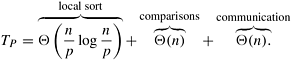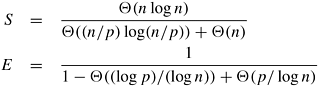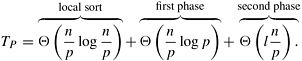|
|
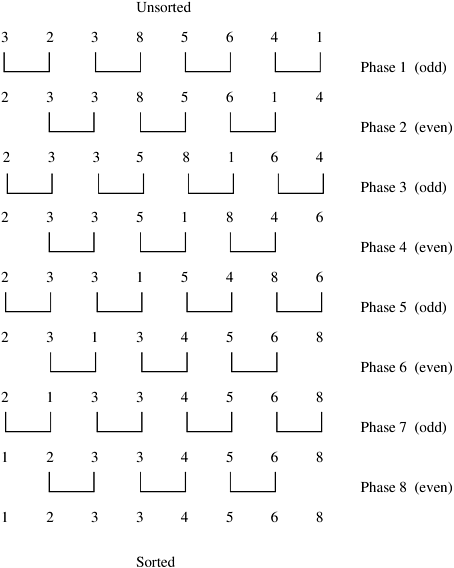
9.3 Bubble Sort and its VariantsThe previous section presented a sorting network that could sort n elements in a time of Q(log2 n). We now turn our attention to more traditional sorting algorithms. Since serial algorithms with Q(n log n) time complexity exist, we should be able to use Q(n) processes to sort n elements in time Q(log n). As we will see, this is difficult to achieve. We can, however, easily parallelize many sequential sorting algorithms that have Q(n2) complexity. The algorithms we present are based on bubble sort. The sequential bubble sort algorithm compares and exchanges adjacent elements in the sequence to be sorted. Given a sequence <a1, a2, ..., an >, the algorithm first performs n - 1 compare-exchange operations in the following order: (a1, a2), (a2, a3), ..., (an-1, an). This step moves the largest element to the end of the sequence. The last element in the transformed sequence is then ignored, and the sequence of compare-exchanges is applied to the resulting sequence An iteration of the inner loop of bubble sort takes time Q(n), and we perform a total of Q(n) iterations; thus, the complexity of bubble sort is Q(n2). Bubble sort is difficult to parallelize. To see this, consider how compare-exchange operations are performed during each phase of the algorithm (lines 4 and 5 of Algorithm 9.2). Bubble sort compares all adjacent pairs in order; hence, it is inherently sequential. In the following two sections, we present two variants of bubble sort that are well suited to parallelization. Algorithm 9.2 Sequential bubble sort algorithm.1. procedure BUBBLE_SORT(n) 2. begin 3. for i := n - 1 downto 1 do 4. for j := 1 to i do 5. compare-exchange(aj, aj + 1); 6. end BUBBLE_SORT 9.3.1 Odd-Even TranspositionThe odd-even transposition algorithm sorts n elements in n phases (n is even), each of which requires n/2 compare-exchange operations. This algorithm alternates between two phases, called the odd and even phases. Let <a1, a2, ..., an> be the sequence to be sorted. During the odd phase, elements with odd indices are compared with their right neighbors, and if they are out of sequence they are exchanged; thus, the pairs (a1, a2), (a3, a4), ..., (an-1, an) are compare-exchanged (assuming n is even). Similarly, during the even phase, elements with even indices are compared with their right neighbors, and if they are out of sequence they are exchanged; thus, the pairs (a2, a3), (a4, a5), ..., (an-2, an-1) are compare-exchanged. After n phases of odd-even exchanges, the sequence is sorted. Each phase of the algorithm (either odd or even) requires Q(n) comparisons, and there are a total of n phases; thus, the sequential complexity is Q(n2). The odd-even transposition sort is shown in Algorithm 9.3 and is illustrated in Figure 9.13. Figure 9.13. Sorting n = 8 elements, using the odd-even transposition sort algorithm. During each phase, n = 8 elements are compared.
Algorithm 9.3 Sequential odd-even transposition sort algorithm.1. procedure ODD-EVEN(n) 2. begin 3. for i := 1 to n do 4. begin 5. if i is odd then 6. for j := 0 to n/2 - 1 do 7. compare-exchange(a2j + 1, a2j + 2); 8. if i is even then 9. for j := 1 to n/2 - 1 do 10. compare-exchange(a2j, a2j + 1); 11. end for 12. end ODD-EVEN Parallel FormulationIt is easy to parallelize odd-even transposition sort. During each phase of the algorithm, compare-exchange operations on pairs of elements are performed simultaneously. Consider the one-element-per-process case. Let n be the number of processes (also the number of elements to be sorted). Assume that the processes are arranged in a one-dimensional array. Element ai initially resides on process Pi for i = 1, 2, ..., n. During the odd phase, each process that has an odd label compare-exchanges its element with the element residing on its right neighbor. Similarly, during the even phase, each process with an even label compare-exchanges its element with the element of its right neighbor. This parallel formulation is presented in Algorithm 9.4. Algorithm 9.4 The parallel formulation of odd-even transposition sort on an n-process ring.1. procedure ODD-EVEN_PAR (n) 2. begin 3. id := process's label 4. for i := 1 to n do 5. begin 6. if i is odd then 7. if id is odd then 8. compare-exchange_min(id + 1); 9. else 10. compare-exchange_max(id - 1); 11. if i is even then 12. if id is even then 13. compare-exchange_min(id + 1); 14. else 15. compare-exchange_max(id - 1); 16. end for 17. end ODD-EVEN_PAR During each phase of the algorithm, the odd or even processes perform a compare- exchange step with their right neighbors. As we know from Section 9.1, this requires time Q(1). A total of n such phases are performed; thus, the parallel run time of this formulation is Q(n). Since the sequential complexity of the best sorting algorithm for n elements is Q(n log n), this formulation of odd-even transposition sort is not cost-optimal, because its process-time product is Q(n2). To obtain a cost-optimal parallel formulation, we use fewer processes. Let p be the number of processes, where p < n. Initially, each process is assigned a block of n/p elements, which it sorts internally (using merge sort or quicksort) in Q((n/p) log(n/p)) time. After this, the processes execute p phases (p/2 odd and p/2 even), performing compare-split operations. At the end of these phases, the list is sorted (Problem 9.10). During each phase, Q(n/p) comparisons are performed to merge two blocks, and time Q(n/p) is spent communicating. Thus, the parallel run time of the formulation is
Since the sequential complexity of sorting is Q(n log n), the speedup and efficiency of this formulation are as follows:
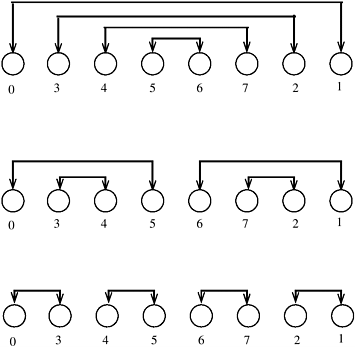
From Equation 9.6, odd-even transposition sort is cost-optimal when p = O(log n). The isoefficiency function of this parallel formulation is Q(p 2p), which is exponential. Thus, it is poorly scalable and is suited to only a small number of processes. 9.3.2 ShellsortThe main limitation of odd-even transposition sort is that it moves elements only one position at a time. If a sequence has just a few elements out of order, and if they are Q(n) distance from their proper positions, then the sequential algorithm still requires time Q(n2) to sort the sequence. To make a substantial improvement over odd-even transposition sort, we need an algorithm that moves elements long distances. Shellsort is one such serial sorting algorithm. Let n be the number of elements to be sorted and p be the number of processes. To simplify the presentation we will assume that the number of processes is a power of two, that is, p = 2d, but the algorithm can be easily extended to work for an arbitrary number of processes as well. Each process is assigned a block of n/p elements. The processes are considered to be arranged in a logical one-dimensional array, and the ordering of the processes in that array defines the global ordering of the sorted sequence. The algorithm consists of two phases. During the first phase, processes that are far away from each other in the array compare-split their elements. Elements thus move long distances to get close to their final destinations in a few steps. During the second phase, the algorithm switches to an odd-even transposition sort similar to the one described in the previous section. The only difference is that the odd and even phases are performed only as long as the blocks on the processes are changing. Because the first phase of the algorithm moves elements close to their final destinations, the number of odd and even phases performed by the second phase may be substantially smaller than p. Initially, each process sorts its block of n/p elements internally in Q(n/p log(n/p)) time. Then, each process is paired with its corresponding process in the reverse order of the array. That is, process Pi, where i < p/2, is paired with process Pp-i -1. Each pair of processes performs a compare-split operation. Next, the processes are partitioned into two groups; one group has the first p/2 processes and the other group has the last p/2 processes. Now, each group is treated as a separate set of p/2 processes and the above scheme of process-pairing is applied to determine which processes will perform the compare-split operation. This process continues for d steps, until each group contains only a single process. The compare-split operations of the first phase are illustrated in Figure 9.14 for d = 3. Note that it is not a direct parallel formulation of the sequential shellsort, but it relies on similar ideas. Figure 9.14. An example of the first phase of parallel shellsort on an eight-process array.
In the first phase of the algorithm, each process performs d = log p compare-split operations. In each compare-split operation a total of p/2 pairs of processes need to exchange their locally stored n/p elements. The communication time required by these compare-split operations depend on the bisection bandwidth of the network. In the case in which the bisection bandwidth is Q(p), the amount of time required by each operation is Q(n/p). Thus, the complexity of this phase is Q((n log p)/p). In the second phase, l odd and even phases are performed, each requiring time Q(n/p). Thus, the parallel run time of the algorithm is
The performance of shellsort depends on the value of l. If l is small, then the algorithm performs significantly better than odd-even transposition sort; if l is Q(p), then both algorithms perform similarly. Problem 9.13 investigates the worst-case value of l. |
|
|