|
|
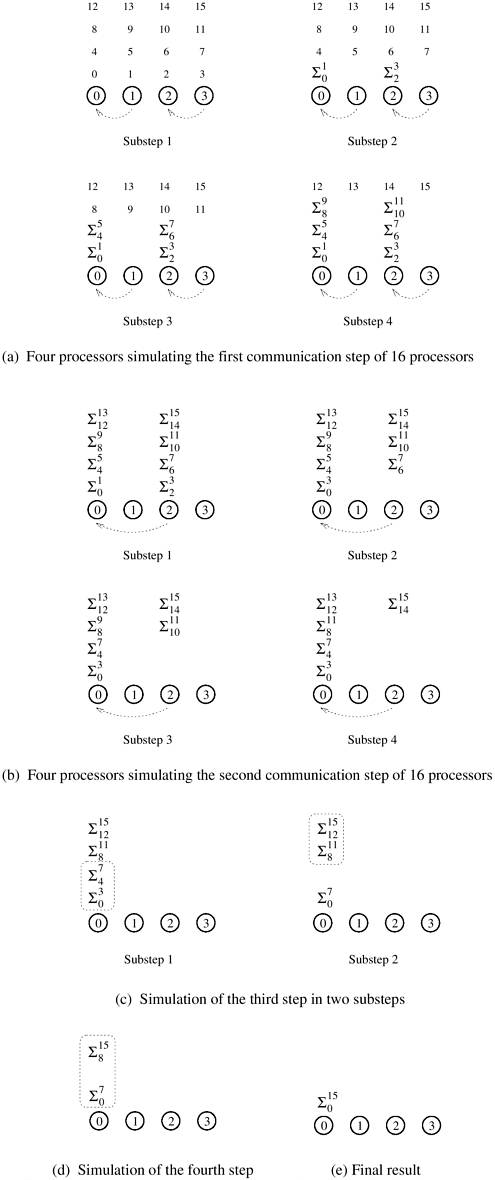
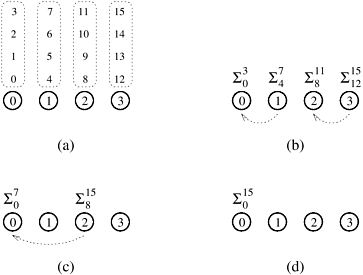
5.3 The Effect of Granularity on PerformanceExample 5.7 illustrated an instance of an algorithm that is not cost-optimal. The algorithm discussed in this example uses as many processing elements as the number of inputs, which is excessive in terms of the number of processing elements. In practice, we assign larger pieces of input data to processing elements. This corresponds to increasing the granularity of computation on the processing elements. Using fewer than the maximum possible number of processing elements to execute a parallel algorithm is called scaling down a parallel system in terms of the number of processing elements. A naive way to scale down a parallel system is to design a parallel algorithm for one input element per processing element, and then use fewer processing elements to simulate a large number of processing elements. If there are n inputs and only p processing elements (p < n), we can use the parallel algorithm designed for n processing elements by assuming n virtual processing elements and having each of the p physical processing elements simulate n/p virtual processing elements. As the number of processing elements decreases by a factor of n/p, the computation at each processing element increases by a factor of n/p because each processing element now performs the work of n/p processing elements. If virtual processing elements are mapped appropriately onto physical processing elements, the overall communication time does not grow by more than a factor of n/p. The total parallel runtime increases, at most, by a factor of n/p, and the processor-time product does not increase. Therefore, if a parallel system with n processing elements is cost-optimal, using p processing elements (where p < n)to simulate n processing elements preserves cost-optimality. A drawback of this naive method of increasing computational granularity is that if a parallel system is not cost-optimal to begin with, it may still not be cost-optimal after the granularity of computation increases. This is illustrated by the following example for the problem of adding n numbers. Example 5.9 Adding n numbers on p processing elements Consider the problem of adding n numbers on p processing elements such that p < n and both n and p are powers of 2. We use the same algorithm as in Example 5.1 and simulate n processing elements on p processing elements. The steps leading to the solution are shown in Figure 5.5 for n = 16 and p = 4. Virtual processing element i is simulated by the physical processing element labeled i mod p; the numbers to be added are distributed similarly. The first log p of the log n steps of the original algorithm are simulated in (n/p) log p steps on p processing elements. In the remaining steps, no communication is required because the processing elements that communicate in the original algorithm are simulated by the same processing element; hence, the remaining numbers are added locally. The algorithm takes Q((n/p) log p) time in the steps that require communication, after which a single processing element is left with n/p numbers to add, taking time Q(n/p). Thus, the overall parallel execution time of this parallel system is Q((n/p) log p). Consequently, its cost is Q(n log p), which is asymptotically higher than the Q(n) cost of adding n numbers sequentially. Therefore, the parallel system is not cost-optimal. Figure 5.5. Four processing elements simulating 16 processing elements to compute the sum of 16 numbers (first two steps).
|
|
|