11.1 [KGR94] In Section 11.4.1, we identified access to the global pointer, target, as a bottleneck in the GRR load-balancing scheme. Consider a modification of this scheme in which it is augmented with message combining. This scheme works as follows. All the requests to read the value of the global pointer target at processor zero are combined at intermediate processors. Thus, the total number of requests handled by processor zero is greatly reduced. This technique is essentially a software implementation of the fetch-and-add operation. This scheme is called GRR-M (GRR with message combining).
An implementation of this scheme is illustrated in Figure 11.19. Each processor is at a leaf node in a complete (logical) binary tree. Note that such a logical tree can be easily mapped on to a physical topology. When a processor wants to atomically read and increment target, it sends a request up the tree toward processor zero. An internal node of the tree holds a request from one of its children for at most time d, then forwards the message to its parent. If a request comes from the node's other child within time d, the two requests are combined and sent up as a single request. If i is the total number of increment requests that have been combined, the resulting increment of target is i.
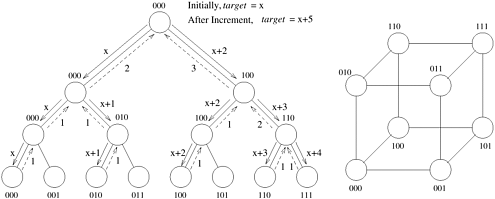
The returned value at each processor is equal to what it would have been if all the requests to target had been serialized. This is done as follows: each combined message is stored in a table at each processor until the request is granted. When the value of target is sent back to an internal node, two values are sent down to the left and right children if both requested a value of target. The two values are determined from the entries in the table corresponding to increment requests by the two children. The scheme is illustrated by Figure 11.19, in which the original value of target is x, and processors P0, P2, P4, P6 and P7 issue requests. The total requested increment is five. After the messages are combined and processed, the value of target received at these processors is x, x + 1, x + 2, x + 3 and x + 4, respectively.
Analyze the performance and scalability of this scheme for a message passing architecture.
11.2 [Lin92] Consider another load-balancing strategy. Assume that each processor maintains a variable called counter. Initially, each processor initializes its local copy of counter to zero. Whenever a processor goes idle, it searches for two processors Pi and Pi +1 in a logical ring embedded into any architecture, such that the value of counter at Pi is greater than that at Pi +1. The idle processor then sends a work request to processor Pi +1. If no such pair of processors exists, the request is sent to processor zero. On receiving a work request, a processor increments its local value of counter.
Devise algorithms to detect the pairs Pi and Pi +1. Analyze the scalability of this load-balancing scheme based on your algorithm to detect the pairs Pi and Pi +1 for a message passing architecture.
Hint: The upper bound on the number of work transfers for this scheme is similar to that for GRR.
11.3 In the analysis of various load-balancing schemes presented in Section 11.4.2, we assumed that the cost of transferring work is independent of the amount of work transferred. However, there are problems for which the work-transfer cost is a function of the amount of work transferred. Examples of such problems are found in tree-search applications for domains in which strong heuristics are available. For such applications, the size of the stack used to represent the search tree can vary significantly with the number of nodes in the search tree.
Consider a case in which the size of the stack for representing a search space of w nodes varies as 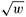 . Assume that the load-balancing scheme used is GRR. Analyze the performance of this scheme for a message passing architecture.
. Assume that the load-balancing scheme used is GRR. Analyze the performance of this scheme for a message passing architecture.
11.4 Consider Dijkstra's token termination detection scheme described in Section 11.4.4. Show that the contribution of termination detection using this scheme to the overall isoefficiency function is O (p2). Comment on the value of the constants associated with this isoefficiency term.
11.5 Consider the tree-based termination detection scheme in Section 11.4.4. In this algorithm, the weights may become very small and may eventually become zero due to the finite precision of computers. In such cases, termination is never signaled. The algorithm can be modified by manipulating the reciprocal of the weight instead of the weight itself. Write the modified termination algorithm and show that it is capable of detecting termination correctly.
11.6 [DM93] Consider a termination detection algorithm in which a spanning tree of minimum diameter is mapped onto the architecture of the given parallel computer. The center of such a tree is a vertex with the minimum distance to the vertex farthest from it. The center of a spanning tree is considered to be its root.
While executing parallel search, a processor can be either idle or busy. The termination detection algorithm requires all work transfers in the system to be acknowledged by an ack message. A processor is busy if it has work, or if it has sent work to another processor and the corresponding ack message has not been received; otherwise the processor is idle. Processors at the leaves of the spanning tree send stop messages to their parent when they become idle. Processors at intermediate levels in the tree pass the stop message on to their parents when they have received stop messages from all their children and they themselves become idle. When the root processor receives stop messages from all its children and becomes idle, termination is signaled.
Since it is possible for a processor to receive work after it has sent a stop message to its parent, a processor signals that it has received work by sending a resume message to its parent. The resume message moves up the tree until it meets the previously issued stop message. On meeting the stop message, the resume message nullifies the stop message. An ack message is then sent to the processor that transferred part of its work.
Show using examples that this termination detection technique correctly signals termination. Determine the isoefficiency term due to this termination detection scheme for a spanning tree of depth log p.
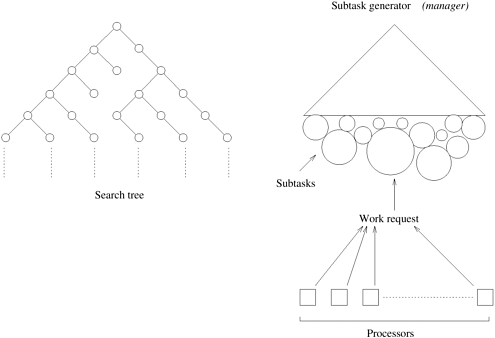
11.7 [FTI90, KN91] Consider the single-level load-balancing scheme which works as follows: a designated processor called manager generates many subtasks and gives them one-by-one to the requesting processors on demand. The manager traverses the search tree depth-first to a predetermined cutoff depth and distributes nodes at that depth as subtasks. Increasing the cutoff depth increases the number of subtasks, but makes them smaller. The processors request another subtask from the manager only after finishing the previous one. Hence, if a processor gets subtasks corresponding to large subtrees, it will send fewer requests to the manager. If the cutoff depth is large enough, this scheme results in good load balance among the processors. However, if the cutoff depth is too large, the subtasks given out to the processors become small and the processors send more frequent requests to the manager. In this case, the manager becomes a bottleneck. Hence, this scheme has a poor scalability. Figure 11.20 illustrates the single-level work-distribution scheme.
Assume that the cost of communicating a piece of work between any two processors is negligible. Derive analytical expressions for the scalability of the single-level load-balancing scheme.
11.8 [FTI90, KN91] Consider the multilevel work-distribution scheme that circumvents the subtask generation bottleneck of the single-level scheme through multiple-level subtask generation. In this scheme, processors are arranged in an m-ary tree of depth d. The task of top-level subtask generation is given to the root processor. It divides the task into super-subtasks and distributes them to its successor processors on demand. These processors subdivide the super-subtasks into subtasks and distribute them to successor processors on request. The leaf processors repeatedly request work from their parents as soon as they have finished their previous work. A leaf processor is allocated to another subtask generator when its designated subtask generator runs out of work. For d = 1, the multi- and single-level schemes are identical. Comment on the performance and scalability of this scheme.
11.9 [FK88] Consider the distributed tree search scheme in which processors are allocated to separate parts of the search tree dynamically. Initially, all the processors are assigned to the root. When the root node is expanded (by one of the processors assigned to it), disjoint subsets of processors at the root are assigned to each successor, in accordance with a selected processor-allocation strategy. One possible processor-allocation strategy is to divide the processors equally among ancestor nodes. This process continues until there is only one processor assigned to a node. At this time, the processor searches the tree rooted at the node sequentially. If a processor finishes searching the search tree rooted at the node, it is reassigned to its parent node. If the parent node has other successor nodes still being explored, then this processor is allocated to one of them. Otherwise, the processor is assigned to its parent. This process continues until the entire tree is searched. Comment on the performance and scalability of this scheme.
11.10 Consider a parallel formulation of best-first search of a graph that uses a hash function to distribute nodes to processors (Section 11.5). The performance of this scheme is influenced by two factors: the communication cost and the number of "good" nodes expanded (a "good" node is one that would also be expanded by the sequential algorithm). These two factors can be analyzed independently of each other.
Assuming a completely random hash function (one in which each node has a probability of being hashed to a processor equal to 1/p), show that the expected number of nodes expanded by this parallel formulation differs from the optimal number by a constant factor (that is, independent of p). Assuming that the cost of communicating a node from one processor to another is O (1), derive the isoefficiency function of this scheme.
11.11 For the parallel formulation in Problem 11.10, assume that the number of nodes expanded by the sequential and parallel formulations are the same. Analyze the communication overhead of this formulation for a message passing architecture. Is the formulation scalable? If so, what is the isoefficiency function? If not, for what interconnection network would the formulation be scalable?
Hint: Note that a fully random hash function corresponds to an all-to-all personalized communication operation, which is bandwidth sensitive.