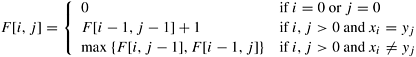|
|
12.3 Nonserial Monadic DP FormulationsThe DP algorithm for determining the longest common subsequence of two given sequences can be formulated as a nonserial monadic DP formulation. 12.3.1 The Longest-Common-Subsequence ProblemGiven a sequence A = <a1, a2, ..., an>, a subsequence of A can be formed by deleting some entries from A. For example, <a, b, z> is a subsequence of <c, a, d, b, r, z>, but <a, c, z> and <a, d, l> are not. The longest-common-subsequence (LCS) problem can be stated as follows. Given two sequences A = <a1, a2, ..., an> and B = <b1, b2, ..., bm>, find the longest sequence that is a subsequence of both A and B. For example, if A = <c, a, d, b, r, z> and B = <a, s, b, z>, the longest common subsequence of A and B is <a, b, z>. Let F [i, j] denote the length of the longest common subsequence of the first i elements of A and the first j elements of B. The objective of the LCS problem is to determine F [n, m]. The DP formulation for this problem expresses F [i, j] in terms of F [i - 1, j - 1], F [i, j - 1], and F [i - 1, j] as follows:
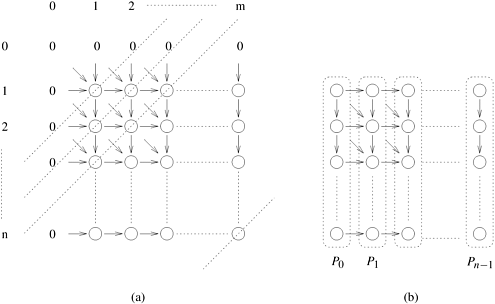
Given sequences A and B , consider two pointers pointing to the start of the sequences. If the entries pointed to by the two pointers are identical, then they form components of the longest common subsequence. Therefore, both pointers can be advanced to the next entry of the respective sequences and the length of the longest common subsequence can be incremented by one. If the entries are not identical then two situations arise: the longest common subsequence may be obtained from the longest subsequence of A and the sequence obtained by advancing the pointer to the next entry of B; or the longest subsequence may be obtained from the longest subsequence of B and the sequence obtained by advancing the pointer to the next entry of A. Since we want to determine the longest subsequence, the maximum of these two must be selected. The sequential implementation of this DP formulation computes the values in table F in row-major order. Since there is a constant amount of computation at each entry in the table, the overall complexity of this algorithm is Q(nm). This DP formulation is nonserial monadic, as illustrated in Figure 12.5(a). Treating nodes along a diagonal as belonging to one level, each node depends on two subproblems at the preceding level and one subproblem two levels earlier. The formulation is monadic because a solution to any subproblem at a level is a function of only one of the solutions at preceding levels. (Note that, for the third case in Equation 12.5, both F [i, j - 1] and F [i - 1, j] are possible solutions to F [i, j], and the optimal solution to F [i, j] is the maximum of the two.) Figure 12.5 shows that this problem has a very regular structure. Figure 12.5. (a) Computing entries of table F for the longest-common-subsequence problem. Computation proceeds along the dotted diagonal lines. (b) Mapping elements of the table to processing elements.
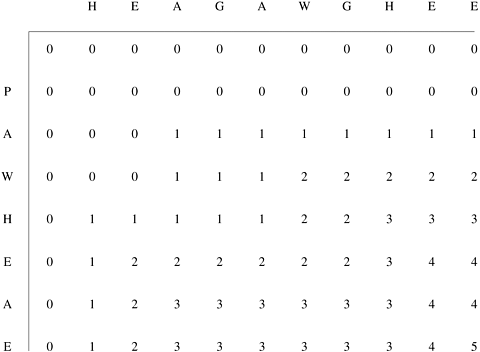
Example 12.2 Computing LCS of two amino-acid sequences Let us consider the LCS of two amino-acid sequences H E A G A W G H E E and P A W H E A E. For the interested reader, the names of the corresponding amino-acids are A: Alanine, E: Glutamic acid, G: Glycine, H: Histidine, P: Proline, and W: Tryptophan. The table of F entries for these two sequences is shown in Figure 12.6. The LCS of the two sequences, as determined by tracing back from the maximum score and enumerating all the matches, is A W H E E. Figure 12.6. The F table for computing the LCS of sequences H E A G A W G H E E and P A W H E A E.
To simplify the discussion, we discuss parallel formulation only for the case in which n = m. Consider a parallel formulation of this algorithm on a CREW PRAM with n processing elements. Each processing element Pi computes the ith column of table F. Table entries are computed in a diagonal sweep from the top-left to the bottom-right corner. Since there are n processing elements, and each processing element can access any entry in table F, the elements of each diagonal are computed in constant time (the diagonal can contain at most n elements). Since there are 2n - 1 such diagonals, the algorithm requires Q(n) iterations. Thus, the parallel run time is Q(n). The algorithm is cost-optimal, since its Q(n2) processor-time product equals the sequential complexity. This algorithm can be adapted to run on a logical linear array of n processing elements by distributing table F among different processing elements. Note that this logical topology can be mapped to a variety of physical architectures using embedding techniques in Section 2.7.1. Processing element Pi stores the (i + 1)th column of the table. Entries in table F are assigned to processing elements as illustrated in Figure 12.5(b). When computing the value of F [i, j], processing element Pj -1 may need either the value of F [i - 1, j - 1] or the value of F [i, j - 1] from the processing element to its left. It takes time ts + tw to communicate a single word from a neighboring processing element. To compute each entry in the table, a processing element needs a single value from its immediate neighbor, followed by the actual computation, which takes time tc. Since each processing element computes a single entry on the diagonal, each iteration takes time (ts + tw + tc). The algorithm makes (2n - 1) diagonal sweeps (iterations) across the table; thus, the total parallel run time is
Since the sequential run time is n2tc, the efficiency of this algorithm is
A careful examination of this expression reveals that it is not possible to obtain efficiencies above a certain threshold. To compute this threshold, assume it is possible to communicate values between processing elements instantaneously; that is, ts = tw = 0. In this case, the efficiency of the parallel algorithm is
Thus, the efficiency is bounded above by 0.5. This upper bound holds even if multiple columns are mapped to a processing element. Higher efficiencies are possible using alternate mappings (Problem 12.3). Note that the basic characteristic that allows efficient parallel formulations of this algorithm is that table F can be partitioned so computing each element requires data only from neighboring processing elements. In other words, the algorithm exhibits locality of data access. |
|
|