|
|
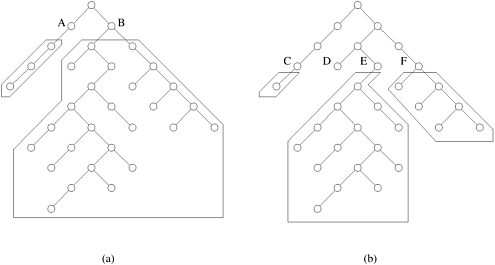
11.4 Parallel Depth-First SearchWe start our discussion of parallel depth-first search by focusing on simple backtracking. Parallel formulations of depth-first branch-and-bound and IDA* are similar to those discussed in this section and are addressed in Sections 11.4.6 and 11.4.7. The critical issue in parallel depth-first search algorithms is the distribution of the search space among the processors. Consider the tree shown in Figure 11.7. Note that the left subtree (rooted at node A) can be searched in parallel with the right subtree (rooted at node B). By statically assigning a node in the tree to a processor, it is possible to expand the whole subtree rooted at that node without communicating with another processor. Thus, it seems that such a static allocation yields a good parallel search algorithm. Figure 11.7. The unstructured nature of tree search and the imbalance resulting from static partitioning.
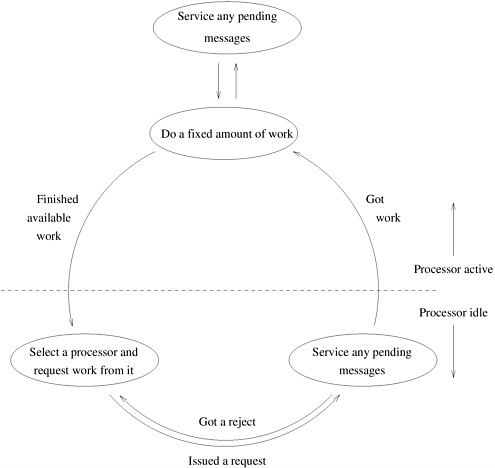
Let us see what happens if we try to apply this approach to the tree in Figure 11.7. Assume that we have two processors. The root node is expanded to generate two nodes (A and B), and each of these nodes is assigned to one of the processors. Each processor now searches the subtrees rooted at its assigned node independently. At this point, the problem with static node assignment becomes apparent. The processor exploring the subtree rooted at node A expands considerably fewer nodes than does the other processor. Due to this imbalance in the workload, one processor is idle for a significant amount of time, reducing efficiency. Using a larger number of processors worsens the imbalance. Consider the partitioning of the tree for four processors. Nodes A and B are expanded to generate nodes C, D, E, and F. Assume that each of these nodes is assigned to one of the four processors. Now the processor searching the subtree rooted at node E does most of the work, and those searching the subtrees rooted at nodes C and D spend most of their time idle. The static partitioning of unstructured trees yields poor performance because of substantial variation in the size of partitions of the search space rooted at different nodes. Furthermore, since the search space is usually generated dynamically, it is difficult to get a good estimate of the size of the search space beforehand. Therefore, it is necessary to balance the search space among processors dynamically. In dynamic load balancing, when a processor runs out of work, it gets more work from another processor that has work. Consider the two-processor partitioning of the tree in Figure 11.7(a). Assume that nodes A and B are assigned to the two processors as we just described. In this case when the processor searching the subtree rooted at node A runs out of work, it requests work from the other processor. Although the dynamic distribution of work results in communication overhead for work requests and work transfers, it reduces load imbalance among processors. This section explores several schemes for dynamically balancing the load between processors. A parallel formulation of DFS based on dynamic load balancing is as follows. Each processor performs DFS on a disjoint part of the search space. When a processor finishes searching its part of the search space, it requests an unsearched part from other processors. This takes the form of work request and response messages in message passing architectures, and locking and extracting work in shared address space machines. Whenever a processor finds a goal node, all the processors terminate. If the search space is finite and the problem has no solutions, then all the processors eventually run out of work, and the algorithm terminates. Since each processor searches the state space depth-first, unexplored states can be conveniently stored as a stack. Each processor maintains its own local stack on which it executes DFS. When a processor's local stack is empty, it requests (either via explicit messages or by locking) untried alternatives from another processor's stack. In the beginning, the entire search space is assigned to one processor, and other processors are assigned null search spaces (that is, empty stacks). The search space is distributed among the processors as they request work. We refer to the processor that sends work as the donor processor and to the processor that requests and receives work as the recipient processor. As illustrated in Figure 11.8, each processor can be in one of two states: active (that is, it has work) or idle (that is, it is trying to get work). In message passing architectures, an idle processor selects a donor processor and sends it a work request. If the idle processor receives work (part of the state space to be searched) from the donor processor, it becomes active. If it receives a reject message (because the donor has no work), it selects another donor and sends a work request to that donor. This process repeats until the processor gets work or all the processors become idle. When a processor is idle and it receives a work request, that processor returns a reject message. The same process can be implemented on shared address space machines by locking another processors' stack, examining it to see if it has work, extracting work, and unlocking the stack. Figure 11.8. A generic scheme for dynamic load balancing.
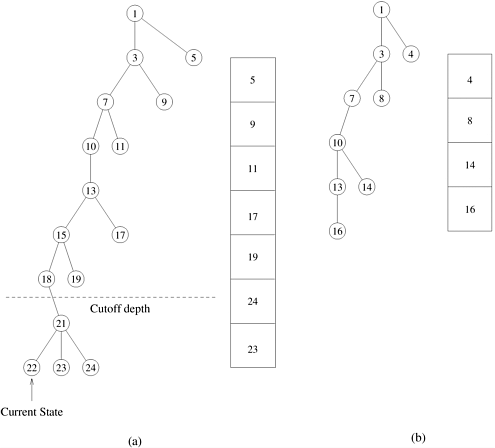
On message passing architectures, in the active state, a processor does a fixed amount of work (expands a fixed number of nodes) and then checks for pending work requests. When a work request is received, the processor partitions its work into two parts and sends one part to the requesting processor. When a processor has exhausted its own search space, it becomes idle. This process continues until a solution is found or until the entire space has been searched. If a solution is found, a message is broadcast to all processors to stop searching. A termination detection algorithm is used to detect whether all processors have become idle without finding a solution (Section 11.4.4). 11.4.1 Important Parameters of Parallel DFSTwo characteristics of parallel DFS are critical to determining its performance. First is the method for splitting work at a processor, and the second is the scheme to determine the donor processor when a processor becomes idle. Work-Splitting StrategiesWhen work is transferred, the donor's stack is split into two stacks, one of which is sent to the recipient. In other words, some of the nodes (that is, alternatives) are removed from the donor's stack and added to the recipient's stack. If too little work is sent, the recipient quickly becomes idle; if too much, the donor becomes idle. Ideally, the stack is split into two equal pieces such that the size of the search space represented by each stack is the same. Such a split is called a half-split. It is difficult to get a good estimate of the size of the tree rooted at an unexpanded alternative in the stack. However, the alternatives near the bottom of the stack (that is, close to the initial node) tend to have bigger trees rooted at them, and alternatives near the top of the stack tend to have small trees rooted at them. To avoid sending very small amounts of work, nodes beyond a specified stack depth are not given away. This depth is called the cutoff depth. Some possible strategies for splitting the search space are (1) send nodes near the bottom of the stack, (2) send nodes near the cutoff depth, and (3) send half the nodes between the bottom of the stack and the cutoff depth. The suitability of a splitting strategy depends on the nature of the search space. If the search space is uniform, both strategies 1 and 3 work well. If the search space is highly irregular, strategy 3 usually works well. If a strong heuristic is available (to order successors so that goal nodes move to the left of the state-space tree), strategy 2 is likely to perform better, since it tries to distribute those parts of the search space likely to contain a solution. The cost of splitting also becomes important if the stacks are deep. For such stacks, strategy 1 has lower cost than strategies 2 and 3. Figure 11.9 shows the partitioning of the DFS tree of Figure 11.5(a) into two subtrees using strategy 3. Note that the states beyond the cutoff depth are not partitioned. Figure 11.9 also shows the representation of the stack corresponding to the two subtrees. The stack representation used in the figure stores only the unexplored alternatives. Figure 11.9. Splitting the DFS tree in Figure 11.5. The two subtrees along with their stack representations are shown in (a) and (b).
Load-Balancing SchemesThis section discusses three dynamic load-balancing schemes: asynchronous round robin, global round robin, and random polling. Each of these schemes can be coded for message passing as well as shared address space machines. Asynchronous Round Robin In asynchronous round robin (ARR), each processor maintains an independent variable, target. Whenever a processor runs out of work, it uses target as the label of a donor processor and attempts to get work from it. The value of target is incremented (modulo p) each time a work request is sent. The initial value of target at each processor is set to ((label + 1) modulo p) where label is the local processor label. Note that work requests are generated independently by each processor. However, it is possible for two or more processors to request work from the same donor at nearly the same time. Global Round Robin Global round robin (GRR) uses a single global variable called target. This variable can be stored in a globally accessible space in shared address space machines or at a designated processor in message passing machines. Whenever a processor needs work, it requests and receives the value of target, either by locking, reading, and unlocking on shared address space machines or by sending a message requesting the designated processor (say P0). The value of target is incremented (modulo p) before responding to the next request. The recipient processor then attempts to get work from a donor processor whose label is the value of target. GRR ensures that successive work requests are distributed evenly over all processors. A drawback of this scheme is the contention for access to target. Random Polling Random polling (RP) is the simplest load-balancing scheme. When a processor becomes idle, it randomly selects a donor. Each processor is selected as a donor with equal probability, ensuring that work requests are evenly distributed. 11.4.2 A General Framework for Analysis of Parallel DFSTo analyze the performance and scalability of parallel DFS algorithms for any load-balancing scheme, we must compute the overhead To of the algorithm. Overhead in any load-balancing scheme is due to communication (requesting and sending work), idle time (waiting for work), termination detection, and contention for shared resources. If the search overhead factor is greater than one (i.e., if parallel search does more work than serial search), this will add another term to To. In this section we assume that the search overhead factor is one, i.e., the serial and parallel versions of the algorithm perform the same amount of computation. We analyze the case in which the search overhead factor is other than one in Section 11.6.1. For the load-balancing schemes discussed in Section 11.4.1, idle time is subsumed by communication overhead due to work requests and transfers. When a processor becomes idle, it immediately selects a donor processor and sends it a work request. The total time for which the processor remains idle is equal to the time for the request to reach the donor and for the reply to arrive. At that point, the idle processor either becomes busy or generates another work request. Therefore, the time spent in communication subsumes the time for which a processor is idle. Since communication overhead is the dominant overhead in parallel DFS, we now consider a method to compute the communication overhead for each load-balancing scheme. It is difficult to derive a precise expression for the communication overhead of the load-balancing schemes for DFS because they are dynamic. This section describes a technique that provides an upper bound on this overhead. We make the following assumptions in the analysis.
The first assumption is satisfied by most depth-first search algorithms. The third work-splitting strategy described in Section 11.4.1 results in a-splitting even for highly irregular search spaces. In the load-balancing schemes to be analyzed, the total work is dynamically partitioned among the processors. Processors work on disjoint parts of the search space independently. An idle processor polls for work. When it finds a donor processor with work, the work is split and a part of it is transferred to the idle processor. If the donor has work wi, and it is split into two pieces of size wj and wk, then assumption 2 states that there is a constant a such that wj > awi and wk > awi. Note that a is less than 0.5. Therefore, after a work transfer, neither processor (donor and recipient) has more than (1 - a)wi work. Suppose there are p pieces of work whose sizes are w0,w1, ..., wp-1. Assume that the size of the largest piece is w. If all of these pieces are split, the splitting strategy yields 2p pieces of work whose sizes are given by y0w0,y1w1, ..., yp-1wp-1, (1 - y0)w0, (1 - y1)w1, ..., (1 - yp-1)wp-1. Among them, the size of the largest piece is given by (1 - a)w. Assume that there are p processors and a single piece of work is assigned to each processor. If every processor receives a work request at least once, then each of these p pieces has been split at least once. Thus, the maximum work at any of the processors has been reduced by a factor of (1 - a).We define V (p) such that, after every V (p) work requests, each processor receives at least one work request. Note that V (p) Communication overhead is caused by work requests and work transfers. The total number of work transfers cannot exceed the total number of work requests. Therefore, the total number of work requests, weighted by the total communication cost of one work request and a corresponding work transfer, gives an upper bound on the total communication overhead. For simplicity, we assume the amount of data associated with a work request and work transfer is a constant. In general, the size of the stack should grow logarithmically with respect to the size of the search space. The analysis for this case can be done similarly (Problem 11.3). If tcomm is the time required to communicate a piece of work, then the communication overhead To is given by
The corresponding efficiency E is given by
In Section 5.4.2 we showed that the isoefficiency function can be derived by balancing the problem size W and the overhead function To. As shown by Equation 11.2, To depends on two values: tcomm and V (p). The value of tcomm is determined by the underlying architecture, and the function V (p) is determined by the load-balancing scheme. In the following subsections, we derive V (p) for each scheme introduced in Section 11.4.1. We subsequently use these values of V (p) to derive the scalability of various schemes on message-passing and shared-address-space machines. Computation of V(p) for Various Load-Balancing SchemesEquation 11.2 shows that V (p) is an important component of the total communication overhead. In this section, we compute the value of V (p) for different load-balancing schemes. Asynchronous Round Robin The worst case value of V (p) for ARR occurs when all processors issue work requests at the same time to the same processor. This case is illustrated in the following scenario. Assume that processor p - 1 had all the work and that the local counters of all the other processors (0 to p - 2) were pointing to processor zero. In this case, for processor p - 1 to receive a work request, one processor must issue p - 1 requests while each of the remaining p - 2 processors generates up to p - 2 work requests (to all processors except processor p - 1 and itself). Thus, V (p) has an upper bound of (p - 1) + (p - 2)(p - 2); that is, V (p) = O (p2). Note that the actual value of V (p) is between p and p2. Global Round Robin In GRR, all processors receive requests in sequence. After p requests, each processor has received one request. Therefore, V (p) is p. Random Polling For RR, the worst-case value of V (p) is unbounded. Hence, we compute the average-case value of V (p). Consider a collection of p boxes. In each trial, a box is chosen at random and marked. We are interested in the mean number of trials required to mark all the boxes. In our algorithm, each trial corresponds to a processor sending another randomly selected processor a request for work. Let F (i, p) represent a state in which i of the p boxes have been marked, and p - i boxes have not been marked. Since the next box to be marked is picked at random, there is i/p probability that it will be a marked box and (p - i)/p probability that it will be an unmarked box. Hence the system remains in state F (i, p) with a probability of i/p and transits to state F (i + 1, p) with a probability of (p - i)/p. Let f (i, p) denote the average number of trials needed to change from state F (i, p) to F (p, p). Then, V (p) = f (0, p). We have
Hence,
where Hp is a harmonic number. It can be shown that, as p becomes large, Hp 11.4.3 Analysis of Load-Balancing SchemesThis section analyzes the performance of the load-balancing schemes introduced in Section 11.4.1. In each case, we assume that work is transferred in fixed-size messages (the effect of relaxing this assumption is explored in Problem 11.3). Recall that the cost of communicating an m-word message in the simplified cost model is tcomm = ts + twm. Since the message size m is assumed to be a constant, tcomm = O (1) if there is no congestion on the interconnection network. The communication overhead To (Equation 11.2) reduces to
We balance this overhead with problem size W for each load-balancing scheme to derive the isoefficiency function due to communication. Asynchronous Round Robin As discussed in Section 11.4.2, V (p) for ARR is O (p2). Substituting into Equation 11.3, communication overhead To is given by O (p2 log W). Balancing communication overhead against problem size W, we have
Substituting W into the right-hand side of the same equation and simplifying,
The double-log term (log log W) is asymptotically smaller than the first term, provided p grows no slower than log W, and can be ignored. The isoefficiency function for this scheme is therefore given by O ( p2 log p). Global Round Robin From Section 11.4.2, V (p) = O (p) for GRR. Substituting into Equation 11.3, this yields a communication overhead To of O (p log W). Simplifying as for ARR, the isoefficiency function for this scheme due to communication overhead is O (p log p). In this scheme, however, the global variable target is accessed repeatedly, possibly causing contention. The number of times this variable is accessed is equal to the total number of work requests, O (p log W). If the processors are used efficiently, the total execution time is O (W/p). Assume that there is no contention for target while solving a problem of size W on p processors. Then, W/p is larger than the total time during which the shared variable is accessed. As the number of processors increases, the execution time (W/p) decreases, but the number of times the shared variable is accessed increases. Thus, there is a crossover point beyond which the shared variable becomes a bottleneck, prohibiting further reduction in run time. This bottleneck can be eliminated by increasing W at a rate such that the ratio between W/p and O (p log W) remains constant. This requires W to grow with respect to p as follows:
We can simplify Equation 11.4 to express W in terms of p. This yields an isoefficiency term of O (p2 log p). Since the isoefficiency function due to contention asymptotically dominates the isoefficiency function due to communication, the overall isoefficiency function is given by O (p2 log p). Note that although it is difficult to estimate the actual overhead due to contention for the shared variable, we are able to determine the resulting isoefficiency function. Random Polling We saw in Section 11.4.2 that V (p) = O (p log p) for RP. Substituting this value into Equation 11.3, the communication overhead To is O (p log p log W). Equating To with the problem size W and simplifying as before, we derive the isoefficiency function due to communication overhead as O (p log2 p). Since there is no contention in RP, this function also gives its overall isoefficiency function. 11.4.4 Termination DetectionOne aspect of parallel DFS that has not been addressed thus far is termination detection. In this section, we present two schemes for termination detection that can be used with the load-balancing algorithms discussed in Section 11.4.1. Dijkstra's Token Termination Detection AlgorithmConsider a simplified scenario in which once a processor goes idle, it never receives more work. Visualize the p processors as being connected in a logical ring (note that a logical ring can be easily mapped to underlying physical topologies). Processor P0 initiates a token when it becomes idle. This token is sent to the next processor in the ring, P1. At any stage in the computation, if a processor receives a token, the token is held at the processor until the computation assigned to the processor is complete. On completion, the token is passed to the next processor in the ring. If the processor was already idle, the token is passed to the next processor. Note that if at any time the token is passed to processor Pi , then all processors P0, ..., Pi -1 have completed their computation. Processor Pp-1 passes its token to processor P0; when it receives the token, processor P0 knows that all processors have completed their computation and the algorithm can terminate. Such a simple scheme cannot be applied to the search algorithms described in this chapter, because after a processor goes idle, it may receive more work from other processors. The token termination detection scheme thus must be modified. In the modified scheme, the processors are also organized into a ring. A processor can be in one of two states: black or white. Initially, all processors are in state white. As before, the token travels in the sequence P0, P1, ..., Pp-1, P0. If the only work transfers allowed in the system are from processor Pi to Pj such that i < j, then the simple termination scheme is still adequate. However, if processor Pj sends work to processor Pi, the token must traverse the ring again. In this case processor Pj is marked black since it causes the token to go around the ring again. Processor P0 must be able to tell by looking at the token it receives whether it should be propagated around the ring again. Therefore the token itself is of two types: a white (or valid) token, which when received by processor P0 implies termination; and a black (or invalid) token, which implies that the token must traverse the ring again. The modified termination algorithm works as follows:
The algorithm terminates when processor P0 receives a white token and is itself idle. The algorithm correctly detects termination by accounting for the possibility of a processor receiving work after it has already been accounted for by the token. The run time of this algorithm is O (P) with a small constant. For a small number of processors, this scheme can be used without a significant impact on the overall performance. For a large number of processors, this algorithm can cause the overall isoefficiency function of the load-balancing scheme to be at least O (p2) (Problem 11.4). Tree-Based Termination DetectionTree-based termination detection associates weights with individual work pieces. Initially processor P0 has all the work and a weight of one is associated with it. When its work is partitioned and sent to another processor, processor P0 retains half of the weight and gives half of it to the processor receiving the work. If Pi is the recipient processor and wi is the weight at processor Pi, then after the first work transfer, both w0 and wi are 0.5. Each time the work at a processor is partitioned, the weight is halved. When a processor completes its computation, it returns its weight to the processor from which it received work. Termination is signaled when the weight w0 at processor P0 becomes one and processor P0 has finished its work. Example 11.7 Tree-based termination detection Figure 11.10 illustrates tree-based termination detection for four processors. Initially, processor P0 has all the weight (w0 = 1), and the weight at the remaining processors is 0 (w1 = w2 = w3 = 0). In step 1, processor P0 partitions its work and gives part of it to processor P1. After this step, w0 and w1 are 0.5 and w2 and w3 are 0. In step 2, processor P1 gives half of its work to processor P2. The weights w1 and w2 after this work transfer are 0.25 and the weights w0 and w3 remain unchanged. In step 3, processor P3 gets work from processor P1 and the weights of all processors become 0.25. In step 4, processor P2 completes its work and sends its weight to processor P1. The weight w1 of processor P1 becomes 0.5. As processors complete their work, weights are propagated up the tree until the weight w0 at processor P0 becomes 1. At this point, all work has been completed and termination can be signaled. Figure 11.10. Tree-based termination detection. Steps 1-6 illustrate the weights at various processors after each work transfer.
This termination detection algorithm has a significant drawback. Due to the finite precision of computers, recursive halving of the weight may make the weight so small that it becomes 0. In this case, weight will be lost and termination will never be signaled. This condition can be alleviated by using the inverse of the weights. If processor Pi has weight wi, instead of manipulating the weight itself, it manipulates 1/wi. The details of this algorithm are considered in Problem 11.5. The tree-based termination detection algorithm does not change the overall isoefficiency function of any of the search schemes we have considered. This follows from the fact that there are exactly two weight transfers associated with each work transfer. Therefore, the algorithm has the effect of increasing the communication overhead by a constant factor. In asymptotic terms, this change does not alter the isoefficiency function. 11.4.5 Experimental ResultsIn this section, we demonstrate the validity of scalability analysis for various parallel DFS algorithms. The satisfiability problem tests the validity of boolean formulae. Such problems arise in areas such as VLSI design and theorem proving. The satisfiability problem can be stated as follows: given a boolean formula containing binary variables in conjunctive normal form, determine if it is unsatisfiable. A boolean formula is unsatisfiable if there exists no assignment of truth values to variables for which the formula is true. The Davis-Putnam algorithm is a fast and efficient way to solve this problem. The algorithm works by performing a depth-first search of the binary tree formed by true or false assignments to the literals in the boolean expression. Let n be the number of literals. Then the maximum depth of the tree cannot exceed n. If, after a partial assignment of values to literals, the formula becomes false, then the algorithm backtracks. The formula is unsatisfiable if depth-first search fails to find an assignment to variables for which the formula is true. Even if a formula is unsatisfiable, only a small subset of the 2n possible combinations will actually be explored. For example, for a 65-variable problem, the total number of possible combinations is 265 (approximately 3.7 x 1019), but only about 107 nodes are actually expanded in a specific problem instance. The search tree for this problem is pruned in a highly nonuniform fashion and any attempt to partition the tree statically results in an extremely poor load balance.
The satisfiability problem is used to test the load-balancing schemes on a message passing parallel computer for up to 1024 processors. We implemented the Davis-Putnam algorithm, and incorporated the load-balancing algorithms discussed in Section 11.4.1. This program was run on several unsatisfiable formulae. By choosing unsatisfiable instances, we ensured that the number of nodes expanded by the parallel formulation is the same as the number expanded by the sequential one; any speedup loss was due only to the overhead of load balancing. In the problem instances on which the program was tested, the total number of nodes in the tree varied between approximately 105 and 107. The depth of the trees (which is equal to the number of variables in the formula) varied between 35 and 65. Speedup was calculated with respect to the optimum sequential execution time for the same problem. Average speedup was calculated by taking the ratio of the cumulative time to solve all the problems in parallel using a given number of processors to the corresponding cumulative sequential time. On a given number of processors, the speedup and efficiency were largely determined by the tree size (which is roughly proportional to the sequential run time). Thus, speedup on similar-sized problems was quite similar.
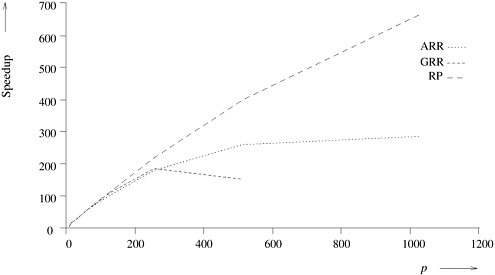
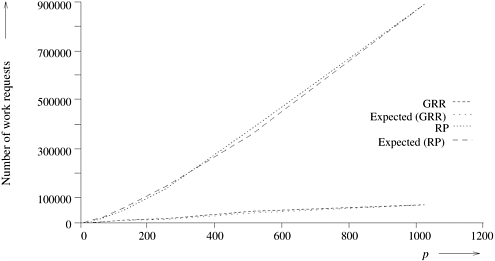
All schemes were tested on a sample set of five problem instances. Table 11.1 shows the average speedup obtained by parallel algorithms using different load-balancing techniques. Figure 11.11 is a graph of the speedups obtained. Table 11.2 presents the total number of work requests made by RP and GRR for one problem instance. Figure 11.12 shows the corresponding graph and compares the number of messages generated with the expected values O (p log2 p) and O (p log p) for RP and GRR, respectively. Figure 11.11. Speedups of parallel DFS using ARR, GRR and RP load-balancing schemes.
Figure 11.12. Number of work requests generated for RP and GRR and their expected values (O(p log2 p) and O(p log p) respectively).
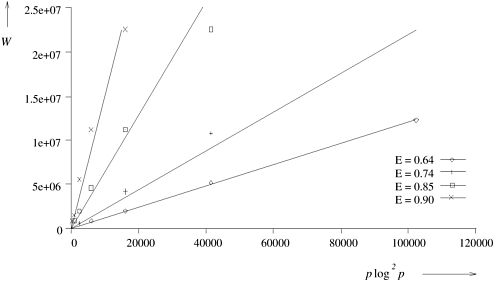
The isoefficiency function of GRR is O (p2 log p) which is much worse than the isoefficiency function of RP. This is reflected in the performance of our implementation. From Figure 11.11, we see that the performance of GRR deteriorates very rapidly for more than 256 processors. Good speedups can be obtained for p > 256 only for very large problem instances. Experimental results also show that ARR is more scalable than GRR, but significantly less scalable than RP. Although the isoefficiency functions of ARR and GRR are both O (p2 log p), ARR performs better than GRR. The reason for this is that p2 log p is an upper bound, derived using V (p) = O (p2). This value of V (p) is only a loose upper bound for ARR. In contrast, the value of V (p) used for GRR (O (p)) is a tight bound. To determine the accuracy of the isoefficiency functions of various schemes, we experimentally verified the isoefficiency curves for the RP technique (the selection of this technique was arbitrary). We ran 30 different problem instances varying in size from 105 nodes to 107 nodes on a varying number of processors. Speedup and efficiency were computed for each of these. Data points with the same efficiency for different problem sizes and number of processors were then grouped. Where identical efficiency points were not available, the problem size was computed by averaging over points with efficiencies in the neighborhood of the required value. These data are presented in Figure 11.13, which plots the problem size W against p log2 p for values of efficiency equal to 0.9, 0.85, 0.74, and 0.64. We expect points corresponding to the same efficiency to be collinear. We can see from Figure 11.13 that the points are reasonably collinear, which shows that the experimental isoefficiency function of RP is close to the theoretically derived isoefficiency function. Figure 11.13. Experimental isoefficiency curves for RP for different efficiencies.
11.4.6 Parallel Formulations of Depth-First Branch-and-Bound SearchParallel formulations of depth-first branch-and-bound search (DFBB) are similar to those of DFS. The preceding formulations of DFS can be applied to DFBB with one minor modification: all processors are kept informed of the current best solution path. The current best solution path for many problems can be represented by a small data structure. For shared address space computers, this data structure can be stored in a globally accessible memory. Each time a processor finds a solution, its cost is compared to that of the current best solution path. If the cost is lower, then the current best solution path is replaced. On a message-passing computer, each processor maintains the current best solution path known to it. Whenever a processor finds a solution path better than the current best known, it broadcasts its cost to all other processors, which update (if necessary) their current best solution cost. Since the cost of a solution is captured by a single number and solutions are found infrequently, the overhead of communicating this value is fairly small. Note that, if a processor's current best solution path is worse than the globally best solution path, the efficiency of the search is affected but not its correctness. Because of DFBB's low communication overhead, the performance and scalability of parallel DFBB is similar to that of parallel DFS discussed earlier. 11.4.7 Parallel Formulations of IDA*Since IDA* explores the search tree iteratively with successively increasing cost bounds, it is natural to conceive a parallel formulation in which separate processors explore separate parts of the search space independently. Processors may be exploring the tree using different cost bounds. This approach suffers from two drawbacks.
A more effective approach executes each iteration of IDA* by using parallel DFS (Section 11.4). All processors use the same cost bound; each processor stores the bound locally and performs DFS on its own search space. After each iteration of parallel IDA*, a designated processor determines the cost bound for the next iteration and restarts parallel DFS with the new bound. The search terminates when a processor finds a goal node and informs all the other processors. The performance and scalability of this parallel formulation of IDA* are similar to those of the parallel DFS algorithm. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
 .
.
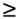
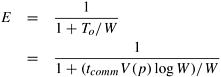
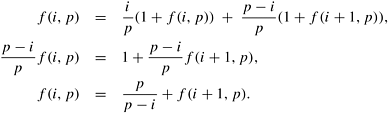
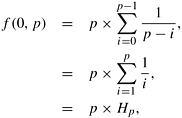
 1.69 ln
1.69 ln