|
|
9.1 Issues in Sorting on Parallel ComputersParallelizing a sequential sorting algorithm involves distributing the elements to be sorted onto the available processes. This process raises a number of issues that we must address in order to make the presentation of parallel sorting algorithms clearer. 9.1.1 Where the Input and Output Sequences are StoredIn sequential sorting algorithms, the input and the sorted sequences are stored in the process's memory. However, in parallel sorting there are two places where these sequences can reside. They may be stored on only one of the processes, or they may be distributed among the processes. The latter approach is particularly useful if sorting is an intermediate step in another algorithm. In this chapter, we assume that the input and sorted sequences are distributed among the processes. Consider the precise distribution of the sorted output sequence among the processes. A general method of distribution is to enumerate the processes and use this enumeration to specify a global ordering for the sorted sequence. In other words, the sequence will be sorted with respect to this process enumeration. For instance, if Pi comes before Pj in the enumeration, all the elements stored in Pi will be smaller than those stored in Pj . We can enumerate the processes in many ways. For certain parallel algorithms and interconnection networks, some enumerations lead to more efficient parallel formulations than others. 9.1.2 How Comparisons are PerformedA sequential sorting algorithm can easily perform a compare-exchange on two elements because they are stored locally in the process's memory. In parallel sorting algorithms, this step is not so easy. If the elements reside on the same process, the comparison can be done easily. But if the elements reside on different processes, the situation becomes more complicated. One Element Per ProcessConsider the case in which each process holds only one element of the sequence to be sorted. At some point in the execution of the algorithm, a pair of processes (Pi, Pj) may need to compare their elements, ai and aj. After the comparison, Pi will hold the smaller and Pj the larger of {ai, aj}. We can perform comparison by having both processes send their elements to each other. Each process compares the received element with its own and retains the appropriate element. In our example, Pi will keep the smaller and Pj will keep the larger of {ai, aj}. As in the sequential case, we refer to this operation as compare-exchange. As Figure 9.1 illustrates, each compare-exchange operation requires one comparison step and one communication step. Figure 9.1. A parallel compare-exchange operation. Processes Pi and Pj send their elements to each other. Process Pi keeps min{ai, aj}, and Pj keeps max{ai , aj}.
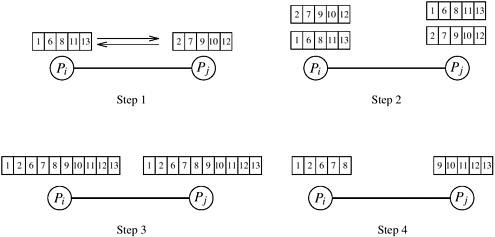
If we assume that processes Pi and Pj are neighbors, and the communication channels are bidirectional, then the communication cost of a compare-exchange step is (ts + tw), where ts and tw are message-startup time and per-word transfer time, respectively. In commercially available message-passing computers, ts is significantly larger than tw, so the communication time is dominated by ts. Note that in today's parallel computers it takes more time to send an element from one process to another than it takes to compare the elements. Consequently, any parallel sorting formulation that uses as many processes as elements to be sorted will deliver very poor performance because the overall parallel run time will be dominated by interprocess communication. More than One Element Per ProcessA general-purpose parallel sorting algorithm must be able to sort a large sequence with a relatively small number of processes. Let p be the number of processes P0, P1, ..., Pp-1, and let n be the number of elements to be sorted. Each process is assigned a block of n/p elements, and all the processes cooperate to sort the sequence. Let A0, A1, ... A p-1 be the blocks assigned to processes P0, P1, ... Pp-1, respectively. We say that Ai As in the one-element-per-process case, two processes Pi and Pj may have to redistribute their blocks of n/p elements so that one of them will get the smaller n/p elements and the other will get the larger n/p elements. Let Ai and Aj be the blocks stored in processes Pi and Pj. If the block of n/p elements at each process is already sorted, the redistribution can be done efficiently as follows. Each process sends its block to the other process. Now, each process merges the two sorted blocks and retains only the appropriate half of the merged block. We refer to this operation of comparing and splitting two sorted blocks as compare-split. The compare-split operation is illustrated in Figure 9.2. Figure 9.2. A compare-split operation. Each process sends its block of size n/p to the other process. Each process merges the received block with its own block and retains only the appropriate half of the merged block. In this example, process Pi retains the smaller elements and process Pj retains the larger elements.
If we assume that processes Pi and Pj are neighbors and that the communication channels are bidirectional, then the communication cost of a compare-split operation is (ts + twn/p). As the block size increases, the significance of ts decreases, and for sufficiently large blocks it can be ignored. Thus, the time required to merge two sorted blocks of n/p elements is Q(n/p). |
|
|