|
|
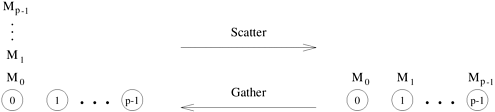
4.4 Scatter and GatherIn the scatter operation, a single node sends a unique message of size m to every other node. This operation is also known as one-to-all personalized communication. One-to-all personalized communication is different from one-to-all broadcast in that the source node starts with p unique messages, one destined for each node. Unlike one-to-all broadcast, one-to-all personalized communication does not involve any duplication of data. The dual of one-to-all personalized communication or the scatter operation is the gather operation, or concatenation, in which a single node collects a unique message from each node. A gather operation is different from an all-to-one reduce operation in that it does not involve any combination or reduction of data. Figure 4.14 illustrates the scatter and gather operations. Figure 4.14. Scatter and gather operations.
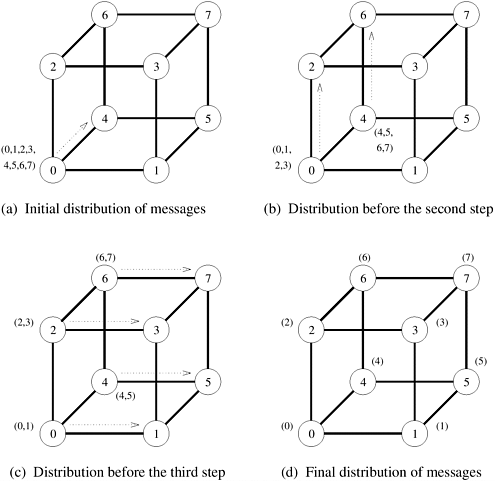
Although the scatter operation is semantically different from one-to-all broadcast, the scatter algorithm is quite similar to that of the broadcast. Figure 4.15 shows the communication steps for the scatter operation on an eight-node hypercube. The communication patterns of one-to-all broadcast (Figure 4.6) and scatter (Figure 4.15) are identical. Only the size and the contents of messages are different. In Figure 4.15, the source node (node 0) contains all the messages. The messages are identified by the labels of their destination nodes. In the first communication step, the source transfers half of the messages to one of its neighbors. In subsequent steps, each node that has some data transfers half of it to a neighbor that has yet to receive any data. There is a total of log p communication steps corresponding to the log p dimensions of the hypercube. Figure 4.15. The scatter operation on an eight-node hypercube.
The gather operation is simply the reverse of scatter. Each node starts with an m word message. In the first step, every odd numbered node sends its buffer to an even numbered neighbor behind it, which concatenates the received message with its own buffer. Only the even numbered nodes participate in the next communication step which results in nodes with multiples of four labels gathering more data and doubling the sizes of their data. The process continues similarly, until node 0 has gathered the entire data. Just like one-to-all broadcast and all-to-one reduction, the hypercube algorithms for scatter and gather can be applied unaltered to linear array and mesh interconnection topologies without any increase in the communication time. Cost Analysis All links of a p-node hypercube along a certain dimension join two p/2-node subcubes (Section 2.4.3). As Figure 4.15 illustrates, in each communication step of the scatter operations, data flow from one subcube to another. The data that a node owns before starting communication in a certain dimension are such that half of them need to be sent to a node in the other subcube. In every step, a communicating node keeps half of its data, meant for the nodes in its subcube, and sends the other half to its neighbor in the other subcube. The time in which all data are distributed to their respective destinations is
The scatter and gather operations can also be performed on a linear array and on a 2-D square mesh in time ts log p + twm(p - 1) (Problem 4.7). Note that disregarding the term due to message-startup time, the cost of scatter and gather operations for large messages on any k-d mesh interconnection network (Section 2.4.3) is similar. In the scatter operation, at least m(p - 1) words of data must be transmitted out of the source node, and in the gather operation, at least m(p - 1) words of data must be received by the destination node. Therefore, as in the case of all-to-all broadcast, twm(p - 1) is a lower bound on the communication time of scatter and gather operations. This lower bound is independent of the interconnection network. |
|
|