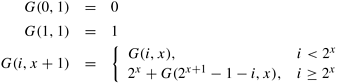|
|
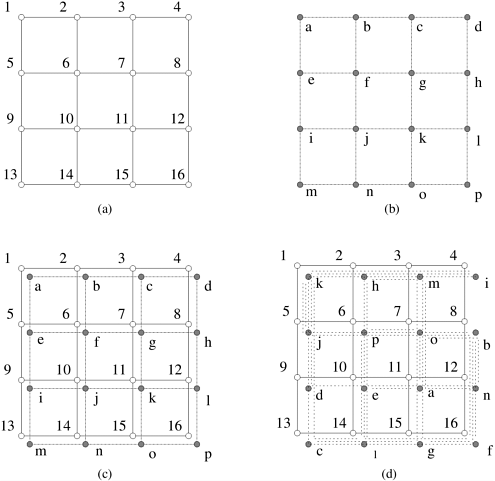
2.7 Impact of Process-Processor Mapping and Mapping TechniquesAs we have discussed in Section 2.5.1, a programmer often does not have control over how logical processes are mapped to physical nodes in a network. For this reason, even communication patterns that are not inherently congesting may congest the network. We illustrate this with the following example: Example 2.17 Impact of process mapping Consider the scenario illustrated in Figure 2.29. The underlying architecture is a 16-node mesh with nodes labeled from 1 to 16 (Figure 2.29(a)) and the algorithm has been implemented as 16 processes, labeled 'a' through 'p' (Figure 2.29(b)). The algorithm has been tuned for execution on a mesh in such a way that there are no congesting communication operations. We now consider two mappings of the processes to nodes as illustrated in Figures 2.29(c) and (d). Figure 2.29(c) is an intuitive mapping and is such that a single link in the underlying architecture only carries data corresponding to a single communication channel between processes. Figure 2.29(d), on the other hand, corresponds to a situation in which processes have been mapped randomly to processing nodes. In this case, it is easy to see that each link in the machine carries up to six channels of data between processes. This may potentially result in considerably larger communication times if the required data rates on communication channels between processes is high. Figure 2.29. Impact of process mapping on performance: (a) underlying architecture; (b) processes and their interactions; (c) an intuitive mapping of processes to nodes; and (d) a random mapping of processes to nodes.
It is evident from the above example that while an algorithm may be fashioned out of non-congesting communication operations, the mapping of processes to nodes may in fact induce congestion on the network and cause degradation in performance. 2.7.1 Mapping Techniques for GraphsWhile the programmer generally does not have control over process-processor mapping, it is important to understand algorithms for such mappings. This is because these mappings can be used to determine degradation in the performance of an algorithm. Given two graphs, G(V, E) and G'(V', E'), mapping graph G into graph G' maps each vertex in the set V onto a vertex (or a set of vertices) in set V' and each edge in the set E onto an edge (or a set of edges) in E'. When mapping graph G(V, E) into G'(V', E'), three parameters are important. First, it is possible that more than one edge in E is mapped onto a single edge in E'. The maximum number of edges mapped onto any edge in E' is called the congestion of the mapping. In Example 2.17, the mapping in Figure 2.29(c) has a congestion of one and that in Figure 2.29(d) has a congestion of six. Second, an edge in E may be mapped onto multiple contiguous edges in E'. This is significant because traffic on the corresponding communication link must traverse more than one link, possibly contributing to congestion on the network. The maximum number of links in E' that any edge in E is mapped onto is called the dilation of the mapping. Third, the sets V and V' may contain different numbers of vertices. In this case, a node in V corresponds to more than one node in V'. The ratio of the number of nodes in the set V' to that in set V is called the expansion of the mapping. In the context of process-processor mapping, we want the expansion of the mapping to be identical to the ratio of virtual and physical processors. In this section, we discuss embeddings of some commonly encountered graphs such as 2-D meshes (matrix operations illustrated in Chapter 8), hypercubes (sorting and FFT algorithms in Chapters 9 and 13, respectively), and trees (broadcast, barriers in Chapter 4). We limit the scope of the discussion to cases in which sets V and V' contain an equal number of nodes (i.e., an expansion of one). Embedding a Linear Array into a HypercubeA linear array (or a ring) composed of 2d nodes (labeled 0 through 2d -1) can be embedded into a d-dimensional hypercube by mapping node i of the linear array onto node G(i, d) of the hypercube. The function G(i, x) is defined as follows:
The function G is called the binary reflected Gray code (RGC). The entry G(i, d) denotes the i th entry in the sequence of Gray codes of d bits. Gray codes of d + 1 bits are derived from a table of Gray codes of d bits by reflecting the table and prefixing the reflected entries with a 1 and the original entries with a 0. This process is illustrated in Figure 2.30(a). Figure 2.30. (a) A three-bit reflected Gray code ring; and (b) its embedding into a three-dimensional hypercube.
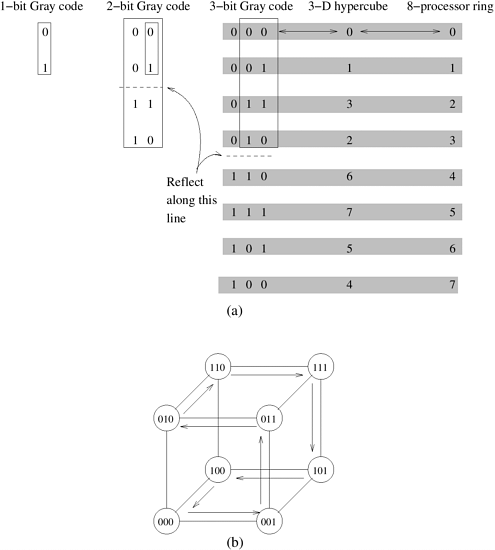
A careful look at the Gray code table reveals that two adjoining entries (G(i, d) and G(i + 1, d)) differ from each other at only one bit position. Since node i in the linear array is mapped to node G(i, d), and node i + 1 is mapped to G(i + 1, d), there is a direct link in the hypercube that corresponds to each direct link in the linear array. (Recall that two nodes whose labels differ at only one bit position have a direct link in a hypercube.) Therefore, the mapping specified by the function G has a dilation of one and a congestion of one. Figure 2.30(b) illustrates the embedding of an eight-node ring into a three-dimensional hypercube. Embedding a Mesh into a HypercubeEmbedding a mesh into a hypercube is a natural extension of embedding a ring into a hypercube. We can embed a 2r x 2s wraparound mesh into a 2r+s -node hypercube by mapping node (i, j) of the mesh onto node G(i, r - 1)||G( j, s - 1) of the hypercube (where || denotes concatenation of the two Gray codes). Note that immediate neighbors in the mesh are mapped to hypercube nodes whose labels differ in exactly one bit position. Therefore, this mapping has a dilation of one and a congestion of one. For example, consider embedding a 2 x 4 mesh into an eight-node hypercube. The values of r and s are 1 and 2, respectively. Node (i, j) of the mesh is mapped to node G(i, 1)||G( j, 2) of the hypercube. Therefore, node (0, 0) of the mesh is mapped to node 000 of the hypercube, because G(0, 1) is 0 and G(0, 2) is 00; concatenating the two yields the label 000 for the hypercube node. Similarly, node (0, 1) of the mesh is mapped to node 001 of the hypercube, and so on. Figure 2.31 illustrates embedding meshes into hypercubes. Figure 2.31. (a) A 4 x 4 mesh illustrating the mapping of mesh nodes to the nodes in a four-dimensional hypercube; and (b) a 2 x 4 mesh embedded into a three-dimensional hypercube.
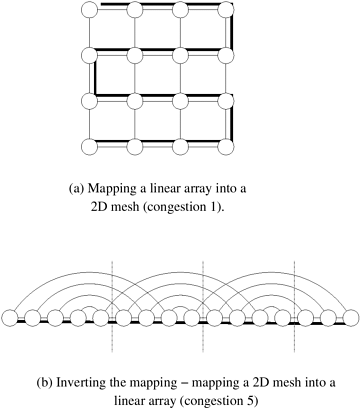
This mapping of a mesh into a hypercube has certain useful properties. All nodes in the same row of the mesh are mapped to hypercube nodes whose labels have r identical most significant bits. We know from Section 2.4.3 that fixing any r bits in the node label of an (r + s)-dimensional hypercube yields a subcube of dimension s with 2s nodes. Since each mesh node is mapped onto a unique node in the hypercube, and each row in the mesh has 2s nodes, every row in the mesh is mapped to a distinct subcube in the hypercube. Similarly, each column in the mesh is mapped to a distinct subcube in the hypercube. Embedding a Mesh into a Linear ArrayWe have, up until this point, considered embeddings of sparser networks into denser networks. A 2-D mesh has 2 x p links. In contrast, a p-node linear array has p links. Consequently, there must be a congestion associated with this mapping. Consider first the mapping of a linear array into a mesh. We assume that neither the mesh nor the linear array has wraparound connections. An intuitive mapping of a linear array into a mesh is illustrated in Figure 2.32. Here, the solid lines correspond to links in the linear array and normal lines to links in the mesh. It is easy to see from Figure 2.32(a) that a congestion-one, dilation-one mapping of a linear array to a mesh is possible. Figure 2.32. (a) Embedding a 16 node linear array into a 2-D mesh; and (b) the inverse of the mapping. Solid lines correspond to links in the linear array and normal lines to links in the mesh.
Consider now the inverse of this mapping, i.e., we are given a mesh and we map vertices of the mesh to those in a linear array using the inverse of the same mapping function. This mapping is illustrated in Figure 2.32(b). As before, the solid lines correspond to edges in the linear array and normal lines to edges in the mesh. As is evident from the figure, the congestion of the mapping in this case is five - i.e., no solid line carries more than five normal lines. In general, it is easy to show that the congestion of this (inverse) mapping is While this is a simple mapping, the question at this point is whether we can do better. To answer this question, we use the bisection width of the two networks. We know that the bisection width of a 2-D mesh without wraparound links is The lower bound established above has a more general applicability when mapping denser networks to sparser ones. One may reasonably believe that the lower bound on congestion of a mapping of network S with x links into network Q with y links is x/y. In the case of the mapping from a mesh to a linear array, this would be 2p/p, or 2. However, this lower bound is overly conservative. A tighter lower bound is in fact possible by examining the bisection width of the two networks. We illustrate this further in the next section. Embedding a Hypercube into a 2-D MeshConsider the embedding of a p-node hypercube into a p-node 2-D mesh. For the sake of convenience, we assume that p is an even power of two. In this scenario, it is possible to visualize the hypercube as The mapping from a hypercube to a mesh can now be defined as follows: each Figure 2.33. Embedding a hypercube into a 2-D mesh.
To establish a lower bound on the congestion, we follow the same argument as in Section 2.7.1. Since the bisection width of a hypercube is p/2 and that of a mesh is Process-Processor Mapping and Design of Interconnection NetworksOur analysis in previous sections reveals that it is possible to map denser networks into sparser networks with associated congestion overheads. This implies that a sparser network whose link bandwidth is increased to compensate for the congestion can be expected to perform as well as the denser network (modulo dilation effects). For example, a mesh whose links are faster by a factor of 2.7.2 Cost-Performance TradeoffsWe now examine how various cost metrics can be used to investigate cost-performance tradeoffs in interconnection networks. We illustrate this by analyzing the performance of a mesh and a hypercube network with identical costs. If the cost of a network is proportional to the number of wires, then a square p-node wraparound mesh with (log p)/4 wires per channel costs as much as a p-node hypercube with one wire per channel. Let us compare the average communication times of these two networks. The average distance lav between any two nodes in a two-dimensional wraparound mesh is Let us now investigate the behavior of these expressions. For a fixed number of nodes, as the message size is increased, the communication term due to tw dominates. Comparing tw for the two networks, we see that the time for a wraparound mesh (4twm/(log p))is less than the time for a hypercube (twm)if p is greater than 16 and the message size m is sufficiently large. Under these circumstances, point-to-point communication of large messages between random pairs of nodes takes less time on a wraparound mesh with cut-through routing than on a hypercube of the same cost. Furthermore, for algorithms in which communication is suited to a mesh, the extra bandwidth of each channel results in better performance. Note that, with store-and-forward routing, the mesh is no longer more cost-efficient than a hypercube. Similar cost-performance tradeoffs can be analyzed for the general case of k-ary d-cubes (Problems 2.25-2.29). The communication times above are computed under light load conditions in the network. As the number of messages increases, there is contention on the network. Contention affects the mesh network more adversely than the hypercube network. Therefore, if the network is heavily loaded, the hypercube will outperform the mesh. If the cost of a network is proportional to its bisection width, then a p-node wraparound mesh with |
|
|