|
|
7.4 Thread Basics: Creation and TerminationLet us start our discussion with a simple threaded program for computing the value of p. Example 7.2 Threaded program for computing p The method we use here is based on generating random numbers in a unit length square and counting the number of points that fall within the largest circle inscribed in the square. Since the area of the circle (p r2) is equal to p/4, and the area of the square is 1 x 1, the fraction of random points that fall in the circle should approach p/4. A simple threaded strategy for generating the value of p assigns a fixed number of points to each thread. Each thread generates these random points and keeps track of the number of points that land in the circle locally. After all threads finish execution, their counts are combined to compute the value of p (by calculating the fraction over all threads and multiplying by 4). To implement this threaded program, we need a function for creating threads and waiting for all threads to finish execution (so we can accrue count). Threads can be created in the Pthreads API using the function pthread_create. The prototype of this function is: 1 #include <pthread.h> 2 int 3 pthread_create ( 4 pthread_t *thread_handle, 5 const pthread_attr_t *attribute, 6 void * (*thread_function)(void *), 7 void *arg); The pthread_create function creates a single thread that corresponds to the invocation of the function thread_function (and any other functions called by thread_function). On successful creation of a thread, a unique identifier is associated with the thread and assigned to the location pointed to by thread_handle. The thread has the attributes described by the attribute argument. When this argument is NULL, a thread with default attributes is created. We will discuss the attribute parameter in detail in Section 7.6. The arg field specifies a pointer to the argument to function thread_function. This argument is typically used to pass the workspace and other thread-specific data to a thread. In the compute_pi example, it is used to pass an integer id that is used as a seed for randomization. The thread_handle variable is written before the the function pthread_create returns; and the new thread is ready for execution as soon as it is created. If the thread is scheduled on the same processor, the new thread may, in fact, preempt its creator. This is important to note because all thread initialization procedures must be completed before creating the thread. Otherwise, errors may result based on thread scheduling. This is a very common class of errors caused by race conditions for data access that shows itself in some execution instances, but not in others. On successful creation of a thread, pthread_create returns 0; else it returns an error code. The reader is referred to the Pthreads specification for a detailed description of the error-codes. In our program for computing the value of p, we first read in the desired number of threads, num threads, and the desired number of sample points, sample_points. These points are divided equally among the threads. The program uses an array, hits, for assigning an integer id to each thread (this id is used as a seed for randomizing the random number generator). The same array is used to keep track of the number of hits (points inside the circle) encountered by each thread upon return. The program creates num_threads threads, each invoking the function compute_pi, using the pthread_create function. Once the respective compute_pi threads have generated assigned number of random points and computed their hit ratios, the results must be combined to determine p. The main program must wait for the threads to run to completion. This is done using the function pthread_join which suspends execution of the calling thread until the specified thread terminates. The prototype of the pthread_join function is as follows: 1 int 2 pthread_join ( 3 pthread_t thread, 4 void **ptr); A call to this function waits for the termination of the thread whose id is given by thread. On a successful call to pthread_join, the value passed to pthread_exit is returned in the location pointed to by ptr. On successful completion, pthread_join returns 0, else it returns an error-code. Once all threads have joined, the value of p is computed by multiplying the combined hit ratio by 4.0. The complete program is as follows:
1 #include <pthread.h>
2 #include <stdlib.h>
3
4 #define MAX_THREADS 512
5 void *compute_pi (void *);
6
7 int total_hits, total_misses, hits[MAX_THREADS],
8 sample_points, sample_points_per_thread, num_threads;
9
10 main() {
11 int i;
12 pthread_t p_threads[MAX_THREADS];
13 pthread_attr_t attr;
14 double computed_pi;
15 double time_start, time_end;
16 struct timeval tv;
17 struct timezone tz;
18
19 pthread_attr_init (&attr);
20 pthread_attr_setscope (&attr,PTHREAD_SCOPE_SYSTEM);
21 printf("Enter number of sample points: ");
22 scanf("%d", &sample_points);
23 printf("Enter number of threads: ");
24 scanf("%d", &num_threads);
25
26 gettimeofday(&tv, &tz);
27 time_start = (double)tv.tv_sec +
28 (double)tv.tv_usec / 1000000.0;
29
30 total_hits = 0;
31 sample_points_per_thread = sample_points / num_threads;
32 for (i=0; i< num_threads; i++) {
33 hits[i] = i;
34 pthread_create(&p_threads[i], &attr, compute_pi,
35 (void *) &hits[i]);
36 }
37 for (i=0; i< num_threads; i++) {
38 pthread_join(p_threads[i], NULL);
39 total_hits += hits[i];
40 }
41 computed_pi = 4.0*(double) total_hits /
42 ((double)(sample_points));
43 gettimeofday(&tv, &tz);
44 time_end = (double)tv.tv_sec +
45 (double)tv.tv_usec / 1000000.0;
46
47 printf("Computed PI = %lf\n", computed_pi);
48 printf(" %lf\n", time_end - time_start);
49 }
50
51 void *compute_pi (void *s) {
52 int seed, i, *hit_pointer;
53 double rand_no_x, rand_no_y;
54 int local_hits;
55
56 hit_pointer = (int *) s;
57 seed = *hit_pointer;
58 local_hits = 0;
59 for (i = 0; i < sample_points_per_thread; i++) {
60 rand_no_x =(double)(rand_r(&seed))/(double)((2<<14)-1);
61 rand_no_y =(double)(rand_r(&seed))/(double)((2<<14)-1);
62 if (((rand_no_x - 0.5) * (rand_no_x - 0.5) +
63 (rand_no_y - 0.5) * (rand_no_y - 0.5)) < 0.25)
64 local_hits ++;
65 seed *= i;
66 }
67 *hit_pointer = local_hits;
68 pthread_exit(0);
69 }
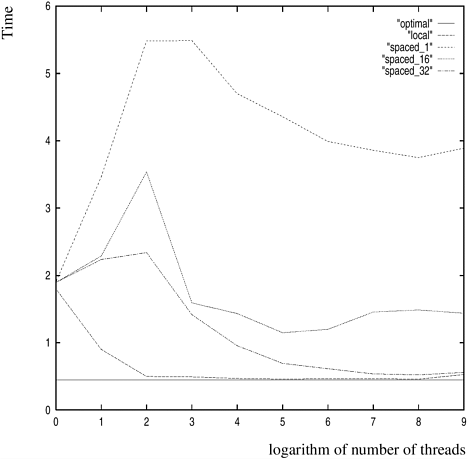
Programming Notes The reader must note, in the above example, the use of the function rand_r (instead of superior random number generators such as drand48). The reason for this is that many functions (including rand and drand48) are not reentrant. Reentrant functions are those that can be safely called when another instance has been suspended in the middle of its invocation. It is easy to see why all thread functions must be reentrant because a thread can be preempted in the middle of its execution. If another thread starts executing the same function at this point, a non-reentrant function might not work as desired. Performance Notes We execute this program on a four-processor SGI Origin 2000. The logarithm of the number of threads and execution time are illustrated in Figure 7.2 (the curve labeled "local"). We can see that at 32 threads, the runtime of the program is roughly 3.91 times less than the corresponding time for one thread. On a four-processor machine, this corresponds to a parallel efficiency of 0.98. Figure 7.2. Execution time of the compute_pi program as a function of number of threads.
The other curves in Figure 7.2 illustrate an important performance overhead called false sharing. Consider the following change to the program: instead of incrementing a local variable, local_hits, and assigning it to the array entry outside the loop, we now directly increment the corresponding entry in the hits array. This can be done by changing line 64 to *(hit_pointer) ++;, and deleting line 67. It is easy to verify that the program is semantically identical to the one before. However, on executing this modified program the observed performance is illustrated in the curve labeled "spaced_1" in Figure 7.2. This represents a significant slowdown instead of a speedup! The drastic impact of this seemingly innocuous change is explained by a phenomenon called false sharing. In this example, two adjoining data items (which likely reside on the same cache line) are being continually written to by threads that might be scheduled on different processors. From our discussion in Chapter 2, we know that a write to a shared cache line results in an invalidate and a subsequent read must fetch the cache line from the most recent write location. With this in mind, we can see that the cache lines corresponding to the hits array generate a large number of invalidates and reads because of repeated increment operations. This situation, in which two threads 'falsely' share data because it happens to be on the same cache line, is called false sharing. It is in fact possible to use this simple example to estimate the cache line size of the system. We change hits to a two-dimensional array and use only the first column of the array to store counts. By changing the size of the second dimension, we can force entries in the first column of the hits array to lie on different cache lines (since arrays in C are stored row-major). The results of this experiment are illustrated in Figure 7.2 by curves labeled "spaced_16" and "spaced_32", in which the second dimension of the hits array is 16 and 32 integers, respectively. It is evident from the figure that as the entries are spaced apart, the performance improves. This is consistent with our understanding that spacing the entries out pushes them into different cache lines, thereby reducing the false sharing overhead. Having understood how to create and join threads, let us now explore mechanisms in Pthreads for synchronizing threads. |
|
|