|
|
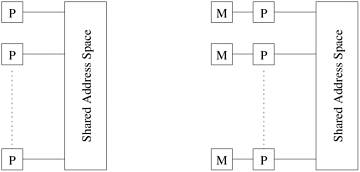
7.1 Thread BasicsA thread is a single stream of control in the flow of a program. We initiate threads with a simple example: Example 7.1 What are threads? Consider the following code segment that computes the product of two dense matrices of size n x n. 1 for (row = 0; row < n; row++) 2 for (column = 0; column < n; column++) 3 c[row][column] = 4 dot_product(get_row(a, row), 5 get_col(b, col)); The for loop in this code fragment has n2 iterations, each of which can be executed independently. Such an independent sequence of instructions is referred to as a thread. In the example presented above, there are n2 threads, one for each iteration of the for-loop. Since each of these threads can be executed independently of the others, they can be scheduled concurrently on multiple processors. We can transform the above code segment as follows: 1 for (row = 0; row < n; row++) 2 for (column = 0; column < n; column++) 3 c[row][column] = 4 create_thread(dot_product(get_row(a, row), 5 get_col(b, col))); Here, we use a function, create_thread, to provide a mechanism for specifying a C function as a thread. The underlying system can then schedule these threads on multiple processors. Logical Memory Model of a Thread To execute the code fragment in Example 7.1 on multiple processors, each processor must have access to matrices a, b, and c. This is accomplished via a shared address space (described in Chapter 2). All memory in the logical machine model of a thread is globally accessible to every thread as illustrated in Figure 7.1(a). However, since threads are invoked as function calls, the stack corresponding to the function call is generally treated as being local to the thread. This is due to the liveness considerations of the stack. Since threads are scheduled at runtime (and no a priori schedule of their execution can be safely assumed), it is not possible to determine which stacks are live. Therefore, it is considered poor programming practice to treat stacks (thread-local variables) as global data. This implies a logical machine model illustrated in Figure 7.1(b), where memory modules M hold thread-local (stack allocated) data. Figure 7.1. The logical machine model of a thread-based programming paradigm.
While this logical machine model gives the view of an equally accessible address space, physical realizations of this model deviate from this assumption. In distributed shared address space machines such as the Origin 2000, the cost to access a physically local memory may be an order of magnitude less than that of accessing remote memory. Even in architectures where the memory is truly equally accessible to all processors (such as shared bus architectures with global shared memory), the presence of caches with processors skews memory access time. Issues of locality of memory reference become important for extracting performance from such architectures. |
|
|