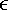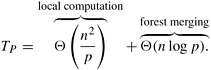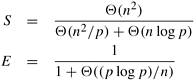|
|
10.6 Connected ComponentsThe connected components of an undirected graph G = (V, E) are the maximal disjoint sets C1, C2, ..., Ck such that V = C1 Figure 10.10. A graph with three connected components: {1, 2, 3, 4}, {5, 6, 7}, and {8, 9}.
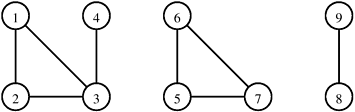
10.6.1 A Depth-First Search Based AlgorithmWe can find the connected components of a graph by performing a depth-first traversal on the graph. The outcome of this depth-first traversal is a forest of depth-first trees. Each tree in the forest contains vertices that belong to a different connected component. Figure 10.11 illustrates this algorithm. The correctness of this algorithm follows directly from the definition of a spanning tree (that is, a depth-first tree is also a spanning tree of a graph induced by the set of vertices in the depth-first tree) and from the fact that G is undirected. Assuming that the graph is stored using a sparse representation, the run time of this algorithm is Q(|E|) because the depth-first traversal algorithm traverses all the edges in G. Figure 10.11. Part (b) is a depth-first forest obtained from depth-first traversal of the graph in part (a). Each of these trees is a connected component of the graph in part (a).
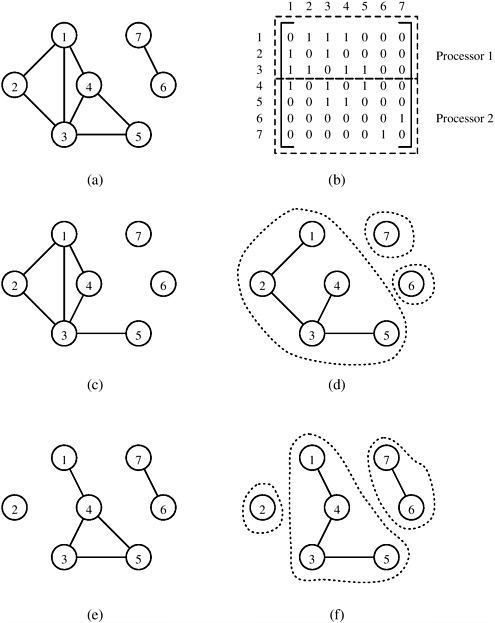
Parallel FormulationThe connected-component algorithm can be parallelized by partitioning the adjacency matrix of G into p parts and assigning each part to one of p processes. Each process Pi has a subgraph Gi of G, where Gi = (V, Ei) and Ei are the edges that correspond to the portion of the adjacency matrix assigned to this process. In the first step of this parallel formulation, each process Pi computes the depth-first spanning forest of the graph Gi. At the end of this step, p spanning forests have been constructed. During the second step, spanning forests are merged pairwise until only one spanning forest remains. The remaining spanning forest has the property that two vertices are in the same connected component of G if they are in the same tree. Figure 10.12 illustrates this algorithm. Figure 10.12. Computing connected components in parallel. The adjacency matrix of the graph G in (a) is partitioned into two parts as shown in (b). Next, each process gets a subgraph of G as shown in (c) and (e). Each process then computes the spanning forest of the subgraph, as shown in (d) and (f). Finally, the two spanning trees are merged to form the solution.
To merge pairs of spanning forests efficiently, the algorithm uses disjoint sets of edges. Assume that each tree in the spanning forest of a subgraph of G is represented by a set. The sets for different trees are pairwise disjoint. The following operations are defined on the disjoint sets:
The spanning forests are merged as follows. Let A and B be the two spanning forests to be merged. At most n - 1 edges (since A and B are forests) of one are merged with the edges of the other. Suppose we want to merge forest A into forest B. For each edge (u, v) of A, a find operation is performed for each vertex to determine if the two vertices are already in the same tree of B . If not, then the two trees (sets) of B containing u and v are united by a union operation. Otherwise, no union operation is necessary. Hence, merging A and B requires at most 2(n - 1) find operations and (n - 1) union operations. We can implement the disjoint-set data structure by using disjoint-set forests with ranking and path compression. Using this implementation, the cost of performing 2(n - 1) finds and (n - 1) unions is O (n). A detailed description of the disjoint-set forest is beyond the scope of this book. Refer to the bibliographic remarks (Section 10.8) for references. Having discussed how to efficiently merge two spanning forests, we now concentrate on how to partition the adjacency matrix of G and distribute it among p processes. The next section discusses a formulation that uses 1-D block mapping. An alternative partitioning scheme is discussed in Problem 10.12. 1-D Block Mapping The n x n adjacency matrix is partitioned into p stripes (Section 3.4.1). Each stripe is composed of n/p consecutive rows and is assigned to one of the p processes. To compute the connected components, each process first computes a spanning forest for the n-vertex graph represented by the n/p rows of the adjacency matrix assigned to it. Consider a p-process message-passing computer. Computing the spanning forest based on the (n/p) x n adjacency matrix assigned to each process requires time Q(n2/p). The second step of the algorithm-the pairwise merging of spanning forests - is performed by embedding a virtual tree on the processes. There are log p merging stages, and each takes time Q(n). Thus, the cost due to merging is Q(n log p). Finally, during each merging stage, spanning forests are sent between nearest neighbors. Recall that Q(n) edges of the spanning forest are transmitted. Thus, the communication cost is Q(n log p). The parallel run time of the connected-component algorithm is
Since the sequential complexity is W = Q(n2), the speedup and efficiency are as follows:
From Equation 10.8 we see that for a cost-optimal formulation p = O (n/log n). Also from Equation 10.8, we derive the isoefficiency function, which is Q(p2 log2 p). This is the isoefficiency function due to communication and due to the extra computations performed in the merging stage. The isoefficiency function due to concurrency is Q(p2); thus, the overall isoefficiency function is Q(p2 log2 p). The performance of this parallel formulation is similar to that of Prim's minimum spanning tree algorithm and Dijkstra's single-source shortest paths algorithm on a message-passing computer. |
|
|