|
|
6.6 Collective Communication and Computation OperationsMPI provides an extensive set of functions for performing many commonly used collective communication operations. In particular, the majority of the basic communication operations described in Chapter 4 are supported by MPI. All of the collective communication functions provided by MPI take as an argument a communicator that defines the group of processes that participate in the collective operation. All the processes that belong to this communicator participate in the operation, and all of them must call the collective communication function. Even though collective communication operations do not act like barriers (i.e., it is possible for a processor to go past its call for the collective communication operation even before other processes have reached it), it acts like a virtual synchronization step in the following sense: the parallel program should be written such that it behaves correctly even if a global synchronization is performed before and after the collective call. Since the operations are virtually synchronous, they do not require tags. In some of the collective functions data is required to be sent from a single process (source-process) or to be received by a single process (target-process). In these functions, the source- or target-process is one of the arguments supplied to the routines. All the processes in the group (i.e., communicator) must specify the same source- or target-process. For most collective communication operations, MPI provides two different variants. The first transfers equal-size data to or from each process, and the second transfers data that can be of different sizes. 6.6.1 BarrierThe barrier synchronization operation is performed in MPI using the MPI_Barrier function. int MPI_Barrier(MPI_Comm comm) The only argument of MPI_Barrier is the communicator that defines the group of processes that are synchronized. The call to MPI_Barrier returns only after all the processes in the group have called this function. 6.6.2 BroadcastThe one-to-all broadcast operation described in Section 4.1 is performed in MPI using the MPI_Bcast function.
int MPI_Bcast(void *buf, int count, MPI_Datatype datatype,
int source, MPI_Comm comm)
MPI_Bcast sends the data stored in the buffer buf of process source to all the other processes in the group. The data received by each process is stored in the buffer buf. The data that is broadcast consist of count entries of type datatype. The amount of data sent by the source process must be equal to the amount of data that is being received by each process; i.e., the count and datatype fields must match on all processes. 6.6.3 ReductionThe all-to-one reduction operation described in Section 4.1 is performed in MPI using the MPI_Reduce function.
int MPI_Reduce(void *sendbuf, void *recvbuf, int count,
MPI_Datatype datatype, MPI_Op op, int target,
MPI_Comm comm)
MPI_Reduce combines the elements stored in the buffer sendbuf of each process in the group, using the operation specified in op, and returns the combined values in the buffer recvbuf of the process with rank target. Both the sendbuf and recvbuf must have the same number of count items of type datatype. Note that all processes must provide a recvbuf array, even if they are not the target of the reduction operation. When count is more than one, then the combine operation is applied element-wise on each entry of the sequence. All the processes must call MPI_Reduce with the same value for count, datatype, op, target, and comm. MPI provides a list of predefined operations that can be used to combine the elements stored in sendbuf. MPI also allows programmers to define their own operations, which is not covered in this book. The predefined operations are shown in Table 6.3. For example, in order to compute the maximum of the elements stored in sendbuf, the MPI_MAX value must be used for the op argument. Not all of these operations can be applied to all possible data-types supported by MPI. For example, a bit-wise OR operation (i.e., op = MPI_BOR) is not defined for real-valued data-types such as MPI_FLOAT and MPI_REAL. The last column of Table 6.3 shows the various data-types that can be used with each operation.
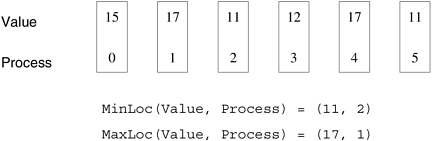
The operation MPI_MAXLOC combines pairs of values (vi, li) and returns the pair (v, l) such that v is the maximum among all vi's and l is the smallest among all li's such that v = vi. Similarly, MPI_MINLOC combines pairs of values and returns the pair (v, l) such that v is the minimum among all vi's and l is the smallest among all li's such that v = vi. One possible application of MPI_MAXLOC or MPI_MINLOC is to compute the maximum or minimum of a list of numbers each residing on a different process and also the rank of the first process that stores this maximum or minimum, as illustrated in Figure 6.6. Since both MPI_MAXLOC and MPI_MINLOC require datatypes that correspond to pairs of values, a new set of MPI datatypes have been defined as shown in Table 6.4. In C, these datatypes are implemented as structures containing the corresponding types. Figure 6.6. An example use of the MPI_MINLOC and MPI_MAXLOC operators.
When the result of the reduction operation is needed by all the processes, MPI provides the MPI_Allreduce operation that returns the result to all the processes. This function provides the functionality of the all-reduce operation described in Section 4.3.
int MPI_Allreduce(void *sendbuf, void *recvbuf, int count,
MPI_Datatype datatype, MPI_Op op, MPI_Comm comm)
Note that there is no target argument since all processes receive the result of the operation. 6.6.4 PrefixThe prefix-sum operation described in Section 4.3 is performed in MPI using the MPI_Scan function.
int MPI_Scan(void *sendbuf, void *recvbuf, int count,
MPI_Datatype datatype, MPI_Op op, MPI_Comm comm)
MPI_Scan performs a prefix reduction of the data stored in the buffer sendbuf at each process and returns the result in the buffer recvbuf. The receive buffer of the process with rank i will store, at the end of the operation, the reduction of the send buffers of the processes whose ranks range from 0 up to and including i. The type of supported operations (i.e., op) as well as the restrictions on the various arguments of MPI_Scan are the same as those for the reduction operation MPI_Reduce. 6.6.5 GatherThe gather operation described in Section 4.4 is performed in MPI using the MPI_Gather function.
int MPI_Gather(void *sendbuf, int sendcount,
MPI_Datatype senddatatype, void *recvbuf, int recvcount,
MPI_Datatype recvdatatype, int target, MPI_Comm comm)
Each process, including the target process, sends the data stored in the array sendbuf to the target process. As a result, if p is the number of processors in the communication comm, the target process receives a total of p buffers. The data is stored in the array recvbuf of the target process, in a rank order. That is, the data from process with rank i are stored in the recvbuf starting at location i * sendcount (assuming that the array recvbuf is of the same type as recvdatatype). The data sent by each process must be of the same size and type. That is, MPI_Gather must be called with the sendcount and senddatatype arguments having the same values at each process. The information about the receive buffer, its length and type applies only for the target process and is ignored for all the other processes. The argument recvcount specifies the number of elements received by each process and not the total number of elements it receives. So, recvcount must be the same as sendcount and their datatypes must be matching. MPI also provides the MPI_Allgather function in which the data are gathered to all the processes and not only at the target process.
int MPI_Allgather(void *sendbuf, int sendcount,
MPI_Datatype senddatatype, void *recvbuf, int recvcount,
MPI_Datatype recvdatatype, MPI_Comm comm)
The meanings of the various parameters are similar to those for MPI_Gather; however, each process must now supply a recvbuf array that will store the gathered data. In addition to the above versions of the gather operation, in which the sizes of the arrays sent by each process are the same, MPI also provides versions in which the size of the arrays can be different. MPI refers to these operations as the vector variants. The vector variants of the MPI_Gather and MPI_Allgather operations are provided by the functions MPI_Gatherv and MPI_Allgatherv, respectively.
int MPI_Gatherv(void *sendbuf, int sendcount,
MPI_Datatype senddatatype, void *recvbuf,
int *recvcounts, int *displs,
MPI_Datatype recvdatatype, int target, MPI_Comm comm)
int MPI_Allgatherv(void *sendbuf, int sendcount,
MPI_Datatype senddatatype, void *recvbuf,
int *recvcounts, int *displs, MPI_Datatype recvdatatype,
MPI_Comm comm)
These functions allow a different number of data elements to be sent by each process by replacing the recvcount parameter with the array recvcounts. The amount of data sent by process i is equal to recvcounts[i]. Note that the size of recvcounts is equal to the size of the communicator comm. The array parameter displs, which is also of the same size, is used to determine where in recvbuf the data sent by each process will be stored. In particular, the data sent by process i are stored in recvbuf starting at location displs[i]. Note that, as opposed to the non-vector variants, the sendcount parameter can be different for different processes. 6.6.6 ScatterThe scatter operation described in Section 4.4 is performed in MPI using the MPI_Scatter function.
int MPI_Scatter(void *sendbuf, int sendcount,
MPI_Datatype senddatatype, void *recvbuf, int recvcount,
MPI_Datatype recvdatatype, int source, MPI_Comm comm)
The source process sends a different part of the send buffer sendbuf to each processes, including itself. The data that are received are stored in recvbuf. Process i receives sendcount contiguous elements of type senddatatype starting from the i * sendcount location of the sendbuf of the source process (assuming that sendbuf is of the same type as senddatatype). MPI_Scatter must be called by all the processes with the same values for the sendcount, senddatatype, recvcount, recvdatatype, source, and comm arguments. Note again that sendcount is the number of elements sent to each individual process. Similarly to the gather operation, MPI provides a vector variant of the scatter operation, called MPI_Scatterv, that allows different amounts of data to be sent to different processes.
int MPI_Scatterv(void *sendbuf, int *sendcounts, int *displs,
MPI_Datatype senddatatype, void *recvbuf, int recvcount,
MPI_Datatype recvdatatype, int source, MPI_Comm comm)
As we can see, the parameter sendcount has been replaced by the array sendcounts that determines the number of elements to be sent to each process. In particular, the target process sends sendcounts[i] elements to process i. Also, the array displs is used to determine where in sendbuf these elements will be sent from. In particular, if sendbuf is of the same type is senddatatype, the data sent to process i start at location displs[i] of array sendbuf. Both the sendcounts and displs arrays are of size equal to the number of processes in the communicator. Note that by appropriately setting the displs array we can use MPI_Scatterv to send overlapping regions of sendbuf. 6.6.7 All-to-AllThe all-to-all personalized communication operation described in Section 4.5 is performed in MPI by using the MPI_Alltoall function.
int MPI_Alltoall(void *sendbuf, int sendcount,
MPI_Datatype senddatatype, void *recvbuf, int recvcount,
MPI_Datatype recvdatatype, MPI_Comm comm)
Each process sends a different portion of the sendbuf array to each other process, including itself. Each process sends to process i sendcount contiguous elements of type senddatatype starting from the i * sendcount location of its sendbuf array. The data that are received are stored in the recvbuf array. Each process receives from process i recvcount elements of type recvdatatype and stores them in its recvbuf array starting at location i * recvcount. MPI_Alltoall must be called by all the processes with the same values for the sendcount, senddatatype, recvcount, recvdatatype, and comm arguments. Note that sendcount and recvcount are the number of elements sent to, and received from, each individual process. MPI also provides a vector variant of the all-to-all personalized communication operation called MPI_Alltoallv that allows different amounts of data to be sent to and received from each process.
int MPI_Alltoallv(void *sendbuf, int *sendcounts, int *sdispls
MPI_Datatype senddatatype, void *recvbuf, int *recvcounts,
int *rdispls, MPI_Datatype recvdatatype, MPI_Comm comm)
The parameter sendcounts is used to specify the number of elements sent to each process, and the parameter sdispls is used to specify the location in sendbuf in which these elements are stored. In particular, each process sends to process i, starting at location sdispls[i] of the array sendbuf, sendcounts[i] contiguous elements. The parameter recvcounts is used to specify the number of elements received by each process, and the parameter rdispls is used to specify the location in recvbuf in which these elements are stored. In particular, each process receives from process i recvcounts[i] elements that are stored in contiguous locations of recvbuf starting at location rdispls[i]. MPI_Alltoallv must be called by all the processes with the same values for the senddatatype, recvdatatype, and comm arguments. 6.6.8 Example: One-Dimensional Matrix-Vector MultiplicationOur first message-passing program using collective communications will be to multiply a dense n x n matrix A with a vector b, i.e., x = Ab. As discussed in Section 8.1, one way of performing this multiplication in parallel is to have each process compute different portions of the product-vector x. In particular, each one of the p processes is responsible for computing n/p consecutive elements of x. This algorithm can be implemented in MPI by distributing the matrix A in a row-wise fashion, such that each process receives the n/p rows that correspond to the portion of the product-vector x it computes. Vector b is distributed in a fashion similar to x. Program 6.4 shows the MPI program that uses a row-wise distribution of matrix A. The dimension of the matrices is supplied in the parameter n, the parameters a and b point to the locally stored portions of matrix A and vector b, respectively, and the parameter x points to the local portion of the output matrix-vector product. This program assumes that n is a multiple of the number of processors. Program 6.4 Row-wise Matrix-Vector Multiplication
1 RowMatrixVectorMultiply(int n, double *a, double *b, double *x,
2 MPI_Comm comm)
3 {
4 int i, j;
5 int nlocal; /* Number of locally stored rows of A */
6 double *fb; /* Will point to a buffer that stores the entire vector b */
7 int npes, myrank;
8 MPI_Status status;
9
10 /* Get information about the communicator */
11 MPI_Comm_size(comm, &npes);
12 MPI_Comm_rank(comm, &myrank);
13
14 /* Allocate the memory that will store the entire vector b */
15 fb = (double *)malloc(n*sizeof(double));
16
17 nlocal = n/npes;
18
19 /* Gather the entire vector b on each processor using MPI's ALLGATHER operation */
20 MPI_Allgather(b, nlocal, MPI_DOUBLE, fb, nlocal, MPI_DOUBLE,
21 comm);
22
23 /* Perform the matrix-vector multiplication involving the locally stored submatrix */
24 for (i=0; i<nlocal; i++) {
25 x[i] = 0.0;
26 for (j=0; j<n; j++)
27 x[i] += a[i*n+j]*fb[j];
28 }
29
30 free(fb);
31 }
An alternate way of computing x is to parallelize the task of performing the dot-product for each element of x. That is, for each element xi, of vector x, all the processes will compute a part of it, and the result will be obtained by adding up these partial dot-products. This algorithm can be implemented in MPI by distributing matrix A in a column-wise fashion. Each process gets n/p consecutive columns of A, and the elements of vector b that correspond to these columns. Furthermore, at the end of the computation we want the product-vector x to be distributed in a fashion similar to vector b. Program 6.5 shows the MPI program that implements this column-wise distribution of the matrix. Program 6.5 Column-wise Matrix-Vector Multiplication
1 ColMatrixVectorMultiply(int n, double *a, double *b, double *x,
2 MPI_Comm comm)
3 {
4 int i, j;
5 int nlocal;
6 double *px;
7 double *fx;
8 int npes, myrank;
9 MPI_Status status;
10
11 /* Get identity and size information from the communicator */
12 MPI_Comm_size(comm, &npes);
13 MPI_Comm_rank(comm, &myrank);
14
15 nlocal = n/npes;
16
17 /* Allocate memory for arrays storing intermediate results. */
18 px = (double *)malloc(n*sizeof(double));
19 fx = (double *)malloc(n*sizeof(double));
20
21 /* Compute the partial-dot products that correspond to the local columns of A.*/
22 for (i=0; i<n; i++) {
23 px[i] = 0.0;
24 for (j=0; j<nlocal; j++)
25 px[i] += a[i*nlocal+j]*b[j];
26 }
27
28 /* Sum-up the results by performing an element-wise reduction operation */
29 MPI_Reduce(px, fx, n, MPI_DOUBLE, MPI_SUM, 0, comm);
30
31 /* Redistribute fx in a fashion similar to that of vector b */
32 MPI_Scatter(fx, nlocal, MPI_DOUBLE, x, nlocal, MPI_DOUBLE, 0,
33 comm);
34
35 free(px); free(fx);
36 }
Comparing these two programs for performing matrix-vector multiplication we see that the row-wise version needs to perform only a MPI_Allgather operation whereas the column-wise program needs to perform a MPI_Reduce and a MPI_Scatter operation. In general, a row-wise distribution is preferable as it leads to small communication overhead (see Problem 6.6). However, many times, an application needs to compute not only Ax but also AT x. In that case, the row-wise distribution can be used to compute Ax, but the computation of AT x requires the column-wise distribution (a row-wise distribution of A is a column-wise distribution of its transpose AT). It is much cheaper to use the program for the column-wise distribution than to transpose the matrix and then use the row-wise program. We must also note that using a dual of the all-gather operation, it is possible to develop a parallel formulation for column-wise distribution that is as fast as the program using row-wise distribution (see Problem 6.7). However, this dual operation is not available in MPI. 6.6.9 Example: Single-Source Shortest-PathOur second message-passing program that uses collective communication operations computes the shortest paths from a source-vertex s to all the other vertices in a graph using Dijkstra's single-source shortest-path algorithm described in Section 10.3. This program is shown in Program 6.6. The parameter n stores the total number of vertices in the graph, and the parameter source stores the vertex from which we want to compute the single-source shortest path. The parameter wgt points to the locally stored portion of the weighted adjacency matrix of the graph. The parameter lengths points to a vector that will store the length of the shortest paths from source to the locally stored vertices. Finally, the parameter comm is the communicator to be used by the MPI routines. Note that this routine assumes that the number of vertices is a multiple of the number of processors. Program 6.6 Dijkstra's Single-Source Shortest-Path
1 SingleSource(int n, int source, int *wgt, int *lengths, MPI_Comm comm)
2 {
3 int i, j;
4 int nlocal; /* The number of vertices stored locally */
5 int *marker; /* Used to mark the vertices belonging to Vo */
6 int firstvtx; /* The index number of the first vertex that is stored locally */
7 int lastvtx; /* The index number of the last vertex that is stored locally */
8 int u, udist;
9 int lminpair[2], gminpair[2];
10 int npes, myrank;
11 MPI_Status status;
12
13 MPI_Comm_size(comm, &npes);
14 MPI_Comm_rank(comm, &myrank);
15
16 nlocal = n/npes;
17 firstvtx = myrank*nlocal;
18 lastvtx = firstvtx+nlocal-1;
19
20 /* Set the initial distances from source to all the other vertices */
21 for (j=0; j<nlocal; j++)
22 lengths[j] = wgt[source*nlocal + j];
23
24 /* This array is used to indicate if the shortest part to a vertex has been found
The main computational loop of Dijkstra's parallel single-source shortest path algorithm performs three steps. First, each process finds the locally stored vertex in Vo that has the smallest distance from the source. Second, the vertex that has the smallest distance over all processes is determined, and it is included in Vc. Third, all processes update their distance arrays to reflect the inclusion of the new vertex in Vc. The first step is performed by scanning the locally stored vertices in Vo and determining the one vertex v with the smaller lengths[v] value. The result of this computation is stored in the array lminpair. In particular, lminpair[0] stores the distance of the vertex, and lminpair[1] stores the vertex itself. The reason for using this storage scheme will become clear when we consider the next step, in which we must compute the vertex that has the smallest overall distance from the source. We can find the overall shortest distance by performing a min-reduction on the distance values stored in lminpair[0]. However, in addition to the shortest distance, we also need to know the vertex that is at that shortest distance. For this reason, the appropriate reduction operation is the MPI_MINLOC which returns both the minimum as well as an index value associated with that minimum. Because of MPI_MINLOC we use the two-element array lminpair to store the distance as well as the vertex that achieves this distance. Also, because the result of the reduction operation is needed by all the processes to perform the third step, we use the MPI_Allreduce operation to perform the reduction. The result of the reduction operation is returned in the gminpair array. The third and final step during each iteration is performed by scanning the local vertices that belong in Vo and updating their shortest distances from the source vertex. Avoiding Load Imbalances Program 6.6 assigns n/p consecutive columns of W to each processor and in each iteration it uses the MPI_MINLOC reduction operation to select the vertex v to be included in Vc. Recall that the MPI_MINLOC operation for the pairs (a, i) and (a, j) will return the one that has the smaller index (since both of them have the same value). Consequently, among the vertices that are equally close to the source vertex, it favors the smaller numbered vertices. This may lead to load imbalances, because vertices stored in lower-ranked processes will tend to be included in Vc faster than vertices in higher-ranked processes (especially when many vertices in Vo are at the same minimum distance from the source). Consequently, the size of the set Vo will be larger in higher-ranked processes, dominating the overall runtime. One way of correcting this problem is to distribute the columns of W using a cyclic distribution. In this distribution process i gets every pth vertex starting from vertex i. This scheme also assigns n/p vertices to each process but these vertices have indices that span almost the entire graph. Consequently, the preference given to lower-numbered vertices by MPI_MINLOC does not lead to load-imbalance problems. 6.6.10 Example: Sample SortThe last problem requiring collective communications that we will consider is that of sorting a sequence A of n elements using the sample sort algorithm described in Section 9.5. The program is shown in Program 6.7. The SampleSort function takes as input the sequence of elements stored at each process and returns a pointer to an array that stores the sorted sequence as well as the number of elements in this sequence. The elements of this SampleSort function are integers and they are sorted in increasing order. The total number of elements to be sorted is specified by the parameter n and a pointer to the array that stores the local portion of these elements is specified by elmnts. On return, the parameter nsorted will store the number of elements in the returned sorted array. This routine assumes that n is a multiple of the number of processes. Program 6.7 Samplesort
1 int *SampleSort(int n, int *elmnts, int *nsorted, MPI_Comm comm)
2 {
3 int i, j, nlocal, npes, myrank;
4 int *sorted_elmnts, *splitters, *allpicks;
5 int *scounts, *sdispls, *rcounts, *rdispls;
6
7 /* Get communicator-related information */
8 MPI_Comm_size(comm, &npes);
9 MPI_Comm_rank(comm, &myrank);
10
11 nlocal = n/npes;
12
13 /* Allocate memory for the arrays that will store the splitters */
14 splitters = (int *)malloc(npes*sizeof(int));
15 allpicks = (int *)malloc(npes*(npes-1)*sizeof(int));
16
17 /* Sort local array */
18 qsort(elmnts, nlocal, sizeof(int), IncOrder);
19
20 /* Select local npes-1 equally spaced elements */
21 for (i=1; i<npes; i++)
22 splitters[i-1] = elmnts[i*nlocal/npes];
23
24 /* Gather the samples in the processors */
25 MPI_Allgather(splitters, npes-1, MPI_INT, allpicks, npes-1,
26 MPI_INT, comm);
27
28 /* sort these samples */
29 qsort(allpicks, npes*(npes-1), sizeof(int), IncOrder);
30
31 /* Select splitters */
32 for (i=1; i<npes; i++)
33 splitters[i-1] = allpicks[i*npes];
34 splitters[npes-1] = MAXINT;
35
36 /* Compute the number of elements that belong to each bucket */
37 scounts = (int *)malloc(npes*sizeof(int));
38 for (i=0; i<npes; i++)
39 scounts[i] = 0;
40
41 for (j=i=0; i<nlocal; i++) {
42 if (elmnts[i] < splitters[j])
43 scounts[j]++;
44 else
45 scounts[++j]++;
46 }
47
48 /* Determine the starting location of each bucket's elements in the elmnts array */
49 sdispls = (int *)malloc(npes*sizeof(int));
50 sdispls[0] = 0;
51 for (i=1; i<npes; i++)
52 sdispls[i] = sdispls[i-1]+scounts[i-1];
53
54 /* Perform an all-to-all to inform the corresponding processes of the number of
|
|
|