4.5 All-to-All Personalized Communication
In all-to-all personalized communication, each node sends a distinct message of size m to every other node. Each node sends different messages to different nodes, unlike all-to-all broadcast, in which each node sends the same message to all other nodes. Figure 4.16 illustrates the all-to-all personalized communication operation. A careful observation of this figure would reveal that this operation is equivalent to transposing a two-dimensional array of data distributed among p processes using one-dimensional array partitioning (Figure 3.24). All-to-all personalized communication is also known as total exchange. This operation is used in a variety of parallel algorithms such as fast Fourier transform, matrix transpose, sample sort, and some parallel database join operations.

Example 4.2 Matrix transposition
The transpose of an n x n matrix A is a matrix AT of the same size, such that AT [i, j] = A[j, i] for 0  i, j < n. Consider an n x n matrix mapped onto n processors such that each processor contains one full row of the matrix. With this mapping, processor Pi initially contains the elements of the matrix with indices [i, 0], [i, 1], ..., [i, n - 1]. After the transposition, element [i, 0] belongs to P0, element [i, 1] belongs to P1, and so on. In general, element [i, j] initially resides on Pi , but moves to Pj during the transposition. The data-communication pattern of this procedure is shown in Figure 4.17 for a 4 x 4 matrix mapped onto four processes using one-dimensional rowwise partitioning. Note that in this figure every processor sends a distinct element of the matrix to every other processor. This is an example of all-to-all personalized communication. i, j < n. Consider an n x n matrix mapped onto n processors such that each processor contains one full row of the matrix. With this mapping, processor Pi initially contains the elements of the matrix with indices [i, 0], [i, 1], ..., [i, n - 1]. After the transposition, element [i, 0] belongs to P0, element [i, 1] belongs to P1, and so on. In general, element [i, j] initially resides on Pi , but moves to Pj during the transposition. The data-communication pattern of this procedure is shown in Figure 4.17 for a 4 x 4 matrix mapped onto four processes using one-dimensional rowwise partitioning. Note that in this figure every processor sends a distinct element of the matrix to every other processor. This is an example of all-to-all personalized communication.
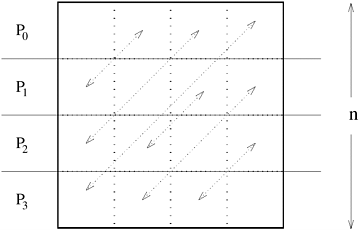
In general, if we use p processes such that p n, then each process initially holds n/p rows (that is, n2/p elements) of the matrix. Performing the transposition now involves an all-to-all personalized communication of matrix blocks of size n/p x n/p, instead of individual elements. 
We now discuss the implementation of all-to-all personalized communication on parallel computers with linear array, mesh, and hypercube interconnection networks. The communication patterns of all-to-all personalized communication are identical to those of all-to-all broadcast on all three architectures. Only the size and the contents of messages are different.
4.5.1 Ring
Figure 4.18 shows the steps in an all-to-all personalized communication on a six-node linear array. To perform this operation, every node sends p - 1 pieces of data, each of size m. In the figure, these pieces of data are identified by pairs of integers of the form {i, j}, where i is the source of the message and j is its final destination. First, each node sends all pieces of data as one consolidated message of size m(p - 1) to one of its neighbors (all nodes communicate in the same direction). Of the m(p - 1) words of data received by a node in this step, one m-word packet belongs to it. Therefore, each node extracts the information meant for it from the data received, and forwards the remaining (p - 2) pieces of size m each to the next node. This process continues for p - 1 steps. The total size of data being transferred between nodes decreases by m words in each successive step. In every step, each node adds to its collection one m-word packet originating from a different node. Hence, in p - 1 steps, every node receives the information from all other nodes in the ensemble.
In the above procedure, all messages are sent in the same direction. If half of the messages are sent in one direction and the remaining half are sent in the other direction, then the communication cost due to the tw can be reduced by a factor of two. For the sake of simplicity, we ignore this constant-factor improvement.
Cost Analysis
On a ring or a bidirectional linear array, all-to-all personalized communication involves p - 1 communication steps. Since the size of the messages transferred in the i th step is m(p - i), the total time taken by this operation is
Equation 4.7
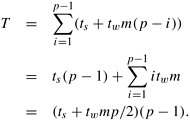
In the all-to-all personalized communication procedure described above, each node sends m(p - 1) words of data because it has an m-word packet for every other node. Assume that all messages are sent either clockwise or counterclockwise. The average distance that an m-word packet travels is 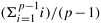 , which is equal to p/2. Since there are p nodes, each performing the same type of communication, the total traffic (the total number of data words transferred between directly-connected nodes) on the network is m(p - 1) x p/2 x p. The total number of inter-node links in the network to share this load is p. Hence, the communication time for this operation is at least (tw x m(p - 1)p2/2)/p, which is equal to twm(p - 1)p/2. Disregarding the message startup time ts, this is exactly the time taken by the linear array procedure. Therefore, the all-to-all personalized communication algorithm described in this section is optimal. , which is equal to p/2. Since there are p nodes, each performing the same type of communication, the total traffic (the total number of data words transferred between directly-connected nodes) on the network is m(p - 1) x p/2 x p. The total number of inter-node links in the network to share this load is p. Hence, the communication time for this operation is at least (tw x m(p - 1)p2/2)/p, which is equal to twm(p - 1)p/2. Disregarding the message startup time ts, this is exactly the time taken by the linear array procedure. Therefore, the all-to-all personalized communication algorithm described in this section is optimal.
4.5.2 Mesh
In all-to-all personalized communication on a 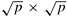 mesh, each node first groups its p messages according to the columns of their destination nodes. Figure 4.19 shows a 3 x 3 mesh, in which every node initially has nine m-word messages, one meant for each node. Each node assembles its data into three groups of three messages each (in general, mesh, each node first groups its p messages according to the columns of their destination nodes. Figure 4.19 shows a 3 x 3 mesh, in which every node initially has nine m-word messages, one meant for each node. Each node assembles its data into three groups of three messages each (in general,  groups of messages each). The first group contains the messages destined for nodes labeled 0, 3, and 6; the second group contains the messages for nodes labeled 1, 4, and 7; and the last group has messages for nodes labeled 2, 5, and 8. groups of messages each). The first group contains the messages destined for nodes labeled 0, 3, and 6; the second group contains the messages for nodes labeled 1, 4, and 7; and the last group has messages for nodes labeled 2, 5, and 8.
After the messages are grouped, all-to-all personalized communication is performed independently in each row with clustered messages of size 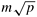 . One cluster contains the information for all nodes of a particular column. Figure 4.19(b) shows the distribution of data among the nodes at the end of this phase of communication. . One cluster contains the information for all nodes of a particular column. Figure 4.19(b) shows the distribution of data among the nodes at the end of this phase of communication.
Before the second communication phase, the messages in each node are sorted again, this time according to the rows of their destination nodes; then communication similar to the first phase takes place in all the columns of the mesh. By the end of this phase, each node receives a message from every other node.
Cost Analysis
We can compute the time spent in the first phase by substituting for the number of nodes, and for the message size in Equation 4.7. The result of this substitution is 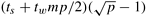 . The time spent in the second phase is the same as that in the first phase. Therefore, the total time for all-to-all personalized communication of messages of size m on a p-node two-dimensional square mesh is . The time spent in the second phase is the same as that in the first phase. Therefore, the total time for all-to-all personalized communication of messages of size m on a p-node two-dimensional square mesh is
Equation 4.8
The expression for the communication time of all-to-all personalized communication in Equation 4.8 does not take into account the time required for the local rearrangement of data (that is, sorting the messages by rows or columns). Assuming that initially the data is ready for the first communication phase, the second communication phase requires the rearrangement of mp words of data. If tr is the time to perform a read and a write operation on a single word of data in a node's local memory, then the total time spent in data rearrangement by a node during the entire procedure is trmp (Problem 4.21). This time is much smaller than the time spent by each node in communication.
An analysis along the lines of that for the linear array would show that the communication time given by Equation 4.8 for all-to-all personalized communication on a square mesh is optimal within a small constant factor (Problem 4.11).
4.5.3 Hypercube
One way of performing all-to-all personalized communication on a p-node hypercube is to simply extend the two-dimensional mesh algorithm to log p dimensions. Figure 4.20 shows the communication steps required to perform this operation on a three-dimensional hypercube. As shown in the figure, communication takes place in log p steps. Pairs of nodes exchange data in a different dimension in each step. Recall that in a p-node hypercube, a set of p/2 links in the same dimension connects two subcubes of p/2 nodes each (Section 2.4.3). At any stage in all-to-all personalized communication, every node holds p packets of size m each. While communicating in a particular dimension, every node sends p/2 of these packets (consolidated as one message). The destinations of these packets are the nodes of the other subcube connected by the links in current dimension.
In the preceding procedure, a node must rearrange its messages locally before each of the log p communication steps. This is necessary to make sure that all p/2 messages destined for the same node in a communication step occupy contiguous memory locations so that they can be transmitted as a single consolidated message.
Cost Analysis
In the above hypercube algorithm for all-to-all personalized communication, mp/2 words of data are exchanged along the bidirectional channels in each of the log p iterations. The resulting total communication time is
Equation 4.9
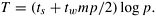
Before each of the log p communication steps, a node rearranges mp words of data. Hence, a total time of trmp log p is spent by each node in local rearrangement of data during the entire procedure. Here tr is the time needed to perform a read and a write operation on a single word of data in a node's local memory. For most practical computers, tr is much smaller than tw; hence, the time to perform an all-to-all personalized communication is dominated by the communication time.
Interestingly, unlike the linear array and mesh algorithms described in this section, the hypercube algorithm is not optimal. Each of the p nodes sends and receives m(p - 1) words of data and the average distance between any two nodes on a hypercube is (log p)/2. Therefore, the total data traffic on the network is p x m(p - 1) x (log p)/2. Since there is a total of (p log p)/2 links in the hypercube network, the lower bound on the all-to-all personalized communication time is
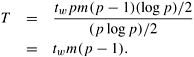
An Optimal Algorithm
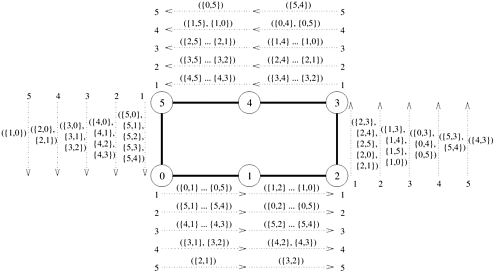
An all-to-all personalized communication effectively results in all pairs of nodes exchanging some data. On a hypercube, the best way to perform this exchange is to have every pair of nodes communicate directly with each other. Thus, each node simply performs p - 1 communication steps, exchanging m words of data with a different node in every step. A node must choose its communication partner in each step so that the hypercube links do not suffer congestion. Figure 4.21 shows one such congestion-free schedule for pairwise exchange of data in a three-dimensional hypercube. As the figure shows, in the j th communication step, node i exchanges data with node (i XOR j). For example, in part (a) of the figure (step 1), the labels of communicating partners differ in the least significant bit. In part (g) (step 7), the labels of communicating partners differ in all the bits, as the binary representation of seven is 111. In this figure, all the paths in every communication step are congestion-free, and none of the bidirectional links carry more than one message in the same direction. This is true in general for a hypercube of any dimension. If the messages are routed appropriately, a congestion-free schedule exists for the p - 1 communication steps of all-to-all personalized communication on a p-node hypercube. Recall from Section 2.4.3 that a message traveling from node i to node j on a hypercube must pass through at least l links, where l is the Hamming distance between i and j (that is, the number of nonzero bits in the binary representation of (i XOR j)). A message traveling from node i to node j traverses links in l dimensions (corresponding to the nonzero bits in the binary representation of (i XOR j)). Although the message can follow one of the several paths of length l that exist between i and j (assuming l > 1), a distinct path is obtained by sorting the dimensions along which the message travels in ascending order. According to this strategy, the first link is chosen in the dimension corresponding to the least significant nonzero bit of (i XOR j), and so on. This routing scheme is known as E-cube routing.
Algorithm 4.10 for all-to-all personalized communication on a d-dimensional hypercube is based on this strategy.
Algorithm 4.10 A procedure to perform all-to-all personalized communication on a d-dimensional hypercube. The message Mi,j initially resides on node i and is destined for node j.
1. procedure ALL_TO_ALL_PERSONAL(d, my_id)
2. begin
3. for i := 1 to 2d - 1 do
4. begin
5. partner := my_id XOR i;
6. send Mmy_id, partner to partner;
7. receive Mpartner,my_id from partner;
8. endfor;
9. end ALL_TO_ALL_PERSONAL
Cost Analysis
E-cube routing ensures that by choosing communication pairs according to Algorithm 4.10, a communication time of ts + twm is guaranteed for a message transfer between node i and node j because there is no contention with any other message traveling in the same direction along the link between nodes i and j. The total communication time for the entire operation is
Equation 4.10
A comparison of Equations 4.9 and 4.10 shows the term associated with ts is higher for the second hypercube algorithm, while the term associated with tw is higher for the first algorithm. Therefore, for small messages, the startup time may dominate, and the first algorithm may still be useful.
|