3.1 In Example 3.2, each union and intersection operation can be performed in time proportional to the sum of the number of records in the two input tables. Based on this, construct the weighted task-dependency graphs corresponding to Figures 3.2 and 3.3, where the weight of each node is equivalent to the amount of work required by the corresponding task. What is the average degree of concurrency of each graph?
3.2 For the task graphs given in Figure 3.42, determine the following:
Maximum degree of concurrency.
Critical path length.
Maximum achievable speedup over one process assuming that an arbitrarily large number of processes is available.
The minimum number of processes needed to obtain the maximum possible speedup.
The maximum achievable speedup if the number of processes is limited to (a) 2, (b) 4, and (c) 8.

3.3 What are the average degrees of concurrency and critical-path lengths of task-dependency graphs corresponding to the decompositions for matrix multiplication shown in Figures 3.10 and 3.11?
3.4 Let d be the maximum degree of concurrency in a task-dependency graph with t tasks and a critical-path length l. Prove that 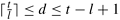 .
.
3.5 Consider LU factorization of a dense matrix shown in Algorithm 3.3. Figure 3.27 shows the decomposition of LU factorization into 14 tasks based on a two-dimensional partitioning of the matrix A into nine blocks Ai,j, 1  i, j 3. The blocks of A are modified into corresponding blocks of L and U as a result of factorization. The diagonal blocks of L are lower triangular submatrices with unit diagonals and the diagonal blocks of U are upper triangular submatrices. Task 1 factors the submatrix A1,1 using Algorithm 3.3. Tasks 2 and 3 implement the block versions of the loop on Lines 4-6 of Algorithm 3.3. Tasks 4 and 5 are the upper-triangular counterparts of tasks 2 and 3. The element version of LU factorization in Algorithm 3.3 does not show these steps because the diagonal entries of L are 1; however, a block version must compute a block-row of U as a product of the inverse of the corresponding diagonal block of L with the block-row of A. Tasks 6-9 implement the block version of the loops on Lines 7-11 of Algorithm 3.3. Thus, Tasks 1-9 correspond to the block version of the first iteration of the outermost loop of Algorithm 3.3. The remainder of the tasks complete the factorization of A. Draw a task-dependency graph corresponding to the decomposition shown in Figure 3.27.
i, j 3. The blocks of A are modified into corresponding blocks of L and U as a result of factorization. The diagonal blocks of L are lower triangular submatrices with unit diagonals and the diagonal blocks of U are upper triangular submatrices. Task 1 factors the submatrix A1,1 using Algorithm 3.3. Tasks 2 and 3 implement the block versions of the loop on Lines 4-6 of Algorithm 3.3. Tasks 4 and 5 are the upper-triangular counterparts of tasks 2 and 3. The element version of LU factorization in Algorithm 3.3 does not show these steps because the diagonal entries of L are 1; however, a block version must compute a block-row of U as a product of the inverse of the corresponding diagonal block of L with the block-row of A. Tasks 6-9 implement the block version of the loops on Lines 7-11 of Algorithm 3.3. Thus, Tasks 1-9 correspond to the block version of the first iteration of the outermost loop of Algorithm 3.3. The remainder of the tasks complete the factorization of A. Draw a task-dependency graph corresponding to the decomposition shown in Figure 3.27.
3.6 Enumerate the critical paths in the decomposition of LU factorization shown in Figure 3.27.
3.7 Show an efficient mapping of the task-dependency graph of the decomposition shown in Figure 3.27 onto three processes. Prove informally that your mapping is the best possible mapping for three processes.
3.8 Describe and draw an efficient mapping of the task-dependency graph of the decomposition shown in Figure 3.27 onto four processes and prove that your mapping is the best possible mapping for four processes.
3.9 Assuming that each task takes a unit amount of time,
which of the two mappings - the one onto three processes or the one onto four processes - solves the problem faster?
3.10 Prove that block steps 1 through 14 in Figure 3.27 with block size b (i.e., each Ai,j, Li,j, and Ui,j is a b x b submatrix) are mathematically equivalent to running the algorithm of Algorithm 3.3 on an n x n matrix A, where n = 3b.
Hint: Using induction on b is one possible approach.
3.11 Figure 3.27 shows the decomposition into 14 tasks of LU factorization of a matrix split into blocks using a 3 x 3 two-dimensional partitioning. If an m x m partitioning is used, derive an expression for the number of tasks t(m) as a function of m in a decomposition along similar lines.
Hint: Show that t(m) = t(m - 1) + m2.
3.12 In the context of Problem 3.11, derive an expression for the maximum degree of concurrency d(m) as a function of m.
3.13 In the context of Problem 3.11, derive an expression for the critical-path length l(m) as a function of m.
3.14 Show efficient mappings for the decompositions for the database query problem shown in Figures 3.2 and 3.3. What is the maximum number of processes that you would use in each case?
3.15 In the algorithm shown in Algorithm 3.4, assume a decomposition such that each execution of Line 7 is a task. Draw a task-dependency graph and a task-interaction graph.
Algorithm 3.4 A sample serial program to be parallelized.
1. procedure FFT_like_pattern(A, n)
2. begin
3. m := log2 n;
4. for j := 0 to m - 1 do
5. k := 2j;
6. for i := 0 to n - 1 do
7. A[i] := A[i] + A[i XOR 2j];
8. endfor
9. end FFT_like_pattern
3.16 In Algorithm 3.4, if n = 16, devise a good mapping for 16 processes.
3.17 In Algorithm 3.4, if n = 16, devise a good mapping for 8 processes.
3.18 Repeat Problems 3.15, 3.16, and 3.17 if the statement of Line 3 in Algorithm 3.4 is changed to m = (log2 n) - 1.
3.19 Consider a simplified version of bucket-sort. You are given an array A of n random integers in the range [1...r] as input. The output data consist of r buckets, such that at the end of the algorithm, Bucket i contains indices of all the elements in A that are equal to i.
Describe a decomposition based on partitioning the input data (i.e., the array A) and an appropriate mapping onto p processes. Describe briefly how the resulting parallel algorithm would work.
Describe a decomposition based on partitioning the output data (i.e., the set of r buckets) and an appropriate mapping onto p processes. Describe briefly how the resulting parallel algorithm would work.
3.20 In the context of Problem 3.19, which of the two decompositions leads to a better parallel algorithm? Should the relative values of n and r have a bearing on the selection of one of the two decomposition schemes?
3.21 Consider seven tasks with running times of 1, 2, 3, 4, 5, 5, and 10 units, respectively. Assuming that it does not take any time to assign work to a process, compute the best- and worst-case speedup for a centralized scheme for dynamic mapping with two processes.
3.22 Suppose there are M tasks that are being mapped using a centralized dynamic load balancing scheme and we have the following information about these tasks:
Compute the best- and worst-case speedups for self-scheduling and chunk-scheduling assuming that tasks are available in batches of l (l < M). What are the actual values of the best- and worst-case speedups for the two scheduling methods when p = 10,  = 0.2, m = 20, M = 100, and l = 2?
= 0.2, m = 20, M = 100, and l = 2?
 1, Tasks 1, 10, and 14 require about 2/3
1, Tasks 1, 10, and 14 require about 2/3