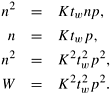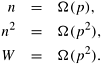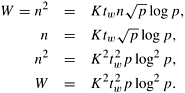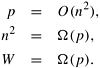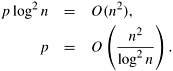|
|
8.1 Matrix-Vector MultiplicationThis section addresses the problem of multiplying a dense n x n matrix A with an n x 1 vector x to yield the n x 1 result vector y. Algorithm 8.1 shows a serial algorithm for this problem. The sequential algorithm requires n2 multiplications and additions. Assuming that a multiplication and addition pair takes unit time, the sequential run time is
At least three distinct parallel formulations of matrix-vector multiplication are possible, depending on whether rowwise 1-D, columnwise 1-D, or a 2-D partitioning is used. Algorithm 8.1 A serial algorithm for multiplying an n x n matrix A with an n x 1 vector x to yield an n x 1 product vector y.1. procedure MAT_VECT ( A, x, y) 2. begin 3. for i := 0 to n - 1 do 4. begin 5. y[i]:=0; 6. for j := 0 to n - 1 do 7. y[i] := y[i] + A[i, j] x x[j]; 8. endfor; 9. end MAT_VECT 8.1.1 Rowwise 1-D PartitioningThis section details the parallel algorithm for matrix-vector multiplication using rowwise block 1-D partitioning. The parallel algorithm for columnwise block 1-D partitioning is similar (Problem 8.2) and has a similar expression for parallel run time. Figure 8.1 describes the distribution and movement of data for matrix-vector multiplication with block 1-D partitioning. Figure 8.1. Multiplication of an n x n matrix with an n x 1 vector using rowwise block 1-D partitioning. For the one-row-per-process case, p = n.
One Row Per ProcessFirst, consider the case in which the n x n matrix is partitioned among n processes so that each process stores one complete row of the matrix. The n x 1 vector x is distributed such that each process owns one of its elements. The initial distribution of the matrix and the vector for rowwise block 1-D partitioning is shown in Figure 8.1(a). Process Pi initially owns x[i] and A[i, 0], A[i, 1], ..., A[i, n-1] and is responsible for computing y[i]. Vector x is multiplied with each row of the matrix (Algorithm 8.1); hence, every process needs the entire vector. Since each process starts with only one element of x, an all-to-all broadcast is required to distribute all the elements to all the processes. Figure 8.1(b) illustrates this communication step. After the vector x is distributed among the processes (Figure 8.1(c)), process Pi computes Parallel Run Time Starting with one vector element per process, the all-to-all broadcast of the vector elements among n processes requires time Q(n) on any architecture (Table 4.1). The multiplication of a single row of A with x is also performed by each process in time Q(n). Thus, the entire procedure is completed by n processes in time Q(n), resulting in a process-time product of Q(n2). The parallel algorithm is cost-optimal because the complexity of the serial algorithm is Q(n2). Using Fewer than n ProcessesConsider the case in which p processes are used such that p < n, and the matrix is partitioned among the processes by using block 1-D partitioning. Each process initially stores n/p complete rows of the matrix and a portion of the vector of size n/p. Since the vector x must be multiplied with each row of the matrix, every process needs the entire vector (that is, all the portions belonging to separate processes). This again requires an all-to-all broadcast as shown in Figure 8.1(b) and (c). The all-to-all broadcast takes place among p processes and involves messages of size n/p. After this communication step, each process multiplies its n/p rows with the vector x to produce n/p elements of the result vector. Figure 8.1(d) shows that the result vector y is distributed in the same format as that of the starting vector x. Parallel Run Time According to Table 4.1, an all-to-all broadcast of messages of size n/p among p processes takes time ts log p + tw(n/ p)( p - 1). For large p, this can be approximated by ts log p + twn. After the communication, each process spends time n2/p multiplying its n/p rows with the vector. Thus, the parallel run time of this procedure is
The process-time product for this parallel formulation is n2 + ts p log p + twnp. The algorithm is cost-optimal for p = O(n). Scalability Analysis We now derive the isoefficiency function for matrix-vector multiplication along the lines of the analysis in Section 5.4.2 by considering the terms of the overhead function one at a time. Consider the parallel run time given by Equation 8.2 for the hypercube architecture. The relation To = pTP - W gives the following expression for the overhead function of matrix-vector multiplication on a hypercube with block 1-D partitioning:
Recall from Chapter 5 that the central relation that determines the isoefficiency function of a parallel algorithm is W = KTo (Equation 5.14), where K = E/(1 - E) and E is the desired efficiency. Rewriting this relation for matrix-vector multiplication, first with only the ts term of To,
Equation 8.4 gives the isoefficiency term with respect to message startup time. Similarly, for the tw term of the overhead function,
Since W = n2 (Equation 8.1), we derive an expression for W in terms of p, K , and tw (that is, the isoefficiency function due to tw) as follows:
Now consider the degree of concurrency of this parallel algorithm. Using 1-D partitioning, a maximum of n processes can be used to multiply an n x n matrix with an n x 1 vector. In other words, p is O(n), which yields the following condition:
The overall asymptotic isoefficiency function can be determined by comparing Equations 8.4, 8.5, and 8.6. Among the three, Equations 8.5 and 8.6 give the highest asymptotic rate at which the problem size must increase with the number of processes to maintain a fixed efficiency. This rate of Q(p2) is the asymptotic isoefficiency function of the parallel matrix-vector multiplication algorithm with 1-D partitioning. 8.1.2 2-D PartitioningThis section discusses parallel matrix-vector multiplication for the case in which the matrix is distributed among the processes using a block 2-D partitioning. Figure 8.2 shows the distribution of the matrix and the distribution and movement of vectors among the processes. Figure 8.2. Matrix-vector multiplication with block 2-D partitioning. For the one-element-per-process case, p = n2 if the matrix size is n x n.
One Element Per ProcessWe start with the simple case in which an n x n matrix is partitioned among n2 processes such that each process owns a single element. The n x 1 vector x is distributed only in the last column of n processes, each of which owns one element of the vector. Since the algorithm multiplies the elements of the vector x with the corresponding elements in each row of the matrix, the vector must be distributed such that the ith element of the vector is available to the ith element of each row of the matrix. The communication steps for this are shown in Figure 8.2(a) and (b). Notice the similarity of Figure 8.2 to Figure 8.1. Before the multiplication, the elements of the matrix and the vector must be in the same relative locations as in Figure 8.1(c). However, the vector communication steps differ between various partitioning strategies. With 1-D partitioning, the elements of the vector cross only the horizontal partition-boundaries (Figure 8.1), but for 2-D partitioning, the vector elements cross both horizontal and vertical partition-boundaries (Figure 8.2). As Figure 8.2(a) shows, the first communication step for the 2-D partitioning aligns the vector x along the principal diagonal of the matrix. Often, the vector is stored along the diagonal instead of the last column, in which case this step is not required. The second step copies the vector elements from each diagonal process to all the processes in the corresponding column. As Figure 8.2(b) shows, this step consists of n simultaneous one-to-all broadcast operations, one in each column of processes. After these two communication steps, each process multiplies its matrix element with the corresponding element of x. To obtain the result vector y, the products computed for each row must be added, leaving the sums in the last column of processes. Figure 8.2(c) shows this step, which requires an all-to-one reduction (Section 4.1) in each row with the last process of the row as the destination. The parallel matrix-vector multiplication is complete after the reduction step. Parallel Run Time Three basic communication operations are used in this algorithm: one-to-one communication to align the vector along the main diagonal, one-to-all broadcast of each vector element among the n processes of each column, and all-to-one reduction in each row. Each of these operations takes time Q(log n). Since each process performs a single multiplication in constant time, the overall parallel run time of this algorithm is Q(n). The cost (process-time product) is Q(n2 log n); hence, the algorithm is not cost-optimal. Using Fewer than n2 ProcessesA cost-optimal parallel implementation of matrix-vector multiplication with block 2-D partitioning of the matrix can be obtained if the granularity of computation at each process is increased by using fewer than n2 processes. Consider a logical two-dimensional mesh of p processes in which each process owns an
Parallel Run Time
The first step of sending a message of size
Scalability Analysis By using Equations 8.1 and 8.7, and applying the relation To = pTp - W (Equation 5.1), we get the following expression for the overhead function of this parallel algorithm:
We now perform an approximate isoefficiency analysis along the lines of Section 5.4.2 by considering the terms of the overhead function one at a time (see Problem 8.4 for a more precise isoefficiency analysis). For the ts term of the overhead function, Equation 5.14 yields
Equation 8.9 gives the isoefficiency term with respect to the message startup time. We can obtain the isoefficiency function due to tw by balancing the term
Finally, considering that the degree of concurrency of 2-D partitioning is n2 (that is, a maximum of n2 processes can be used), we arrive at the following relation:
Among Equations 8.9, 8.10, and 8.11, the one with the largest right-hand side expression determines the overall isoefficiency function of this parallel algorithm. To simplify the analysis, we ignore the impact of the constants and consider only the asymptotic rate of the growth of problem size that is necessary to maintain constant efficiency. The asymptotic isoefficiency term due to tw (Equation 8.10) clearly dominates the ones due to ts (Equation 8.9) and due to concurrency (Equation 8.11). Therefore, the overall asymptotic isoefficiency function is given by Q(p log2 p). The isoefficiency function also determines the criterion for cost-optimality (Section 5.4.3). With an isoefficiency function of Q(p log2 p), the maximum number of processes that can be used cost-optimally for a given problem size W is determined by the following relations:
Ignoring the lower-order terms,
Substituting log n for log p in Equation 8.12,
The right-hand side of Equation 8.13 gives an asymptotic upper bound on the number of processes that can be used cost-optimally for an n x n matrix-vector multiplication with a 2-D partitioning of the matrix. Comparison of 1-D and 2-D PartitioningsA comparison of Equations 8.2 and 8.7 shows that matrix-vector multiplication is faster with block 2-D partitioning of the matrix than with block 1-D partitioning for the same number of processes. If the number of processes is greater than n, then the 1-D partitioning cannot be used. However, even if the number of processes is less than or equal to n, the analysis in this section suggests that 2-D partitioning is preferable. Among the two partitioning schemes, 2-D partitioning has a better (smaller) asymptotic isoefficiency function. Thus, matrix-vector multiplication is more scalable with 2-D partitioning; that is, it can deliver the same efficiency on more processes with 2-D partitioning than with 1-D partitioning. |
|
|