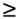|
|
8.2 Matrix-Matrix MultiplicationThis section discusses parallel algorithms for multiplying two n x n dense, square matrices A and B to yield the product matrix C = A x B. All parallel matrix multiplication algorithms in this chapter are based on the conventional serial algorithm shown in Algorithm 8.2. If we assume that an addition and multiplication pair (line 8) takes unit time, then the sequential run time of this algorithm is n3. Matrix multiplication algorithms with better asymptotic sequential complexities are available, for example Strassen's algorithm. However, for the sake of simplicity, in this book we assume that the conventional algorithm is the best available serial algorithm. Problem 8.5 explores the performance of parallel matrix multiplication regarding Strassen's method as the base algorithm. Algorithm 8.2 The conventional serial algorithm for multiplication of two n x n matrices.1. procedure MAT_MULT (A, B, C) 2. begin 3. for i := 0 to n - 1 do 4. for j := 0 to n - 1 do 5. begin 6. C[i, j] := 0; 7. for k := 0 to n - 1 do 8. C[i, j] := C[i, j] + A[i, k] x B[k, j]; 9. endfor; 10. end MAT_MULT Algorithm 8.3 The block matrix multiplication algorithm for n x n matrices with a block size of (n/q) x (n/q).1. procedure BLOCK_MAT_MULT (A, B, C) 2. begin 3. for i := 0 to q - 1 do 4. for j := 0 to q - 1 do 5. begin 6. Initialize all elements of Ci,j to zero; 7. for k := 0 to q - 1 do 8. Ci,j := Ci,j + Ai,k x Bk,j; 9. endfor; 10. end BLOCK_MAT_MULT A concept that is useful in matrix multiplication as well as in a variety of other matrix algorithms is that of block matrix operations. We can often express a matrix computation involving scalar algebraic operations on all its elements in terms of identical matrix algebraic operations on blocks or submatrices of the original matrix. Such algebraic operations on the submatrices are called block matrix operations. For example, an n x n matrix A can be regarded as a q x q array of blocks Ai,j (0 In the following sections, we describe a few ways of parallelizing Algorithm 8.3. Each of the following parallel matrix multiplication algorithms uses a block 2-D partitioning of the matrices. 8.2.1 A Simple Parallel AlgorithmConsider two n x n matrices A and B partitioned into p blocks Ai,j and Bi,j
Performance and Scalability Analysis
The algorithm requires two all-to-all broadcast steps (each consisting of
The process-time product is The isoefficiency functions due to ts and tw are ts p log p and 8(tw)3p3/2, respectively. Hence, the overall isoefficiency function due to the communication overhead is Q(p3/2). This algorithm can use a maximum of n2 processes; hence, p A notable drawback of this algorithm is its excessive memory requirements. At the end of the communication phase, each process has 8.2.2 Cannon's AlgorithmCannon's algorithm is a memory-efficient version of the simple algorithm presented in Section 8.2.1. To study this algorithm, we again partition matrices A and B into p square blocks. We label the processes from P0,0 to Figure 8.3. The communication steps in Cannon's algorithm on 16 processes.
The first communication step of the algorithm aligns the blocks of A and B in such a way that each process multiplies its local submatrices. As Figure 8.3(a) shows, this alignment is achieved for matrix A by shifting all submatrices Ai,j to the left (with wraparound) by i steps. Similarly, as shown in Figure 8.3(b), all submatrices Bi,j are shifted up (with wraparound) by j steps. These are circular shift operations (Section 4.6) in each row and column of processes, which leave process Pi,j with submatrices
Performance Analysis
The initial alignment of the two matrices (Figure 8.3(a) and (b)) involves a rowwise and a columnwise circular shift. In any of these shifts, the maximum distance over which a block shifts is Each process performs
The cost-optimality condition for Cannon's algorithm is identical to that for the simple algorithm presented in Section 8.2.1. As in the simple algorithm, the isoefficiency function of Cannon's algorithm is Q(p3/2). 8.2.3 The DNS AlgorithmThe matrix multiplication algorithms presented so far use block 2-D partitioning of the input and the output matrices and use a maximum of n2 processes for n x n matrices. As a result, these algorithms have a parallel run time of W(n) because there are Q(n3) operations in the serial algorithm. We now present a parallel algorithm based on partitioning intermediate data that can use up to n3 processes and that performs matrix multiplication in time Q(log n) by using W(n3/log n) processes. This algorithm is known as the DNS algorithm because it is due to Dekel, Nassimi, and Sahni. We first introduce the basic idea, without concern for inter-process communication. Assume that n3 processes are available for multiplying two n x n matrices. These processes are arranged in a three-dimensional n x n x n logical array. Since the matrix multiplication algorithm performs n3 scalar multiplications, each of the n3 processes is assigned a single scalar multiplication. The processes are labeled according to their location in the array, and the multiplication A[i, k] x B[k, j] is assigned to process Pi,j,k (0 We now describe a practical parallel implementation of matrix multiplication based on this idea. As Figure 8.4 shows, the process arrangement can be visualized as n planes of n x n processes each. Each plane corresponds to a different value of k. Initially, as shown in Figure 8.4(a), the matrices are distributed among the n2 processes of the plane corresponding to k = 0 at the base of the three-dimensional process array. Process Pi,j,0 initially owns A[i, j] and B[i, j]. Figure 8.4. The communication steps in the DNS algorithm while multiplying 4 x 4 matrices A and B on 64 processes. The shaded processes in part (c) store elements of the first row of A and the shaded processes in part (d) store elements of the first column of B.
The vertical column of processes Pi,j,* computes the dot product of row A[i, *] and column B[*, j]. Therefore, rows of A and columns of B need to be moved appropriately so that each vertical column of processes Pi,j,* has row A[i, *] and column B[*, j]. More precisely, process Pi,j,k should have A[i, k] and B[k, j]. The communication pattern for distributing the elements of matrix A among the processes is shown in Figure 8.4(a)-(c). First, each column of A moves to a different plane such that the j th column occupies the same position in the plane corresponding to k = j as it initially did in the plane corresponding to k = 0. The distribution of A after moving A[i, j] from Pi,j,0 to Pi,j,j is shown in Figure 8.4(b). Now all the columns of A are replicated n times in their respective planes by a parallel one-to-all broadcast along the j axis. The result of this step is shown in Figure 8.4(c), in which the n processes Pi,0,j, Pi,1,j, ..., Pi,n-1,j receive a copy of A[i, j] from Pi,j,j. At this point, each vertical column of processes Pi,j,* has row A[i, *]. More precisely, process Pi,j,k has A[i, k]. For matrix B, the communication steps are similar, but the roles of i and j in process subscripts are switched. In the first one-to-one communication step, B[i, j] is moved from Pi,j,0 to Pi,j,i. Then it is broadcast from Pi,j,i among P0,j,i, P1,j,i, ..., Pn-1,j,i. The distribution of B after this one-to-all broadcast along the i axis is shown in Figure 8.4(d). At this point, each vertical column of processes Pi,j,* has column B[*, j]. Now process Pi,j,k has B[k, j], in addition to A[i, k]. After these communication steps, A[i, k] and B[k, j] are multiplied at Pi,j,k. Now each element C[i, j] of the product matrix is obtained by an all-to-one reduction along the k axis. During this step, process Pi,j,0 accumulates the results of the multiplication from processes Pi,j,1, ..., Pi,j,n-1. Figure 8.4 shows this step for C[0, 0]. The DNS algorithm has three main communication steps: (1) moving the columns of A and the rows of B to their respective planes, (2) performing one-to-all broadcast along the j axis for A and along the i axis for B, and (3) all-to-one reduction along the k axis. All these operations are performed within groups of n processes and take time Q(log n). Thus, the parallel run time for multiplying two n x n matrices using the DNS algorithm on n3 processes is Q(log n). DNS Algorithm with Fewer than n3 ProcessesThe DNS algorithm is not cost-optimal for n3 processes, since its process-time product of Q(n3 log n) exceeds the Q(n3) sequential complexity of matrix multiplication. We now present a cost-optimal version of this algorithm that uses fewer than n3 processes. Another variant of the DNS algorithm that uses fewer than n3 processes is described in Problem 8.6. Assume that the number of processes p is equal to q3 for some q < n. To implement the DNS algorithm, the two matrices are partitioned into blocks of size (n/q) x (n/q). Each matrix can thus be regarded as a q x q two-dimensional square array of blocks. The implementation of this algorithm on q3 processes is very similar to that on n3 processes. The only difference is that now we operate on blocks rather than on individual elements. Since 1 Performance Analysis The first one-to-one communication step is performed for both A and B, and takes time ts + tw(n/q)2 for each matrix. The second step of one-to-all broadcast is also performed for both matrices and takes time ts log q + tw(n/q)2 log q for each matrix. The final all-to-one reduction is performed only once (for matrix C)and takes time ts log q + tw(n/q)2 log q. The multiplication of (n/q) x (n/q) submatrices by each process takes time (n/q)3. We can ignore the communication time for the first one-to-one communication step because it is much smaller than the communication time of one-to-all broadcasts and all-to-one reduction. We can also ignore the computation time for addition in the final reduction phase because it is of a smaller order of magnitude than the computation time for multiplying the submatrices. With these assumptions, we get the following approximate expression for the parallel run time of the DNS algorithm:
Since q = p1/3, we get
The total cost of this parallel algorithm is n3 + ts p log p + twn2 p1/3 log p. The isoefficiency function is Q(p(log p)3). The algorithm is cost-optimal for n3 = W(p(log p)3), or p = O(n3/(log n)3). |
|
|