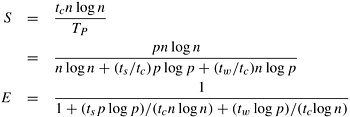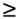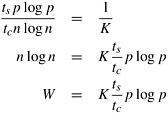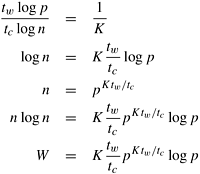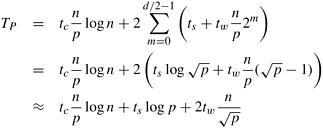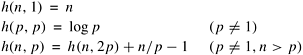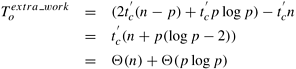|
|
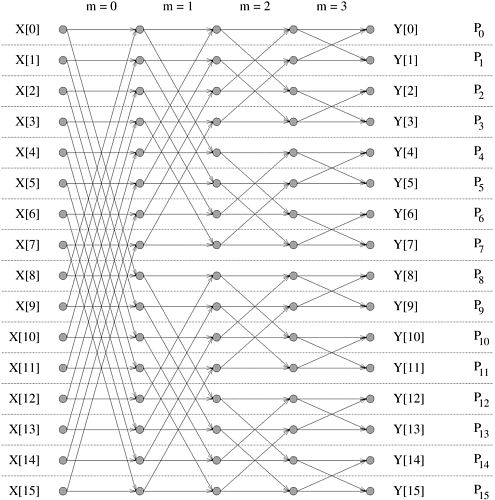
13.2 The Binary-Exchange AlgorithmThis section discusses the binary-exchange algorithm for performing FFT on a parallel computer. First, a decomposition is induced by partitioning the input or the output vector. Therefore, each task starts with one element of the input vector and computes the corresponding element of the output. If each task is assigned the same label as the index of its input or output element, then in each of the log n iterations of the algorithm, exchange of data takes place between pairs of tasks with labels differing in one bit position. 13.2.1 A Full Bandwidth NetworkIn this subsection, we describe the implementation of the binary-exchange algorithm on a parallel computer on which a bisection width (Section 2.4.4) of Q(p) is available to p parallel processes. Since the pattern of interaction among the tasks of parallel FFT matches that of a hypercube network, we describe the algorithm assuming such an interconnection network. However, the performance and scalability analysis would be valid for any parallel computer with an overall simultaneous data-transfer capacity of O (p). One Task Per ProcessWe first consider a simple mapping in which one task is assigned to each process. Figure 13.3 illustrates the interaction pattern induced by this mapping of the binary-exchange algorithm for n = 16. As the figure shows, process i (0 Figure 13.3. A 16-point unordered FFT on 16 processes. Pi denotes the process labeled i.
To perform the updates, process Pi requires an element of S from a process whose label differs from i at only one bit. Recall that in a hypercube, a node is connected to all those nodes whose labels differ from its own at only one bit position. Thus, the parallel FFT computation maps naturally onto a hypercube with a one-to-one mapping of processes to nodes. In the first iteration of the outer loop, the labels of each pair of communicating processes differ only at their most significant bits. For instance, processes P0 to P7 communicate with P8 to P15, respectively. Similarly, in the second iteration, the labels of processes communicating with each other differ at the second most significant bit, and so on. In each of the log n iterations of this algorithm, every process performs one complex multiplication and addition, and exchanges one complex number with another process. Thus, there is a constant amount of work per iteration. Hence, it takes time Q(log n) to execute the algorithm in parallel by using a hypercube with n nodes. This hypercube formulation of FFT is cost-optimal because its process-time product is Q(n log n), the same as the complexity of a serial n-point FFT. Multiple Tasks Per ProcessWe now consider a mapping in which the n tasks of an n-point FFT are mapped onto p processes, where n > p. For the sake of simplicity, let us assume that both n and p are powers of two, i.e., n = 2r and p = 2d. As Figure 13.4 shows, we partition the sequences into blocks of n/p contiguous elements and assign one block to each process. Figure 13.4. A 16-point FFT on four processes. Pi denotes the process labeled i. In general, the number of processes is p = 2d and the length of the input sequence is n = 2r.
An interesting property of the mapping shown in Figure 13.4 is that, if (b0b1 ··· br -1) is the binary representation of any i, such that 0 Figure 13.4 shows that elements with indices differing at their d (= 2) most significant bits are mapped onto different processes. However, all elements with indices having the same d most significant bits are mapped onto the same process. Recall from the previous section that an n-point FFT requires r = log n iterations of the outer loop. In the mth iteration of the loop, elements with indices differing in the mth most significant bit are combined. As a result, elements combined during the first d iterations belong to different processes, and pairs of elements combined during the last (r - d) iterations belong to the same processes. Hence, this parallel FFT algorithm requires interprocess interaction only during the first d = log p of the log n iterations. There is no interaction during the last r - d iterations. Furthermore, in the i th of the first d iterations, all the elements that a process requires come from exactly one other process - the one whose label is different at the i th most significant bit. Each interaction operation exchanges n/p words of data. Therefore, the time spent in communication in the entire algorithm is ts log p + tw(n/p) log p. A process updates n/p elements of R during each of the log n iterations. If a complex multiplication and addition pair takes time tc, then the parallel run time of the binary-exchange algorithm for n-point FFT on a p-node hypercube network is
The process-time product is tcn log n + ts p log p + twn log p. For the parallel system to be cost-optimal, this product should be O (n log n) - the sequential time complexity of the FFT algorithm. This is true for p The expressions for speedup and efficiency are given by the following equations:
Scalability AnalysisFrom Section 13.1, we know that the problem size W for an n-point FFT is
Since an n-point FFT can utilize a maximum of n processes with the mapping of Figure 13.3, n
In order to maintain a fixed efficiency E , the expression (ts p log p)/(tcn log n) + (twlog p)/(tc log n) should be equal to a constant 1/K, where K = E/(1 - E). We have defined the constant K in this manner to keep the terminology consistent with Chapter 5. As proposed in Section 5.4.2, we use an approximation to obtain closed expressions for the isoefficiency function. We first determine the rate of growth of the problem size with respect to p that would keep the terms due to ts constant. To do this, we assume tw = 0. Now the condition for maintaining constant efficiency E is as follows:
Equation 13.7 gives the isoefficiency function due to the overhead resulting from interaction latency or the message startup time. Similarly, we derive the isoefficiency function due to the overhead resulting from tw. We assume that ts = 0; hence, a fixed efficiency E requires that the following relation be maintained:
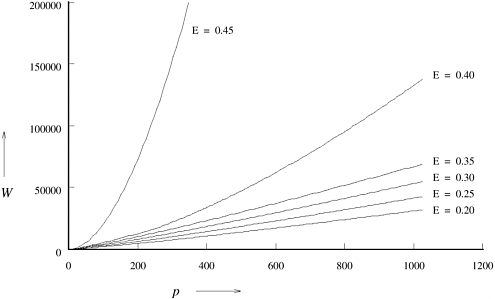
If the term Ktw/tc is less than one, then the rate of growth of the problem size required by Equation 13.8 is less than Q(p log p). In this case, Equation 13.7 determines the overall isoefficiency function of this parallel system. However, if Ktw/tc exceeds one, then Equation 13.8 determines the overall isoefficiency function, which is now greater than the isoefficiency function of Q(p log p) given by Equation 13.7. For this algorithm, the asymptotic isoefficiency function depends on the relative values of K, tw, and tc. Here, K is an increasing function of the efficiency E to be maintained, tw depends on the communication bandwidth of the parallel computer, and tc depends on the speed of the computation speed of the processors. The FFT algorithm is unique in that the order of the isoefficiency function depends on the desired efficiency and hardware-dependent parameters. In fact, the efficiency corresponding to Ktw/tc = 1(i.e.,1/(1 - E) = tc/tw, or E = tc/(tc + tw)) acts as a kind of threshold. For a fixed tc and tw, efficiencies up to the threshold can be obtained easily. For E Example 13.1 Threshold effect in the binary-exchange algorithm Consider a hypothetical hypercube for which the relative values of the hardware parameters are given by tc = 2, tw = 4, and ts = 25. With these values, the threshold efficiency tc/(tc + tw) is 0.33. Now we study the isoefficiency functions of the binary-exchange algorithm on a hypercube for maintaining efficiencies below and above the threshold. The isoefficiency function of this algorithm due to concurrency is p log p. From Equations 13.7 and 13.8, the isoefficiency functions due to the ts and tw terms in the overhead function are K (ts/tc) p log p and
Figure 13.5 shows the isoefficiency curves given by this function for E = 0.20, 0.25, 0.30, 0.35, 0.40, and 0.45. Notice that the various isoefficiency curves are regularly spaced for efficiencies up to the threshold. However, the problem sizes required to maintain efficiencies above the threshold are much larger. The asymptotic isoefficiency functions for E = 0.20, 0.25, and 0.30 are Q(p log p). The isoefficiency function for E = 0.40 is Q(p1.33 log p), and that for E = 0.45 is Q(p1.64 log p). Figure 13.5. Isoefficiency functions of the binary-exchange algorithm on a hypercube with tc = 2, tw = 4, and ts = 25 for various values of E.
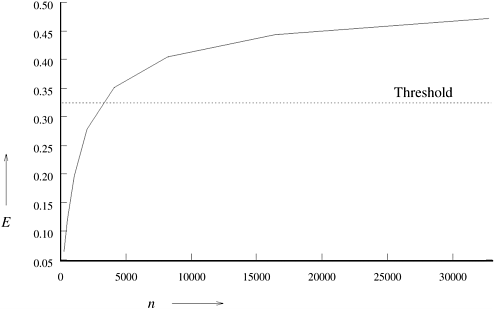
Figure 13.6 shows the efficiency curve of n-point FFTs on a 256-node hypercube with the same hardware parameters. The efficiency E is computed by using Equation 13.5 for various values of n, when p is equal to 256. The figure shows that the efficiency initially increases rapidly with the problem size, but the efficiency curve flattens out beyond the threshold. Figure 13.6. The efficiency of the binary-exchange algorithm as a function of n on a 256-node hypercube with tc = 2, tw = 4, and ts = 25.
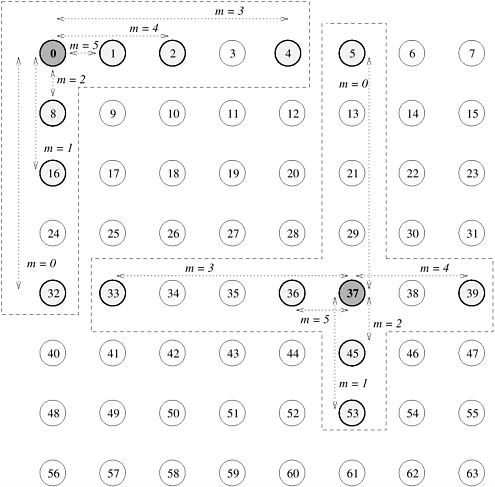
Example 13.1 shows that there is a limit on the efficiency that can be obtained for reasonable problem sizes, and that the limit is determined by the ratio between the CPU speed and the communication bandwidth of the parallel computer being used. This limit can be raised by increasing the bandwidth of the communication channels. However, making the CPUs faster without increasing the communication bandwidth lowers the limit. Hence, the binary-exchange algorithm performs poorly on a parallel computer whose communication and computation speeds are not balanced. If the hardware is balanced with respect to its communication and computation speeds, then the binary-exchange algorithm is fairly scalable, and reasonable efficiencies can be maintained while increasing the problem size at the rate of Q(p log p). 13.2.2 Limited Bandwidth NetworkNow we consider the implementation of the binary-exchange algorithm on a parallel computer whose cross-section bandwidth is less than Q(p). We choose a mesh interconnection network to illustrate the algorithm and its performance characteristics. Assume that n tasks are mapped onto p processes running on a mesh with As in case of the hypercube, communication takes place only during the first log p iterations between processes whose labels differ at one bit. However, unlike the hypercube, the communicating processes are not directly linked in a mesh. Consequently, messages travel over multiple links and there is overlap among messages sharing the same links. Figure 13.7 shows the messages sent and received by processes 0 and 37 during an FFT computation on a 64-node mesh. As the figure shows, process 0 communicates with processes 1, 2, 4, 8, 16, and 32. Note that all these processes lie in the same row or column of the mesh as that of process 0. Processes 1, 2, and 4 lie in the same row as process 0 at distances of 1, 2, and 4 links, respectively. Processes 8, 16, and 32 lie in the same column, again at distances of 1, 2, and 4 links. More precisely, in log Figure 13.7. Data communication during an FFT computation on a logical square mesh of 64 processes. The figure shows all the processes with which the processes labeled 0 and 37 exchange data.
The distance between the communicating processes in a row or a column grows from one link to
The speedup and efficiency are given by the following equations:
The process-time product of this parallel system is The communication overhead of the binary-exchange algorithm on a mesh cannot be reduced by using a different mapping of the sequences onto the processes. In any mapping, there is at least one iteration in which pairs of processes that communicate with each other are at least 13.2.3 Extra Computations in Parallel FFTSo far, we have described a parallel formulation of the FFT algorithm on a hypercube and a mesh, and have discussed its performance and scalability in the presence of communication overhead on both architectures. In this section, we discuss another source of overhead that can be present in a parallel FFT implementation. Recall from Algorithm 13.2 that the computation step of line 12 multiplies a power of w (a twiddle factor) with an element of S. For an n-point FFT, line 12 executes n log n times in the sequential algorithm. However, only n distinct powers of w (that is, w0, w1, w2, ..., wn-1) are used in the entire algorithm. So some of the twiddle factors are used repeatedly. In a serial implementation, it is useful to precompute and store all n twiddle factors before starting the main algorithm. That way, the computation of twiddle factors requires only Q(n) complex operations rather than the Q(n log n) operations needed to compute all twiddle factors in each iteration of line 12. In a parallel implementation, the total work required to compute the twiddle factors cannot be reduced to Q(n). The reason is that, even if a certain twiddle factor is used more than once, it might be used on different processes at different times. If FFTs of the same size are computed on the same number of processes, every process needs the same set of twiddle factors for each computation. In this case, the twiddle factors can be precomputed and stored, and the cost of their computation can be amortized over the execution of all instances of FFTs of the same size. However, if we consider only one instance of FFT, then twiddle factor computation gives rise to additional overhead in a parallel implementation, because it performs more overall operations than the sequential implementation. As an example, consider the various powers of w used in the three iterations of an 8-point FFT. In the mth iteration of the loop starting on line 5 of the algorithm, wl is computed for all i (0 If eight processes are used, then each process computes and uses one column of Table 13.1. Process 0 computes just one twiddle factor for all its iterations, but some processes (in this case, all other processes 2-7) compute a new twiddle factor in each of the three iterations. If p = n/2 = 4, then each process computes two consecutive columns of the table. In this case, the last process computes the twiddle factors in the last two columns of the table. Hence, the last process computes a total of four different powers - one each for m = 0 (100) and m = 1 (110), and two for m = 2 (011 and 111). Although different processes may compute a different number of twiddle factors, the total overhead due to the extra work is proportional to p times the maximum number of twiddle factors that any single process computes. Let h(n, p) be the maximum number of twiddle factors that any of the p processes computes during an n-point FFT. Table 13.2 shows the values of h(8, p) for p = 1, 2, 4, and 8. The table also shows the maximum number of new twiddle factors that any single process computes in each iteration.
The function h is defined by the following recurrence relation (Problem 13.5):
The solution to this recurrence relation for p > 1 and n
Thus, if it takes time
This overhead is independent of the architecture of the parallel computer used for the FFT computation. The isoefficiency function due to | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|