Triggers are essentially the event handlers of the database. When creating a trigger, you need to specify some important pieces of information.
Triggers are associated with data tables and are executed by reacting automatically to events. When creating a trigger, it's a basic requirement that you associate it with a table and specify the event or events on which it should fire. Do you want the trigger to execute when new rows are added to the table or when rows are deleted or updated? You're allowed to specify any of these actions (INSERT, DELETE, UPDATE) or any combination of them.
| Tip |
There are scenarios when triggers aren't called, even though it may seem like they should be. For example, a DELETE trigger isn't called if the table records are deleted using a TRUNCATE TABLE command. TRUNCATE TABLE is an unlogged operation; it doesn't fire any triggers and can't be rolled back by transactions. |
Another decision you need to make is when exactly the trigger should fire. Because triggers are executed by events, they can be instructed to execute before or after those events occur. You can also create a trigger that executes instead of the event that fired it.
The final important part of a trigger is the code itself—the SQL procedure that executes when the trigger is fired.
Note that although a trigger is similar to a stored procedure in that it's made up of SQL statements, it can't take any input values or return any values—this makes sense because the trigger is called automatically by the database.
Inside the trigger code, each database has its own ways of telling you why the trigger was raised and which rows are about to be modified, updated, or deleted. In this chapter, you'll examine these details separately for each database.
You can create more than one trigger on a single data table. The actions that happen in a trigger can fire other triggers (in which case they're said to be nested triggers), and a trigger can even call itself recursively.
Based on the number of times a trigger executes when an event that affects multiple rows happens, triggers are categorized in statement-level triggers and row-level triggers:
Statement-level triggers: A statement-level trigger executes only once, even if the INSERT, UPDATE, or DELETE statement that fired the trigger affects multiple rows.
Row-level triggers: These triggers fire for each row affected by an INSERT, UPDATE, or DELETE statement. If an UPDATE affects 100 rows, the trigger will be executed 100 times, once for each row.
You can set both statement-level triggers and row-level triggers to execute before, after, or instead of the command that triggered them. Based on the time when the trigger executes relative to the event that fired it, there are three kinds of triggers:
BEFORE and AFTER triggers: Because triggers are executed by events, they can be set to fire before or after those events happen. It's important to keep in mind that BEFORE triggers fire before any existing constraints are checked; AFTER triggers only fire after the new rows have actually been modified (which implies that the command has passed the referential integrity constraints defined for the table). For this reason, AFTER triggers are often used in auditing applications (you'll see simple examples in action later in this chapter).
INSTEAD OF triggers: These are used when you want to replace the action intended by the user with some other actions—so the code defined in the trigger is executed in place of the statement that was actually issued. This is particularly useful for triggers that are associated with views. When a complex view is updated, you're likely to want its underlying data tables to be updated.
Some databases also support triggers that act on other events, such as table creation or modification, a user login or log out, database startup or shutdown, and so on. Please consult the documentation for your database to find out what it has in store for you in this area.
This chapter discusses each type of trigger, but focuses on the code examples on AFTER triggers because these are probably the most commonly used in day-to-day SQL programming.
The SQL-99 command for creating triggers is CREATE TRIGGER. You drop triggers via the DROP TRIGGER command. The SQL-99 syntax for creating triggers looks pretty ugly, and it isn't implemented as such by any database software. However, here it is for reference:
CREATE TRIGGER trigger_name
{ BEFORE | AFTER }
{[DELETE] | [INSERT} | [UPDATE]
[OF column [,...n]} ON table_name
[REFERENCING {OLD [ROW] [AS] old_name | NEW [ROW] [AS] new_name
OLD TABLE [AS] old_name | NEW TABLE [AS] new_name}]
[FOR EACH { ROW | STATEMENT }]
[WHEN (conditions)]
<<SQL code block>>
It looks rather complex, but as you work through some examples, things will become clearer.
The syntax for dropping a trigger is the same for all platforms:
Triggers are complex beasts, with applications in programming, administration, security, and so on. Typical uses for triggers include the following:
Supplementing Declarative Referential Integrity (DRI): You know DRI is done using foreign keys. However, there are times when the foreign key isn't powerful enough because there are complex kinds of table relationships it can't deal with (such as the ones that spread across more databases or database servers).
Enforcing complex business rules: When data is being modified in a table, you can use a trigger to make sure that no complex business rules or data integrity rules are broken.
Creating audit trails: In these examples, you'll see how to log all the operations that take place on a data table.
Simulating functionality: They can simulate the functionality of CHECK constraints but across tables, databases, or database servers.
Substituting statements: You can substitute your own statements instead of the action that was intended by the user. This is particularly useful when the user tries to insert data in a view, and you intercept this and update the underlying tables instead.
Yes, triggers are a powerful and versatile feature you can use to control many aspects of your database operation. However, this control comes at the expense of database processing power. Triggers definitely have their place but should not be used where simple constraints, such as foreign keys for referential integrity, will suffice.
In this chapter, you'll implement a simple auditing example using AFTER triggers. This example will use statement-level triggers for SQL Server and row-level triggers for Oracle and DB2.
In the examples, you'll use a simple version of the Friend table. You'll see how to log changes that happen to it using a second table, FriendAudit. For now, remove your existing Friend table and re-create it like this:
| Caution |
Remember that if you need to drop Friend and it's being referenced from the Phone table you created earlier through a FOREIGN KEY constraint, you need to drop the Phone table first or remove the FOREIGN KEY constraint in Phone. |
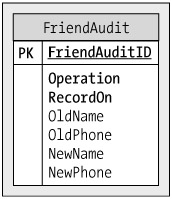
You'll create a FriendAudit table separately for each database with which you'll work. Figure 13-1 shows its structure.
The FriendAuditID primary key uniquely identifies each record.
The Operation field will contain "Update", "Insert", or "Delete", depending on the operation you're logging. The other fields will contain details about the specific operation.
For INSERT operations, you'll populate the NewName and NewPhone fields, and OldName and OldPhone will contain NULLs. For DELETE operations, you'll populate the OldName and OldPhone, and NewName and NewPhone will contain NULLs. On UPDATE operations, all fields will be populated, specifying both the old friend values and the new updated ones.