|
|
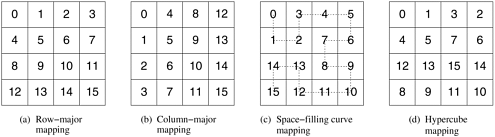
6.4 Topologies and EmbeddingMPI views the processes as being arranged in a one-dimensional topology and uses a linear ordering to number the processes. However, in many parallel programs, processes are naturally arranged in higher-dimensional topologies (e.g., two- or three-dimensional). In such programs, both the computation and the set of interacting processes are naturally identified by their coordinates in that topology. For example, in a parallel program in which the processes are arranged in a two-dimensional topology, process (i, j) may need to send message to (or receive message from) process (k, l). To implement these programs in MPI, we need to map each MPI process to a process in that higher-dimensional topology. Many such mappings are possible. Figure 6.5 illustrates some possible mappings of eight MPI processes onto a 4 x 4 two-dimensional topology. For example, for the mapping shown in Figure 6.5(a), an MPI process with rank rank corresponds to process (row, col) in the grid such that row = rank/4 and col = rank%4 (where '%' is C's module operator). As an illustration, the process with rank 7 is mapped to process (1, 3) in the grid. Figure 6.5. Different ways to map a set of processes to a two-dimensional grid. (a) and (b) show a row- and column-wise mapping of these processes, (c) shows a mapping that follows a space-filling curve (dotted line), and (d) shows a mapping in which neighboring processes are directly connected in a hypercube.
In general, the goodness of a mapping is determined by the pattern of interaction among the processes in the higher-dimensional topology, the connectivity of physical processors, and the mapping of MPI processes to physical processors. For example, consider a program that uses a two-dimensional topology and each process needs to communicate with its neighboring processes along the x and y directions of this topology. Now, if the processors of the underlying parallel system are connected using a hypercube interconnection network, then the mapping shown in Figure 6.5(d) is better, since neighboring processes in the grid are also neighboring processors in the hypercube topology. However, the mechanism used by MPI to assign ranks to the processes in a communication domain does not use any information about the interconnection network, making it impossible to perform topology embeddings in an intelligent manner. Furthermore, even if we had that information, we will need to specify different mappings for different interconnection networks, diminishing the architecture independent advantages of MPI. A better approach is to let the library itself compute the most appropriate embedding of a given topology to the processors of the underlying parallel computer. This is exactly the approach facilitated by MPI. MPI provides a set of routines that allows the programmer to arrange the processes in different topologies without having to explicitly specify how these processes are mapped onto the processors. It is up to the MPI library to find the most appropriate mapping that reduces the cost of sending and receiving messages. 6.4.1 Creating and Using Cartesian TopologiesMPI provides routines that allow the specification of virtual process topologies of arbitrary connectivity in terms of a graph. Each node in the graph corresponds to a process and two nodes are connected if they communicate with each other. Graphs of processes can be used to specify any desired topology. However, most commonly used topologies in message-passing programs are one-, two-, or higher-dimensional grids, that are also referred to as Cartesian topologies. For this reason, MPI provides a set of specialized routines for specifying and manipulating this type of multi-dimensional grid topologies. MPI's function for describing Cartesian topologies is called MPI_Cart_create. Its calling sequence is as follows.
int MPI_Cart_create(MPI_Comm comm_old, int ndims, int *dims,
int *periods, int reorder, MPI_Comm *comm_cart)
This function takes the group of processes that belong to the communicator comm_old and creates a virtual process topology. The topology information is attached to a new communicator comm_cart that is created by MPI_Cart_create. Any subsequent MPI routines that want to take advantage of this new Cartesian topology must use comm_cart as the communicator argument. Note that all the processes that belong to the comm_old communicator must call this function. The shape and properties of the topology are specified by the arguments ndims, dims, and periods. The argument ndims specifies the number of dimensions of the topology. The array dims specify the size along each dimension of the topology. The i th element of this array stores the size of the i th dimension of the topology. The array periods is used to specify whether or not the topology has wraparound connections. In particular, if periods[i] is true (non-zero in C), then the topology has wraparound connections along dimension i, otherwise it does not. Finally, the argument reorder is used to determine if the processes in the new group (i.e., communicator) are to be reordered or not. If reorder is false, then the rank of each process in the new group is identical to its rank in the old group. Otherwise, MPI_Cart_create may reorder the processes if that leads to a better embedding of the virtual topology onto the parallel computer. If the total number of processes specified in the dims array is smaller than the number of processes in the communicator specified by comm_old, then some processes will not be part of the Cartesian topology. For this set of processes, the value of comm_cart will be set to MPI_COMM_NULL (an MPI defined constant). Note that it will result in an error if the total number of processes specified by dims is greater than the number of processes in the comm_old communicator. Process Naming When a Cartesian topology is used, each process is better identified by its coordinates in this topology. However, all MPI functions that we described for sending and receiving messages require that the source and the destination of each message be specified using the rank of the process. For this reason, MPI provides two functions, MPI_Cart_rank and MPI_Cart_coord, for performing coordinate-to-rank and rank-to-coordinate translations, respectively. The calling sequences of these routines are the following:
int MPI_Cart_rank(MPI_Comm comm_cart, int *coords, int *rank)
int MPI_Cart_coord(MPI_Comm comm_cart, int rank, int maxdims,
int *coords)
The MPI_Cart_rank takes the coordinates of the process as argument in the coords array and returns its rank in rank. The MPI_Cart_coords takes the rank of the process rank and returns its Cartesian coordinates in the array coords, of length maxdims. Note that maxdims should be at least as large as the number of dimensions in the Cartesian topology specified by the communicator comm_cart. Frequently, the communication performed among processes in a Cartesian topology is that of shifting data along a dimension of the topology. MPI provides the function MPI_Cart_shift, that can be used to compute the rank of the source and destination processes for such operation. The calling sequence of this function is the following:
int MPI_Cart_shift(MPI_Comm comm_cart, int dir, int s_step,
int *rank_source, int *rank_dest)
The direction of the shift is specified in the dir argument, and is one of the dimensions of the topology. The size of the shift step is specified in the s_step argument. The computed ranks are returned in rank_source and rank_dest. If the Cartesian topology was created with wraparound connections (i.e., the periods[dir] entry was set to true), then the shift wraps around. Otherwise, a MPI_PROC_NULL value is returned for rank_source and/or rank_dest for those processes that are outside the topology. 6.4.2 Example: Cannon's Matrix-Matrix MultiplicationTo illustrate how the various topology functions are used we will implement Cannon's algorithm for multiplying two matrices A and B, described in Section 8.2.2. Cannon's algorithm views the processes as being arranged in a virtual two-dimensional square array. It uses this array to distribute the matrices A, B, and the result matrix C in a block fashion. That is, if n x n is the size of each matrix and p is the total number of process, then each matrix is divided into square blocks of size Program 6.2 shows the MPI function that implements Cannon's algorithm. The dimension of the matrices is supplied in the parameter n. The parameters a, b, and c point to the locally stored portions of the matrices A, B, and C, respectively. The size of these arrays is Program 6.2 Cannon's Matrix-Matrix Multiplication with MPI's Topologies
1 MatrixMatrixMultiply(int n, double *a, double *b, double *c,
2 MPI_Comm comm)
3 {
4 int i;
5 int nlocal;
6 int npes, dims[2], periods[2];
7 int myrank, my2drank, mycoords[2];
8 int uprank, downrank, leftrank, rightrank, coords[2];
9 int shiftsource, shiftdest;
10 MPI_Status status;
11 MPI_Comm comm_2d;
12
13 /* Get the communicator related information */
14 MPI_Comm_size(comm, &npes);
15 MPI_Comm_rank(comm, &myrank);
16
17 /* Set up the Cartesian topology */
18 dims[0] = dims[1] = sqrt(npes);
19
20 /* Set the periods for wraparound connections */
21 periods[0] = periods[1] = 1;
22
23 /* Create the Cartesian topology, with rank reordering */
24 MPI_Cart_create(comm, 2, dims, periods, 1, &comm_2d);
25
26 /* Get the rank and coordinates with respect to the new topology */
27 MPI_Comm_rank(comm_2d, &my2drank);
28 MPI_Cart_coords(comm_2d, my2drank, 2, mycoords);
29
30 /* Compute ranks of the up and left shifts */
31 MPI_Cart_shift(comm_2d, 0, -1, &rightrank, &leftrank);
32 MPI_Cart_shift(comm_2d, 1, -1, &downrank, &uprank);
33
34 /* Determine the dimension of the local matrix block */
35 nlocal = n/dims[0];
36
37 /* Perform the initial matrix alignment. First for A and then for B */
38 MPI_Cart_shift(comm_2d, 0, -mycoords[0], &shiftsource, &shiftdest);
39 MPI_Sendrecv_replace(a, nlocal*nlocal, MPI_DOUBLE, shiftdest,
40 1, shiftsource, 1, comm_2d, &status);
41
42 MPI_Cart_shift(comm_2d, 1, -mycoords[1], &shiftsource, &shiftdest);
43 MPI_Sendrecv_replace(b, nlocal*nlocal, MPI_DOUBLE,
44 shiftdest, 1, shiftsource, 1, comm_2d, &status);
45
46 /* Get into the main computation loop */
47 for (i=0; i<dims[0]; i++) {
48 MatrixMultiply(nlocal, a, b, c); /*c=c+a*b*/
49
50 /* Shift matrix a left by one */
51 MPI_Sendrecv_replace(a, nlocal*nlocal, MPI_DOUBLE,
52 leftrank, 1, rightrank, 1, comm_2d, &status);
53
54 /* Shift matrix b up by one */
55 MPI_Sendrecv_replace(b, nlocal*nlocal, MPI_DOUBLE,
56 uprank, 1, downrank, 1, comm_2d, &status);
57 }
58
59 /* Restore the original distribution of a and b */
60 MPI_Cart_shift(comm_2d, 0, +mycoords[0], &shiftsource, &shiftdest);
61 MPI_Sendrecv_replace(a, nlocal*nlocal, MPI_DOUBLE,
62 shiftdest, 1, shiftsource, 1, comm_2d, &status);
63
64 MPI_Cart_shift(comm_2d, 1, +mycoords[1], &shiftsource, &shiftdest);
65 MPI_Sendrecv_replace(b, nlocal*nlocal, MPI_DOUBLE,
66 shiftdest, 1, shiftsource, 1, comm_2d, &status);
67
68 MPI_Comm_free(&comm_2d); /* Free up communicator */
69 }
70
71 /* This function performs a serial matrix-matrix multiplication c = a*b */
72 MatrixMultiply(int n, double *a, double *b, double *c)
73 {
74 int i, j, k;
75
76 for (i=0; i<n; i++)
77 for (j=0; j<n; j++)
78 for (k=0; k<n; k++)
79 c[i*n+j] += a[i*n+k]*b[k*n+j];
80 }
|
|
|