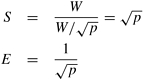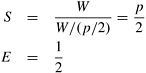|
|
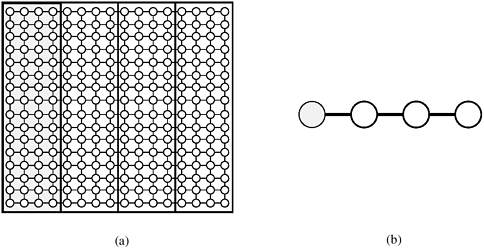
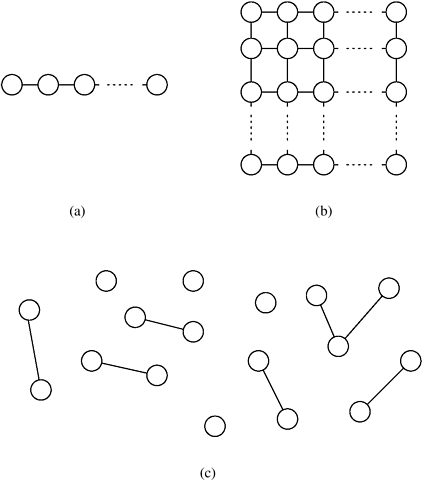
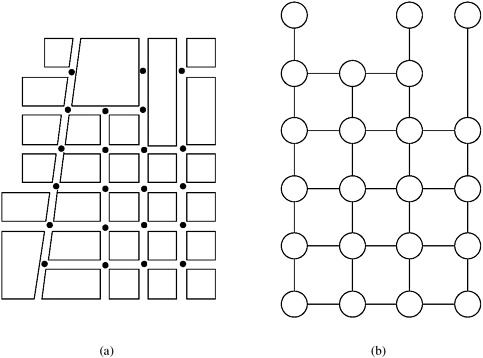
10.7 Algorithms for Sparse GraphsThe parallel algorithms in the previous sections are based on the best-known algorithms for dense-graph problems. However, we have yet to address parallel algorithms for sparse graphs. Recall that a graph G = (V, E) is sparse if |E| is much smaller than |V|2. Figure 10.13 shows some examples of sparse graphs. Figure 10.13. Examples of sparse graphs: (a) a linear graph, in which each vertex has two incident edges; (b) a grid graph, in which each vertex has four incident vertices; and (c) a random sparse graph.
Any dense-graph algorithm works correctly on sparse graphs as well. However, if the sparseness of the graph is taken into account, it is usually possible to obtain significantly better performance. For example, the run time of Prim's minimum spanning tree algorithm (Section 10.2) is Q(n2) regardless of the number of edges in the graph. By modifying Prim's algorithm to use adjacency lists and a binary heap, the complexity of the algorithm reduces to Q(|E| log n). This modified algorithm outperforms the original algorithm as long as |E|=O (n2/log n). An important step in developing sparse-graph algorithms is to use an adjacency list instead of an adjacency matrix. This change in representation is crucial, since the complexity of adjacency-matrix-based algorithms is usually W(n2), and is independent of the number of edges. Conversely, the complexity of adjacency-list-based algorithms is usually W(n + |E|), which depends on the sparseness of the graph. In the parallel formulations of sequential algorithms for dense graphs, we obtained good performance by partitioning the adjacency matrix of a graph so that each process performed roughly an equal amount of work and communication was localized. We were able to achieve this largely because the graph was dense. For example, consider Floyd's all-pairs shortest paths algorithm. By assigning equal-sized blocks from the adjacency matrix to all processes, the work was uniformly distributed. Moreover, since each block consisted of consecutive rows and columns, the communication overhead was limited. However, it is difficult to achieve even work distribution and low communication overhead for sparse graphs. Consider the problem of partitioning the adjacency list of a graph. One possible partition assigns an equal number of vertices and their adjacency lists to each process. However, the number of edges incident on a given vertex may vary. Hence, some processes may be assigned a large number of edges while others receive very few, leading to a significant work imbalance among the processes. Alternately, we can assign an equal number of edges to each process. This may require splitting the adjacency list of a vertex among processes. As a result, the time spent communicating information among processes that store separate parts of the adjacency list may increase dramatically. Thus, it is hard to derive efficient parallel formulations for general sparse graphs (Problems 10.14 and 10.15). However, we can often derive efficient parallel formulations if the sparse graph has a certain structure. For example, consider the street map shown in Figure 10.14. The graph corresponding to the map is sparse: the number of edges incident on any vertex is at most four. We refer to such graphs as grid graphs. Other types of sparse graphs for which an efficient parallel formulation can be developed are those corresponding to well-shaped finite element meshes, and graphs whose vertices have similar degrees. The next two sections present efficient algorithms for finding a maximal independent set of vertices, and for computing single-source shortest paths for these types of graphs. Figure 10.14. A street map (a) can be represented by a graph (b). In the graph shown in (b), each street intersection is a vertex and each edge is a street segment. The vertices of (b) are the intersections of (a) marked by dots.
10.7.1 Finding a Maximal Independent SetConsider the problem of finding a maximal independent set (MIS) of vertices of a graph. We are given a sparse undirected graph G = (V, E). A set of vertices I Figure 10.15. Examples of independent and maximal independent sets.
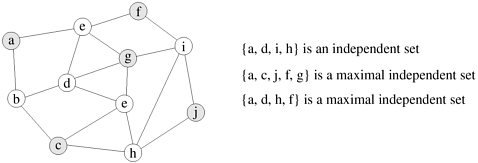
Many algorithms have been proposed for computing a maximal independent set of vertices. The simplest class of algorithms starts by initially setting I to be empty, and assigning all vertices to a set C that acts as the candidate set of vertices for inclusion in I . Then the algorithm proceeds by repeatedly moving a vertex v from C into I and removing all vertices adjacent to v from C. This process terminates when C becomes empty, in which case I is a maximal independent set. The resulting set I will contain an independent set of vertices, because every time we add a vertex into I we remove from C all the vertices whose subsequent inclusion will violate the independence condition. Also, the resulting set is maximal, because any other vertex that is not already in I is adjacent to at least one of the vertices in I. Even though the above algorithm is very simple, it is not well suited for parallel processing, as it is serial in nature. For this reason parallel MIS algorithms are usually based on the randomized algorithm originally developed by Luby for computing a coloring of a graph. Using Luby's algorithm, a maximal independent set I of vertices V a graph is computed in an incremental fashion as follows. The set I is initially set to be empty, and the set of candidate vertices, C, is set to be equal to V. A unique random number is assigned to each vertex in C, and if a vertex has a random number that is smaller than all of the random numbers of the adjacent vertices, it is included in I. The set C is updated so that all the vertices that were selected for inclusion in I and their adjacent vertices are removed from it. Note that the vertices that are selected for inclusion in I are indeed independent (i.e., not directly connected via an edge). This is because, if v was inserted in I, then the random number assigned to v is the smallest among the random numbers assigned to its adjacent vertices; thus, no other vertex u adjacent to v will have been selected for inclusion. Now the above steps of random number assignment and vertex selection are repeated for the vertices left in C, and I is augmented similarly. This incremental augmentation of I ends when C becomes empty. On the average, this algorithm converges after O (log |V|) such augmentation steps. The execution of the algorithm for a small graph is illustrated in Figure 10.16. In the rest of this section we describe a shared-address-space parallel formulation of Luby's algorithm. A message-passing adaption of this algorithm is described in the message-passing chapter. Figure 10.16. The different augmentation steps of Luby's randomized maximal independent set algorithm. The numbers inside each vertex correspond to the random number assigned to the vertex.
Shared-Address-Space Parallel FormulationA parallel formulation of Luby's MIS algorithm for a shared-address-space parallel computer is as follows. Let I be an array of size |V|. At the termination of the algorithm, I [i] will store one, if vertex vi is part of the MIS, or zero otherwise. Initially, all the elements in I are set to zero, and during each iteration of Luby's algorithm, some of the entries of that array will be changed to one. Let C be an array of size |V|. During the course of the algorithm, C [i] is one if vertex vi is part of the candidate set, or zero otherwise. Initially, all the elements in C are set to one. Finally, let R be an array of size |V| that stores the random numbers assigned to each vertex. During each iteration, the set C is logically partitioned among the p processes. Each process generates a random number for its assigned vertices from C. When all the processes finish generating these random numbers, they proceed to determine which vertices can be included in I. In particular, for each vertex assigned to them, they check to see if the random number assigned to it is smaller than the random numbers assigned to all of its adjacent vertices. If it is true, they set the corresponding entry in I to one. Because R is shared and can be accessed by all the processes, determining whether or not a particular vertex can be included in I is quite straightforward. Array C can also be updated in a straightforward fashion as follows. Each process, as soon as it determines that a particular vertex v will be part of I, will set to zero the entries of C corresponding to its adjacent vertices. Note that even though more than one process may be setting to zero the same entry of C (because it may be adjacent to more than one vertex that was inserted in I), such concurrent writes will not affect the correctness of the results, because the value that gets concurrently written is the same. The complexity of each iteration of Luby's algorithm is similar to that of the serial algorithm, with the extra cost of the global synchronization after each random number assignment. The detailed analysis of Luby's algorithm is left as an exercise (Problem 10.16). 10.7.2 Single-Source Shortest PathsIt is easy to modify Dijkstra's single-source shortest paths algorithm so that it finds the shortest paths for sparse graphs efficiently. The modified algorithm is known as Johnson's algorithm. Recall that Dijkstra's algorithm performs the following two steps in each iteration. First, it extracts a vertex u Johnson's algorithm uses a priority queue Q to store the value l[v] for each vertex v Algorithm 10.5 Johnson's sequential single-source shortest paths algorithm.1. procedure JOHNSON_SINGLE_SOURCE_SP(V, E, s) 2. begin 3. Q := V ; 4. for all v Parallelization StrategyAn efficient parallel formulation of Johnson's algorithm must maintain the priority queue Q efficiently. A simple strategy is for a single process, for example, P0, to maintain Q. All other processes will then compute new values of l[v] for v The first limitation can be alleviated by distributing the maintainance of the priority queue to multiple processes. This is a non-trivial task, and can only be done effectively on architectures with low latency, such as shared-address-space computers. However, even in the best case, when each priority queue update takes only time O (1), the maximum speedup that can be achieved is O (log n), which is quite small. The second limitation can be alleviated by recognizing the fact that depending on the l value of the vertices at the top of the priority queue, more than one vertex can be extracted at the same time. In particular, if v is the vertex at the top of the priority queue, all vertices u such that l[u] = l[v] can also be extracted, and their adjacency lists processed concurrently. This is because the vertices that are at the same minimum distance from the source can be processed in any order. Note that in order for this approach to work, all the vertices that are at the same minimum distance must be processed in lock-step. An additional degree of concurrency can be extracted if we know that the minimum weight over all the edges in the graph is m. In that case, all vertices u such that l[u] Our discussion thus far was focused on developing a parallel formulation of Johnson's algorithm that finds the shortest paths to the vertices in the same order as the serial algorithm, and explores concurrently only safe vertices. However, as we have seen, such an approach leads to complicated algorithms and limited concurrency. An alternate approach is to develop a parallel algorithm that processes both safe and unsafe vertices concurrently, as long as these unsafe vertices can be reached from the source via a path involving vertices whose shortest paths have already been computed (i.e., their corresponding l-value in the priority queue is not infinite). In particular, in this algorithm, each one of the p processes extracts one of the p top vertices and proceeds to update the l values of the vertices adjacent to it. Of course, the problem with this approach is that it does not ensure that the l values of the vertices extracted from the priority queue correspond to the cost of the shortest path. For example, consider two vertices v and u that are at the top of the priority queue, with l[v] < l[u]. According to Johnson's algorithm, at the point a vertex is extracted from the priority queue, its l value is the cost of the shortest path from the source to that vertex. Now, if there is an edge connecting v and u, such that l[v] + w(v, u) < l[u], then the correct value of the shortest path to u is l[v] + w(v, u), and not l[u]. However, the correctness of the results can be ensured by detecting when we have incorrectly computed the shortest path to a particular vertex, and inserting it back into the priority queue with the updated l value. We can detect such instances as follows. Consider a vertex v that has just been extracted from the queue, and let u be a vertex adjacent to v that has already been extracted from the queue. If l[v] + w(v, u) is smaller than l[u], then the shortest path to u has been incorrectly computed, and u needs to be inserted back into the priority queue with l[u] = l[v] + w(v, u). To see how this approach works, consider the example grid graph shown in Figure 10.17. In this example, there are three processes and we want to find the shortest path from vertex a. After initialization of the priority queue, vertices b and d will be reachable from the source. In the first step, process P0 and P1 extract vertices b and d and proceed to update the l values of the vertices adjacent to b and d. In the second step, processes P0, P1, and P2 extract e, c, and g, and proceed to update the l values of the vertices adjacent to them. Note that when processing vertex e, process P0 checks to see if l[e] + w(e, d) is smaller or greater than l[d]. In this particular example, l[e] + w(e, d) > l[d], indicating that the previously computed value of the shortest path to d does not change when e is considered, and all computations so far are correct. In the third step, processes P0 and P1 work on h and f, respectively. Now, when process P0 compares l[h] + w(h, g) = 5 against the value of l[g] = 10 that was extracted in the previous iteration, it finds it to be smaller. As a result, it inserts back into the priority queue vertex g with the updated l[g] value. Finally, in the fourth and last step, the remaining two vertices are extracted from the priority queue, and all single-source shortest paths have been computed. Figure 10.17. An example of the modified Johnson's algorithm for processing unsafe vertices concurrently.
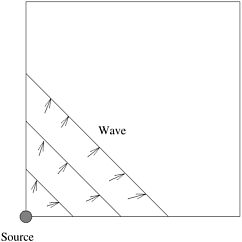
This approach for parallelizing Johnson's algorithm falls into the category of speculative decomposition discussed in Section 3.2.4. Essentially, the algorithm assumes that the l[] values of the top p vertices in the priority queue will not change as a result of processing some of these vertices, and proceeds to perform the computations required by Johnson's algorithm. However, if at some later point it detects that its assumptions were wrong, it goes back and essentially recomputes the shortest paths of the affected vertices. In order for such a speculative decomposition approach to be effective, we must also remove the bottleneck of working with a single priority queue. In the rest of this section we present a message-passing algorithm that uses speculative decomposition to extract concurrency and in which there is no single priority queue. Instead, each process maintains its own priority queue for the vertices that it is assigned to. Problem 10.13 discusses another approach. Distributed Memory FormulationLet p be the number of processes, and let G = (V, E) be a sparse graph. We partition the set of vertices V into p disjoint sets V1, V2, ..., Vp, and assign each set of vertices and its associated adjacency lists to one of the p processes. Each process maintains a priority queue for the vertices assigned to it, and computes the shortest paths from the source to these vertices. Thus, the priority queue Q is partitioned into p disjoint priority queues Q1, Q2, ..., Qp, each assigned to a separate process. In addition to the priority queue, each process Pi also maintains an array sp such that sp[v] stores the cost of the shortest path from the source vertex to v for each vertex v When process Pi extracts the vertex u Since both processes Pi and Pj execute Johnson's algorithm, it is possible that process Pj has already extracted vertex v from its priority queue. This means that process Pj might have already computed the shortest path sp[v] from the source to vertex v. Then there are two possible cases: either sp[v] Initially, only the priority queue of the process with the source vertex is non-empty. After that, the priority queues of other processes become populated as messages containing new l values are created and sent to adjacent processes. When processes receive new l values, they insert them into their priority queues and perform computations. Consider the problem of computing the single-source shortest paths in a grid graph where the source is located at the bottom-left corner. The computations propagate across the grid graph in the form of a wave. A process is idle before the wave arrives, and becomes idle again after the wave has passed. This process is illustrated in Figure 10.18. At any time during the execution of the algorithm, only the processes along the wave are busy. The other processes have either finished their computations or have not yet started them. The next sections discuss three mappings of grid graphs onto a p-process mesh. Figure 10.18. The wave of activity in the priority queues.
2-D Block Mapping
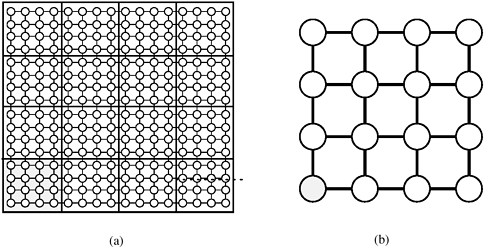
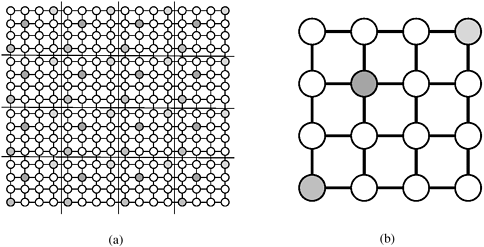
One way to map an n x n grid graph onto p processors is to use the 2-D block mapping (Section 3.4.1). Specifically, we can view the p processes as a logical mesh and assign a different block of Figure 10.19. Mapping the grid graph (a) onto a mesh, and (b) by using the 2-D block mapping. In this example, n = 16 and
|
|
|
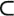
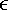 (
(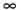 in the priority queue. For the source vertex
in the priority queue. For the source vertex 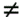 0
0