|
|
6.7 Groups and CommunicatorsIn many parallel algorithms, communication operations need to be restricted to certain subsets of processes. MPI provides several mechanisms for partitioning the group of processes that belong to a communicator into subgroups each corresponding to a different communicator. A general method for partitioning a graph of processes is to use MPI_Comm_split that is defined as follows:
int MPI_Comm_split(MPI_Comm comm, int color, int key,
MPI_Comm *newcomm)
This function is a collective operation, and thus needs to be called by all the processes in the communicator comm. The function takes color and key as input parameters in addition to the communicator, and partitions the group of processes in the communicator comm into disjoint subgroups. Each subgroup contains all processes that have supplied the same value for the color parameter. Within each subgroup, the processes are ranked in the order defined by the value of the key parameter, with ties broken according to their rank in the old communicator (i.e., comm). A new communicator for each subgroup is returned in the newcomm parameter. Figure 6.7 shows an example of splitting a communicator using the MPI_Comm_split function. If each process called MPI_Comm_split using the values of parameters color and key as shown in Figure 6.7, then three communicators will be created, containing processes {0, 1, 2}, {3, 4, 5, 6}, and {7}, respectively. Figure 6.7. Using MPI_Comm_split to split a group of processes in a communicator into subgroups.
Splitting Cartesian Topologies In many parallel algorithms, processes are arranged in a virtual grid, and in different steps of the algorithm, communication needs to be restricted to a different subset of the grid. MPI provides a convenient way to partition a Cartesian topology to form lower-dimensional grids. MPI provides the MPI_Cart_sub function that allows us to partition a Cartesian topology into sub-topologies that form lower-dimensional grids. For example, we can partition a two-dimensional topology into groups, each consisting of the processes along the row or column of the topology. The calling sequence of MPI_Cart_sub is the following:
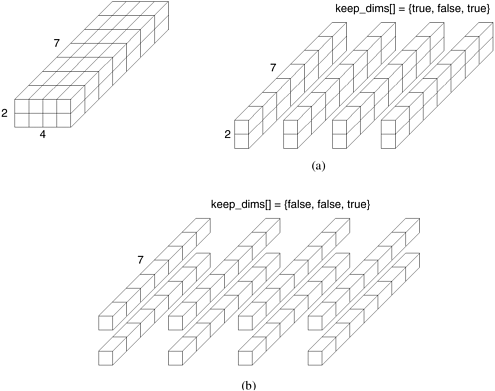
int MPI_Cart_sub(MPI_Comm comm_cart, int *keep_dims,
MPI_Comm *comm_subcart)
The array keep_dims is used to specify how the Cartesian topology is partitioned. In particular, if keep_dims[i] is true (non-zero value in C) then the ith dimension is retained in the new sub-topology. For example, consider a three-dimensional topology of size 2 x 4 x 7. If keep_dims is {true, false, true}, then the original topology is split into four two-dimensional sub-topologies of size 2 x 7, as illustrated in Figure 6.8(a). If keep_dims is {false, false, true}, then the original topology is split into eight one-dimensional topologies of size seven, illustrated in Figure 6.8(b). Note that the number of sub-topologies created is equal to the product of the number of processes along the dimensions that are not being retained. The original topology is specified by the communicator comm_cart, and the returned communicator comm_subcart stores information about the created sub-topology. Only a single communicator is returned to each process, and for processes that do not belong to the same sub-topology, the group specified by the returned communicator is different. Figure 6.8. Splitting a Cartesian topology of size 2 x 4 x 7 into (a) four subgroups of size 2 x 1 x 7, and (b) eight subgroups of size 1 x 1 x 7.
The processes belonging to a given sub-topology can be determined as follows. Consider a three-dimensional topology of size d1 x d2 x d3, and assume that keep_dims is set to {true, false, true}. The group of processes that belong to the same sub-topology as the process with coordinates (x , y, z) is given by (*, y, *), where a '*' in a coordinate denotes all the possible values for this coordinate. Note also that since the second coordinate can take d2 values, a total of d2 sub-topologies are created. Also, the coordinate of a process in a sub-topology created by MPI_Cart_sub can be obtained from its coordinate in the original topology by disregarding the coordinates that correspond to the dimensions that were not retained. For example, the coordinate of a process in the column-based sub-topology is equal to its row-coordinate in the two-dimensional topology. For instance, the process with coordinates (2, 3) has a coordinate of (2) in the sub-topology that corresponds to the third column of the grid. 6.7.1 Example: Two-Dimensional Matrix-Vector MultiplicationIn Section 6.6.8, we presented two programs for performing the matrix-vector multiplication x = Ab using a row- and column-wise distribution of the matrix. As discussed in Section 8.1.2, an alternative way of distributing matrix A is to use a two-dimensional distribution, giving rise to the two-dimensional parallel formulations of the matrix-vector multiplication algorithm. Program 6.8 shows how these topologies and their partitioning are used to implement the two-dimensional matrix-vector multiplication. The dimension of the matrix is supplied in the parameter n, the parameters a and b point to the locally stored portions of matrix A and vector b, respectively, and the parameter x points to the local portion of the output matrix-vector product. Note that only the processes along the first column of the process grid will store b initially, and that upon return, the same set of processes will store the result x. For simplicity, the program assumes that the number of processes p is a perfect square and that n is a multiple of Program 6.8 Two-Dimensional Matrix-Vector Multiplication
1 MatrixVectorMultiply_2D(int n, double *a, double *b, double *x,
2 MPI_Comm comm)
3 {
4 int ROW=0, COL=1; /* Improve readability */
5 int i, j, nlocal;
6 double *px; /* Will store partial dot products */
7 int npes, dims[2], periods[2], keep_dims[2];
8 int myrank, my2drank, mycoords[2];
9 int other_rank, coords[2];
10 MPI_Status status;
11 MPI_Comm comm_2d, comm_row, comm_col;
12
13 /* Get information about the communicator */
14 MPI_Comm_size(comm, &npes);
15 MPI_Comm_rank(comm, &myrank);
16
17 /* Compute the size of the square grid */
18 dims[ROW] = dims[COL] = sqrt(npes);
19
20 nlocal = n/dims[ROW];
21
22 /* Allocate memory for the array that will hold the partial dot-products */
23 px = malloc(nlocal*sizeof(double));
24
25 /* Set up the Cartesian topology and get the rank & coordinates of the process in
|
|
|