Domain modeling forms the foundation of the static part of our UML model. When we build a domain model, we start off by trying to identify abstractions in the real world-that is, the main conceptual objects that are going to participate in this system. When you design object-oriented software, you try to structure your software around these real-world, problem space objects. The theory behind this is that the real world changes less frequently than the software requirements. The basis for our whole object modeling activity, particularly the static modeling part of the activity, is a model of these problem domain abstractions.
You may be wondering why this chapter precedes a discussion of use cases in a book called Applying Use Case Driven Object Modeling. The reason is that when we write our use cases (see Chapter 3), we're not going to write them from an abstract, pure user viewpoint; instead, we're going to be writing use cases in the context of the object model. By doing this, we'll be able to link together the static and dynamic portions of the model, which is essential if we're going to drive the design forward from the use cases. The domain model serves as a glossary of terms that writers of use cases can use in the early stages of that effort.
As we identify real-world, problem domain objects, we also need to identify the relationships among those objects. These include two particularly important relationship types: generalization, which is the superclass/subclass relationship, and aggregation, which is the whole part/subpart kind of relationship. There are other types of relationships between classes in addition to generalization and aggregation, including plain vanilla associations between objects, but generalization and aggregation are particularly important. As the foundation of our static model, we're using UML class diagrams to express our domain model.
UML classes give us a place to capture attributes, which are data elements or data members, as well as operations, which are the functions that a given object performs. However, in the initial domain modeling activity, we don't usually want to spend too much time capturing attributes and operations-we'll do this later on as we refine and flesh out the static part of our model. We want to focus on identifying objects and the relationships between them as we're doing the domain modeling.
Reuse is one of the main goals of building your software around these real-world abstractions, because we often have multiple software systems that share a common problem domain. Keep in mind that if you're aiming for reuse, you want to do a very good job at domain modeling because the reusable aspects of your software are largely going to come out of this domain modeling activity. This domain model then becomes the foundation for the static part of your model.
The domain modeling process, for which we're following the Object Modeling Technique (OMT) school of thought, is fundamentally an inside-out approach. Inside-out means that we're starting with the core objects in the system, then working from the inside outward, to see how those objects are going to participate in the system we're building. So, the use case approach, or the dynamic part of the model, is an outside-in approach, whereas the static part of the model is an inside-out approach. The trick when you're working both outside-in and inside-out is to make these two parts meet in the middle and not have a disconnect in between. As we get into robustness analysis (see Chapter 5) and sequence diagrams (see Chapter 7), we'll see exactly how this works. For now, just keep in mind that this domain model and static modeling activity is really an inside-out look at our system.
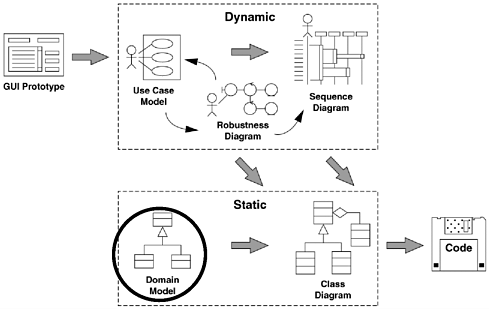
Figure 2-1 shows where domain modeling resides within the "big picture" for the ICONIX process.