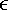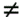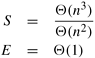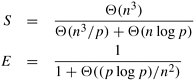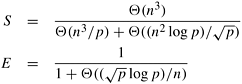|
|
10.4 All-Pairs Shortest PathsInstead of finding the shortest paths from a single vertex v to every other vertex, we are sometimes interested in finding the shortest paths between all pairs of vertices. Formally, given a weighted graph G(V, E, w), the all-pairs shortest paths problem is to find the shortest paths between all pairs of vertices vi, vj The following sections present two algorithms to solve the all-pairs shortest paths problem. The first algorithm uses Dijkstra's single-source shortest paths algorithm, and the second uses Floyd's algorithm. Dijkstra's algorithm requires non-negative edge weights (Problem 10.4), whereas Floyd's algorithm works with graphs having negative-weight edges provided they contain no negative-weight cycles. 10.4.1 Dijkstra's AlgorithmIn Section 10.3 we presented Dijkstra's algorithm for finding the shortest paths from a vertex v to all the other vertices in a graph. This algorithm can also be used to solve the all-pairs shortest paths problem by executing the single-source algorithm on each process, for each vertex v. We refer to this algorithm as Dijkstra's all-pairs shortest paths algorithm. Since the complexity of Dijkstra's single-source algorithm is Q(n2), the complexity of the all-pairs algorithm is Q(n3). Parallel FormulationsDijkstra's all-pairs shortest paths problem can be parallelized in two distinct ways. One approach partitions the vertices among different processes and has each process compute the single-source shortest paths for all vertices assigned to it. We refer to this approach as the source-partitioned formulation. Another approach assigns each vertex to a set of processes and uses the parallel formulation of the single-source algorithm (Section 10.3) to solve the problem on each set of processes. We refer to this approach as the source-parallel formulation. The following sections discuss and analyze these two approaches. Source-Partitioned Formulation The source-partitioned parallel formulation of Dijkstra's algorithm uses n processes. Each process Pi finds the shortest paths from vertex vi to all other vertices by executing Dijkstra's sequential single-source shortest paths algorithm. It requires no interprocess communication (provided that the adjacency matrix is replicated at all processes). Thus, the parallel run time of this formulation is given by
Since the sequential run time is W = Q(n3), the speedup and efficiency are as follows:
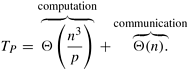
It might seem that, due to the absence of communication, this is an excellent parallel formulation. However, that is not entirely true. The algorithm can use at most n processes. Therefore, the isoefficiency function due to concurrency is Q(p3), which is the overall isoefficiency function of the algorithm. If the number of processes available for solving the problem is small (that is, n = Q(p)), then this algorithm has good performance. However, if the number of processes is greater than n, other algorithms will eventually outperform this algorithm because of its poor scalability. Source-Parallel Formulation The major problem with the source-partitioned parallel formulation is that it can keep only n processes busy doing useful work. Performance can be improved if the parallel formulation of Dijkstra's single-source algorithm (Section 10.3) is used to solve the problem for each vertex v. The source-parallel formulation is similar to the source-partitioned formulation, except that the single-source algorithm runs on disjoint subsets of processes. Specifically, p processes are divided into n partitions, each with p/n processes (this formulation is of interest only if p > n). Each of the n single-source shortest paths problems is solved by one of the n partitions. In other words, we first parallelize the all-pairs shortest paths problem by assigning each vertex to a separate set of processes, and then parallelize the single-source algorithm by using the set of p/n processes to solve it. The total number of processes that can be used efficiently by this formulation is O (n2). The analysis presented in Section 10.3 can be used to derive the performance of this formulation of Dijkstra's all-pairs algorithm. Assume that we have a p-process message-passing computer such that p is a multiple of n. The p processes are partitioned into n groups of size p/n each. If the single-source algorithm is executed on each p/n process group, the parallel run time is
Notice the similarities between Equations 10.3 and 10.2. These similarities are not surprising because each set of p/n processes forms a different group and carries out the computation independently. Thus, the time required by each set of p/n processes to solve the single-source problem determines the overall run time. Since the sequential run time is W = Q(n3), the speedup and efficiency are as follows:
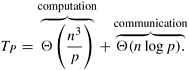
From Equation 10.4 we see that for a cost-optimal formulation p log p/n2 = O (1). Hence, this formulation can use up to O (n2/log n) processes efficiently. Equation 10.4 also shows that the isoefficiency function due to communication is Q((p log p)1.5). The isoefficiency function due to concurrency is Q(p1.5). Thus, the overall isoefficiency function is Q((p log p)1.5). Comparing the two parallel formulations of Dijkstra's all-pairs algorithm, we see that the source-partitioned formulation performs no communication, can use no more than n processes, and solves the problem in time Q(n2). In contrast, the source-parallel formulation uses up to n2/log n processes, has some communication overhead, and solves the problem in time Q(n log n) when n2/log n processes are used. Thus, the source-parallel formulation exploits more parallelism than does the source-partitioned formulation. 10.4.2 Floyd's AlgorithmFloyd's algorithm for solving the all-pairs shortest paths problem is based on the following observation. Let G = (V, E, w) be the weighted graph, and let V = {v1,v2,..., vn} be the vertices of G. Consider a subset {v1, v2,..., vk} of vertices for some k where k
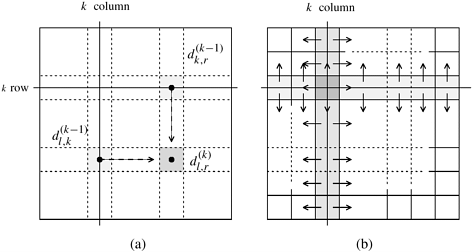
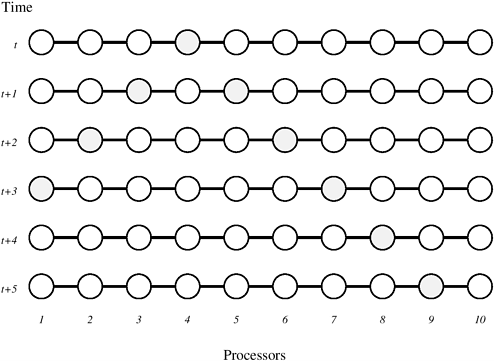
The length of the shortest path from vi to vj is given by Floyd's algorithm solves Equation 10.5 bottom-up in the order of increasing values of k. Algorithm 10.3 shows Floyd's all-pairs algorithm. The run time of Floyd's algorithm is determined by the triple-nested for loops in lines 4-7. Each execution of line 7 takes time Q(1); thus, the complexity of the algorithm is Q(n3). Algorithm 10.3 seems to imply that we must store n matrices of size n xn. However, when computing matrix D(k), only matrix D(k-1) is needed. Consequently, at most two n x n matrices must be stored. Therefore, the overall space complexity is Q(n2). Furthermore, the algorithm works correctly even when only one copy of D is used (Problem 10.6). Algorithm 10.3 Floyd's all-pairs shortest paths algorithm. This program computes the all-pairs shortest paths of the graph G = (V, E ) with adjacency matrix A.1. procedure FLOYD_ALL_PAIRS_SP( A) 2. begin 3. D(0) = A; 4. for k := 1 to n do 5. for i := 1 to n do 6. for j := 1 to n do 7. Parallel FormulationA generic parallel formulation of Floyd's algorithm assigns the task of computing matrix D(k) for each value of k to a set of processes. Let p be the number of processes available. Matrix D(k) is partitioned into p parts, and each part is assigned to a process. Each process computes the D(k) values of its partition. To accomplish this, a process must access the corresponding segments of the kth row and column of matrix D(k-1). The following section describes one technique for partitioning matrix D(k). Another technique is considered in Problem 10.8.
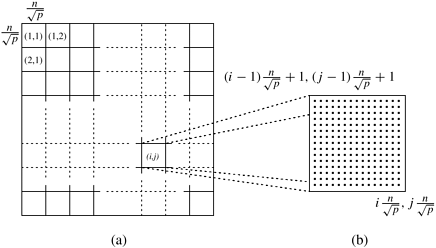
2-D Block Mapping
One way to partition matrix D(k) is to use the 2-D block mapping (Section 3.4.1). Specifically, matrix D(k) is divided into p blocks of size Figure 10.7. (a) Matrix D(k) distributed by 2-D block mapping into
|
|
Maximum Number of Processes for E = Q(1) |
Corresponding Parallel Run Time |
Isoefficiency Function | |
|---|---|---|---|
|
Dijkstra source-partitioned |
Q(n) |
Q(n2) |
Q(p3) |
|
Dijkstra source-parallel |
Q(n2/log n) |
Q(n log n) |
Q((p log p)1.5) |
|
Floyd 1-D block |
Q(n/log n) |
Q(n2 log n) |
Q((p log p)3) |
|
Floyd 2-D block |
Q(n2/log2 n) |
Q(n log2 n) |
Q(p1.5 log3 p) |
|
Floyd pipelined 2-D block |
Q(n2) |
Q(n) |
Q(p1.5) |
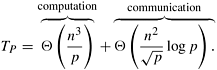
From Equation 10.7 we see that for a cost-optimal formulation p/n2 = O (1). Thus, the pipelined formulation of Floyd's algorithm uses up to O (n2) processes efficiently. Also from Equation 10.7, we can derive the isoefficiency function due to communication, which is Q(p1.5). This is the overall isoefficiency function as well. Comparing the pipelined formulation to the synchronized 2-D block mapping formulation, we see that the former is significantly faster.
The performance of the all-pairs shortest paths algorithms previously presented is summarized in Table 10.1 for a parallel architecture with O (p) bisection bandwidth. Floyd's pipelined formulation is the most scalable and can use up to Q(n2) processes to solve the problem in time Q(n). Moreover, this parallel formulation performs equally well even on architectures with bisection bandwidth O ![]() , such as a mesh-connected computer. Furthermore, its performance is independent of the type of routing (store-and-forward or cut-through).
, such as a mesh-connected computer. Furthermore, its performance is independent of the type of routing (store-and-forward or cut-through).
|
|