9.1 Consider the following technique for performing the compare-split operation. Let x1, x2, ..., xk be the elements stored at process Pi in increasing order, and let y1, y2, ..., yk be the elements stored at process Pj in decreasing order. Process Pi sends x1 to Pj. Process Pj compares x1 with y1 and then sends the larger element back to process Pi and keeps the smaller element for itself. The same procedure is repeated for pairs (x2, y2), (x3, y3), ..., (xk , yk ). If for any pair (xl , yl ) for 1  l k, xl
l k, xl 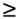 yl, then no more exchanges are needed. Finally, each process sorts its elements. Show that this method correctly performs a compare-split operation. Analyze its run time, and compare the relative merits of this method to those of the method presented in the text. Is this method better suited for MIMD or SIMD parallel computers?
yl, then no more exchanges are needed. Finally, each process sorts its elements. Show that this method correctly performs a compare-split operation. Analyze its run time, and compare the relative merits of this method to those of the method presented in the text. Is this method better suited for MIMD or SIMD parallel computers?
9.2 Show that the relation, as defined in Section 9.1 for blocks of elements, is a partial ordering relation.
Hint: A relation is a partial ordering if it is reflexive, antisymmetric, and transitive.
9.3 Consider the sequence s = {a0, a1, ..., an-1},where n is a power of 2. In the following cases, prove that the sequences s1 and s2 obtained by performing the bitonic split operation described in Section 9.2.1, on the sequence s, satisfy the properties that (1) s1 and s2 are bitonic sequences, and (2) the elements of s1 are smaller than the elements of s2:
s is a bitonic sequence such that a0 a1 ··· an/2-1 and an/2 an/2+1 ··· an-1.
s is a bitonic sequence such that a0 a1 ··· ai and ai +1 ai +2 ··· an-1 for some i, 0 i n - 1.
s is a bitonic sequence that becomes increasing-decreasing after shifting its elements.
9.4 In the parallel formulations of bitonic sort, we assumed that we had n processes available to sort n items. Show how the algorithm needs to be modified when only n/2 processes are available.
9.5 Show that, in the hypercube formulation of bitonic sort, each bitonic merge of sequences of size 2k is performed on a k-dimensional hypercube and each sequence is assigned to a separate hypercube.
9.6 Show that the parallel formulation of bitonic sort shown in Algorithm 9.1 is correct. In particular, show that the algorithm correctly compare-exchanges elements and that the elements end up in the appropriate processes.
9.7 Consider the parallel formulation of bitonic sort for a mesh-connected parallel computer. Compute the exact parallel run time of the following formulations:
One that uses the row-major mapping shown in Figure 9.11(a) for a mesh with store-and-forward routing.
One that uses the row-major snakelike mapping shown in Figure 9.11(b) for a mesh with store-and-forward routing.
One that uses the row-major shuffled mapping shown in Figure 9.11(c) for a mesh with store-and-forward routing.
Also, determine how the above run times change when cut-through routing is used.
9.8 Show that the block-based bitonic sort algorithm that uses compare-split operations is correct.
9.9 Consider a ring-connected parallel computer with n processes. Show how to map the input wires of the bitonic sorting network onto the ring so that the communication cost is minimized. Analyze the performance of your mapping. Consider the case in which only p processes are available. Analyze the performance of your parallel formulation for this case. What is the largest number of processes that can be used while maintaining a cost-optimal parallel formulation? What is the isoefficiency function of your scheme?
9.10 Prove that the block-based odd-even transposition sort yields a correct algorithm.
Hint: This problem is similar to Problem 9.8.
9.11 Show how to apply the idea of the shellsort algorithm (Section 9.3.2) to a p-process mesh-connected computer. Your algorithm does not need to be an exact copy of the hypercube formulation.
9.12 Show how to parallelize the sequential shellsort algorithm for a p-process hypercube. Note that the shellsort algorithm presented in Section 9.3.2 is not an exact parallelization of the sequential algorithm.
9.13 Consider the shellsort algorithm presented in Section 9.3.2. Its performance depends on the value of l, which is the number of odd and even phases performed during the second phase of the algorithm. Describe a worst-case initial key distribution that will require l = Q(p) phases. What is the probability of this worst-case scenario?
9.14 In Section 9.4.1 we discussed a parallel formulation of quicksort for a CREW PRAM that is based on assigning each subproblem to a separate process. This formulation uses n processes to sort n elements. Based on this approach, derive a parallel formulation that uses p processes, where (p < n). Derive expressions for the parallel run time, efficiency, and isoefficiency function. What is the maximum number of processes that your parallel formulation can use and still remain cost-optimal?
9.15 Derive an algorithm that traverses the binary search tree constructed by the algorithm in Algorithm 9.6 and determines the position of each element in the sorted array. Your algorithm should use n processes and solve the problem in time Q(log n) on an arbitrary CRCW PRAM.
9.16 Consider the PRAM formulation of the quicksort algorithm (Section 9.4.2). Compute the average height of the binary tree generated by the algorithm.
9.17 Consider the following parallel quicksort algorithm that takes advantage of the topology of a p-process hypercube connected parallel computer. Let n be the number of elements to be sorted and p = 2d be the number of processes in a d-dimensional hypercube. Each process is assigned a block of n/p elements, and the labels of the processes define the global order of the sorted sequence. The algorithm starts by selecting a pivot element, which is broadcast to all processes. Each process, upon receiving the pivot, partitions its local elements into two blocks, one with elements smaller than the pivot and one with elements larger than the pivot. Then the processes connected along the dth communication link exchange appropriate blocks so that one retains elements smaller than the pivot and the other retains elements larger than the pivot. Specifically, each process with a 0 in the dth bit (the most significant bit) position of the binary representation of its process label retains the smaller elements, and each process with a 1 in the dth bit retains the larger elements. After this step, each process in the (d - 1)-dimensional hypercube whose dth label bit is 0 will have elements smaller than the pivot, and each process in the other (d - 1)-dimensional hypercube will have elements larger than the pivot. This procedure is performed recursively in each subcube, splitting the subsequences further. After d such splits - one along each dimension - the sequence is sorted with respect to the global ordering imposed on the processes. This does not mean that the elements at each process are sorted. Therefore, each process sorts its local elements by using sequential quicksort. This hypercube formulation of quicksort is shown in Algorithm 9.9. The execution of the algorithm is illustrated in Figure 9.21.
Algorithm 9.9 A parallel formulation of quicksort on a d-dimensional hypercube. B is the n/p-element subsequence assigned to each process.
1. procedure HYPERCUBE_QUICKSORT (B, n)
2. begin
3. id := process's label;
4. for i := 1 to d do
5. begin
6. x := pivot;
7. partition B into B1 and B2 such that B1 x < B2;
8. if ith bit is 0 then
9. begin
10. send B2 to the process along the i th communication link;
11. C := subsequence received along the i th communication link;
12. B := B1  C ;
13. endif
14. else
15. send B1 to the process along the ith communication link;
16. C := subsequence received along the ith communication link;
17. B := B2 C ;
18. endelse
19. endfor
20. sort B using sequential quicksort;
21. end HYPERCUBE_QUICKSORT
C ;
13. endif
14. else
15. send B1 to the process along the ith communication link;
16. C := subsequence received along the ith communication link;
17. B := B2 C ;
18. endelse
19. endfor
20. sort B using sequential quicksort;
21. end HYPERCUBE_QUICKSORT
Analyze the complexity of this hypercube-based parallel quicksort algorithm. Derive expressions for the parallel runtime, speedup, and efficiency. Perform this analysis assuming that the elements that were initially assigned at each process are distributed uniformly.
9.18 Consider the parallel formulation of quicksort for a d-dimensional hypercube described in Problem 9.17. Show that after d splits - one along each communication link - the elements are sorted according to the global order defined by the process's labels.
9.19 Consider the parallel formulation of quicksort for a d-dimensional hypercube described in Problem 9.17. Compare this algorithm against the message-passing quicksort algorithm described in Section 9.4.3. Which algorithm is more scalable? Which algorithm is more sensitive on poor selection of pivot elements?
9.20 An alternative way of selecting pivots in the parallel formulation of quicksort for a d-dimensional hypercube (Problem 9.17) is to select all the 2d - 1 pivots at once as follows:
Each process picks a sample of l elements at random.
All processes together sort the sample of l x 2d items by using the shellsort algorithm (Section 9.3.2).
Choose 2d - 1 equally distanced pivots from this list.
Broadcast pivots so that all the processes know the pivots.
How does the quality of this pivot selection scheme depend on l? Do you think l should be a function of n? Under what assumptions will this scheme select good pivots? Do you think this scheme works when the elements are not identically distributed on each process? Analyze the complexity of this scheme.
9.21 Another pivot selection scheme for parallel quicksort for hypercube (Section 9.17) is as follows. During the split along the ith dimension, 2i -1 pairs of processes exchange elements. The pivot is selected in two steps. In the first step, each of the 2i -1 pairs of processes compute the median of their combined sequences. In the second step, the median of the 2i -1 medians is computed. This median of medians becomes the pivot for the split along the ith communication link. Subsequent pivots are selected in the same way among the participating subcubes. Under what assumptions will this scheme yield good pivot selections? Is this better than the median scheme described in the text? Analyze the complexity of selecting the pivot.
Hint: If A and B are two sorted sequences, each having n elements, then we can find the median of A B in time Q(log n).
9.22 In the parallel formulation of the quicksort algorithm on shared-address-space and message-passing architectures (Section 9.4.3) each iteration is followed by a barrier synchronization. Is barrier synchronization necessary to ensure the correctness of the algorithm? If not, then how does the performance change in the absence of barrier synchronization?
9.23 Consider the message-passing formulation of the quicksort algorithm presented in Section 9.4.3. Compute the exact (that is, using ts, tw, and tc) parallel run time and efficiency of the algorithm under the assumption of perfect pivots. Compute the various components of the isoefficiency function of your formulation when
tc = 1, tw = 1, ts = 1
tc = 1, tw = 1, ts = 10
tc = 1, tw = 10, ts = 100
for cases in which the desired efficiency is 0.50, 0.75, and 0.95. Does the scalability of this formulation depend on the desired efficiency and the architectural characteristics of the machine?
9.24 Consider the following parallel formulation of quicksort for a mesh-connected message-passing parallel computer. Assume that one element is assigned to each process. The recursive partitioning step consists of selecting the pivot and then rearranging the elements in the mesh so that those smaller than the pivot are in one part of the mesh and those larger than the pivot are in the other. We assume that the processes in the mesh are numbered in row-major order. At the end of the quicksort algorithm, elements are sorted with respect to this order. Consider the partitioning step for an arbitrary subsequence illustrated in Figure 9.22(a). Let k be the length of this sequence, and let Pm, Pm+1, ..., Pm+k be the mesh processes storing it. Partitioning consists of the following four steps:
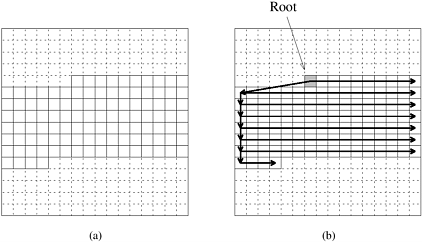
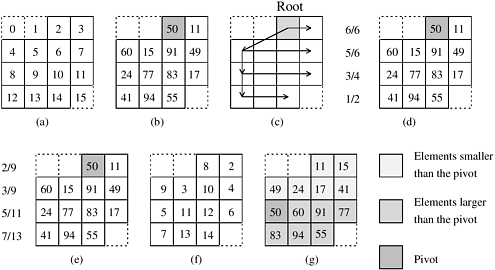
A pivot is selected at random and sent to process Pm. Process Pm broadcasts this pivot to all k processes by using an embedded tree, as shown in Figure 9.22(b). The root (Pm) transmits the pivot toward the leaves. The tree embedding is also used in the following steps.
Information is gathered at each process and passed up the tree. In particular, each process counts the number of elements smaller and larger than the pivot in both its left and right subtrees. Each process knows the pivot value and therefore can determine if its element is smaller or larger. Each process propagates two values to its parent: the number of elements smaller than the pivot and the number of elements larger than the pivot in the process's subtree. Because the tree embedded in the mesh is not complete, some nodes will not have left or right subtrees. At the end of this step, process Pm knows how many of the k elements are smaller and larger than the pivot. If s is the number of the elements smaller than the pivot, then the position of the pivot in the sorted sequence is Pm+s.
Information is propagated down the tree to enable each element to be moved to its proper position in the smaller or larger partitions. Each process in the tree receives from its parent the next empty position in the smaller and larger partitions. Depending on whether the element stored at each process is smaller or larger than the pivot, the process propagates the proper information down to its subtrees. Initially, the position for elements smaller than the pivot is Pm and the position for elements larger than the pivot is Pm+s+1.
The processes perform a permutation, and each element moves to the proper position in the smaller or larger partition.
This algorithm is illustrated in Figure 9.23.
Analyze the complexity of this mesh-based parallel quicksort algorithm. Derive expressions for the parallel runtime, speedup, and efficiency. Perform this analysis assuming that the elements that were initially assigned at each process are distributed uniformly.
9.25 Consider the quicksort formulation for a mesh described in Problem 9.24. Describe a scaled-down formulation that uses p < n processes. Analyze its parallel run time, speedup, and isoefficiency function.
9.26 Consider the enumeration sort algorithm presented in Section 9.6.1. Show how the algorithm can be implemented on each of the following:
a CREW PRAM
a EREW PRAM
a hypercube-connected parallel computer
a mesh-connected parallel computer.
Analyze the performance of your formulations. Furthermore, show how you can extend this enumeration sort to a hypercube to sort n elements using p processes.
9.27 Derive expressions for the speedup, efficiency, and isoefficiency function of the bucket sort parallel formulation presented in Section 9.5. Compare these expressions with the expressions for the other sorting algorithms presented in this chapter. Which parallel formulations perform better than bucket sort, and which perform worse?
9.28 Show that the splitter selection scheme described in Section 9.5 guarantees that the number of elements in each of the m buckets is less than 2n/m.
9.29 Derive expressions for the speedup, efficiency, and isoefficiency function of the sample sort parallel formulation presented in Section 9.5. Derive these metrics under each of the following conditions: (1) the p sub-blocks at each process are of equal size, and (2) the size of the p sub-blocks at each process can vary by a factor of log p.
9.30 In the sample sort algorithm presented in Section 9.5, all processes send p - 1 elements to process P0, which sorts the p(p - 1) elements and distributes splitters to all the processes. Modify the algorithm so that the processes sort the p(p - 1) elements in parallel using bitonic sort. How will you choose the splitters? Compute the parallel run time, speedup, and efficiency of your formulation.
9.31 How does the performance of radix sort (Section 9.6.2) depend on the value of r? Compute the value of r that minimizes the run time of the algorithm.
9.32 Extend the radix sort algorithm presented in Section 9.6.2 to the case in which p processes (p < n) are used to sort n elements. Derive expressions for the speedup, efficiency, and isoefficiency function for this parallel formulation. Can you devise a better ranking mechanism?