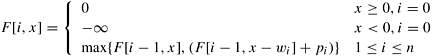|
|
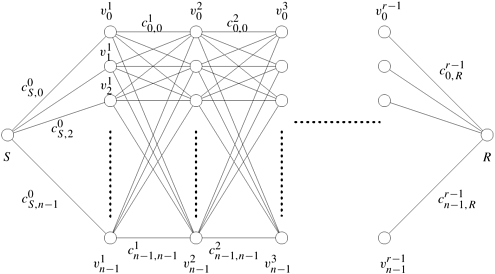
12.2 Serial Monadic DP FormulationsWe can solve many problems by using serial monadic DP formulations. This section discusses the shortest-path problem for a multistage graph and the 0/1 knapsack problem. We present parallel algorithms for both and point out the specific properties that influence these parallel formulations. 12.2.1 The Shortest-Path ProblemConsider a weighted multistage graph of r + 1 levels, as shown in Figure 12.3. Each node at level i is connected to every node at level i + 1. Levels zero and r contain only one node, and every other level contains n nodes. We refer to the node at level zero as the starting node S and the node at level r as the terminating node R. The objective of this problem is to find the shortest path from S to R. The ith node at level l in the graph is labeled
Figure 12.3. An example of a serial monadic DP formulation for finding the shortest path in a graph whose nodes can be organized into levels.
Since all nodes
Because Equation 12.2 contains only one recursive term in its right-hand side, it is a monadic formulation. Note that the solution to a subproblem requires solutions to subproblems only at the immediately preceding level. Consequently, this is a serial monadic formulation. Using this recursive formulation of the shortest-path problem, the cost of reaching the goal node R from any node at level l (0 < l < r - 1) is
Now consider the operation of multiplying a matrix with a vector. In the matrix-vector product, if the addition operation is replaced by minimization and the multiplication operation is replaced by addition, the preceding set of equations is equivalent to
where Cl and Cl+1 are n x 1 vectors representing the cost of reaching the goal node from each node at levels l and l + 1, and Ml,l+1 is an n x n matrix in which entry (i, j) stores the cost of the edge connecting node i at level l to node j at level l + 1. This matrix is
The shortest-path problem has thus been reformulated as a sequence of matrix-vector multiplications. On a sequential computer, the DP formulation starts by computing Cr -1 from Equation 12.3, and then computes Cr -k-1 for k = 1, 2, ..., r -2 using Equation 12.4. Finally, C0 is computed using Equation 12.2. Since there are n nodes at each level, the cost of computing each vector Cl is Q(n2). The parallel algorithm for this problem can be derived using the parallel algorithms for the matrix-vector product discussed in Section 8.1. For example, Q(n) processing elements can compute each vector Cl in time Q(n) and solve the entire problem in time Q(rn). Recall that r is the number of levels in the graph. Many serial monadic DP formulations with dependency graphs identical to the one considered here can be parallelized using a similar parallel algorithm. For certain dependency graphs, however, this formulation is unsuitable. Consider a graph in which each node at a level can be reached from only a small fraction of nodes at the previous level. Then matrix Ml,l+1 contains many elements with value 12.2.2 The 0/1 Knapsack ProblemA one-dimensional 0/1 knapsack problem is defined as follows. We are given a knapsack of capacity c and a set of n objects numbered 1, 2, ..., n. Each object i has weight wi and profit pi. Object profits and weights are integers. Let v = [v1, v2, ..., vn] be a solution vector in which vi = 0 if object i is not in the knapsack, and vi = 1 if it is in the knapsack. The goal is to find a subset of objects to put into the knapsack so that
(that is, the objects fit into the knapsack) and
is maximized (that is, the profit is maximized). A straightforward method to solve this problem is to consider all 2n possible subsets of the n objects and choose the one that fits into the knapsack and maximizes the profit. Here we provide a DP formulation that is faster than the simple method when c = O (2n /n). Let F [i, x] be the maximum profit for a knapsack of capacity x using only objects {1, 2, ..., i}. Then F [n, c] is the solution to the problem. The DP formulation for this problem is as follows:
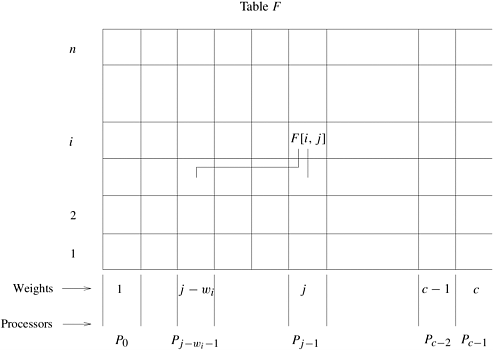
This recursive equation yields a knapsack of maximum profit. When the current capacity of the knapsack is x, the decision to include object i can lead to one of two situations: (i) the object is not included, knapsack capacity remains x , and profit is unchanged; (ii) the object is included, knapsack capacity becomes x - wi, and profit increases by pi. The DP algorithm decides whether or not to include an object based on which choice leads to maximum profit. The sequential algorithm for this DP formulation maintains a table F of size n x c. The table is constructed in row-major order. The algorithm first determines the maximum profit by using only the first object with knapsacks of different capacities. This corresponds to filling the first row of the table. Filling entries in subsequent rows requires two entries from the previous row: one from the same column and one from the column offset by the weight of the object. Thus, the computation of an arbitrary entry F [i, j] requires F [i - 1, j] and F [i - 1, j - wi]. This is illustrated in Figure 12.4. Computing each entry takes constant time; the sequential run time of this algorithm is Q(nc). Figure 12.4. Computing entries of table F for the 0/1 knapsack problem. The computation of entry F[i, j] requires communication with processing elements containing entries F[i - 1, j] and F[i - 1, j - wi].
This formulation is a serial monadic formulation. The subproblems F [i, x] are organized into n levels for i = 1, 2, ..., n. Computation of problems in level i depends only on the subproblems at level i - 1. Hence the formulation is serial. The formulation is monadic because each of the two alternate solutions of F [i, x] depends on only one subproblem. Furthermore, dependencies between levels are sparse because a problem at one level depends only on two subproblems from previous level. Consider a parallel formulation of this algorithm on a CREW PRAM with c processing elements labeled P0 to Pc-1. Processing element Pr -1 computes the rth column of matrix F. When computing F [j, r] during iteration j, processing element Pr -1 requires the values F [j - 1, r] and F [j - 1, r - wj]. Processing element Pr -1 can read any element of matrix F in constant time, so computing F [j, r] also requires constant time. Therefore, each iteration takes constant time. Since there are n iterations, the parallel run time is Q(n). The formulation uses c processing elements, hence its processor-time product is Q(nc). Therefore, the algorithm is cost-optimal. Let us now consider its formulation on a distributed memory machine with c-processing elements. Table F is distributed among the processing elements so that each processing element is responsible for one column. This is illustrated in Figure 12.4. Each processing element locally stores the weights and profits of all objects. In the jth iteration, for computing F [j, r] at processing element Pr -1, F [j - 1, r] is available locally but F [j - 1, r - wj] must be fetched from another processing element. This corresponds to the circular wj -shift operation described in Section 4.6. The time taken by this circular shift operation on p processing elements is bounded by (ts + twm) log p for a message of size m on a network with adequate bandwidth. Since the size of the message is one word and we have p = c, this time is given by (ts + tw) log c. If the sum and maximization operations take time tc, then each iteration takes time tc + (ts + tw) log c. Since there are n such iterations, the total time is given by O (n log c). The processor-time product for this formulation is O (nc log c); therefore, the algorithm is not cost-optimal. Let us see what happens to this formulation as we increase the number of elements per processor. Using p-processing elements, each processing element computes c/p elements of the table in each iteration. In the jth iteration, processing element P0 computes the values of elements F [j, 1], ..., F [j, c/p], processing element P1 computes values of elements F [j, c/p + 1], ..., F [j, 2c/p], and so on. Computing the value of F [j, k], for any k, requires values F [j - 1, k] and F [j - 1, k - wj]. Required values of the F table can be fetched from remote processing elements by performing a circular shift. Depending on the values of wj and p, the required nonlocal values may be available from one or two processing elements. Note that the total number of words communicated via these messages is c/p irrespective of whether they come from one or two processing elements. The time for this operation is at most (2ts + twc/p) assuming that c/p is large and the network has enough bandwidth (Section 4.6). Since each processing element computes c/p such elements, the total time for each iteration is tcc/p + 2ts + twc/p. Therefore, the parallel run time of the algorithm for n iterations is n(tcc/p + 2ts + twc/p). In asymptotic terms, this algorithm's parallel run time is O (nc/p). Its processor-time product is O (nc), which is cost-optimal. There is an upper bound on the efficiency of this formulation because the amount of data that needs to be communicated is of the same order as the amount of computation. This upper bound is determined by the values of tw and tc (Problem 12.1). |
|
|

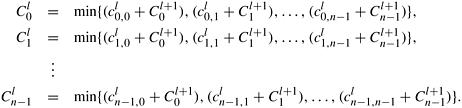
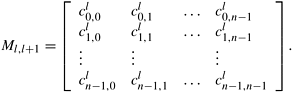
 . In this case, matrix
. In this case, matrix