10.1 In the parallel formulation of Prim's minimum spanning tree algorithm (Section 10.2), the maximum number of processes that can be used efficiently on a hypercube is Q(n/log n). By using Q(n/log n) processes the run time is Q(n log n). What is the run time if you use Q(n) processes? What is the minimum parallel run time that can be obtained on a message-passing parallel computer? How does this time compare with the run time obtained when you use Q(n/log n) processes?
10.2 Show how Dijkstra's single-source algorithm and its parallel formulation (Section 10.3) need to be modified in order to output the shortest paths instead of the cost. Analyze the run time of your sequential and parallel formulations.
10.3 Given a graph G = (V, E), the breadth-first ranking of vertices of G are the values assigned to the vertices of V in a breadth-first traversal of G from a node v. Show how the breadth-first ranking of vertices of G can be performed on a p-process mesh.
10.4 Dijkstra's single-source shortest paths algorithm (Section 10.3) requires non-negative edge weights. Show how Dijkstra's algorithm can be modified to work on graphs with negative weights but no negative cycles in time Q(|E||V|). Analyze the performance of the parallel formulation of the modified algorithm on a p-process message-passing architecture.
10.5 Compute the total amount of memory required by the different parallel formulations of the all-pairs shortest paths problem described in Section 10.4.
10.6 Show that Floyd's algorithm in Section 10.4.2 is correct if we replace line 7 of Algorithm 10.3 by the following line:
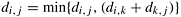
10.7 Compute the parallel run time, speedup, and efficiency of Floyd's all-pairs shortest paths algorithm using 2-D block mapping on a p-process mesh with store-and-forward routing and a p-process hypercube and a p-process mesh with cut-through routing.
10.8 An alternative way of partitioning the matrix D(k) in Floyd's all-pairs shortest paths algorithm is to use the 1-D block mapping (Section 3.4.1). Each of the p processes is assigned n/p consecutive columns of the D(k) matrix.
Compute the parallel run time, speedup, and efficiency of 1-D block mapping on a hypercube-connected parallel computer. What are the advantages and disadvantages of this partitioning over the 2-D block mapping presented in Section 10.4.2?
Compute the parallel run time, speedup, and efficiency of 1-D block mapping on a p-process mesh with store-and-forward routing, a p-process mesh with cut-through routing, and a p-process ring.
10.9 Describe and analyze the performance of a parallel formulation of Floyd's algorithm that uses 1-D block mapping and the pipelining technique described in Section 10.4.2.
10.10 Compute the exact parallel run time, speedup, and efficiency of Floyd's pipelined formulation (Section 10.4.2).
10.11 Compute the parallel run time, the speedup, and the efficiency of the parallel formulation of the connected-component algorithm presented in Section 10.6 for a p-process mesh with store-and-forward routing and with cut-through routing. Comment on the difference in the performance of the two architectures.
10.12 The parallel formulation for the connected-component problem presented in Section 10.6 uses 1-D block mapping to partition the matrix among processes. Consider an alternative parallel formulation in which 2-D block mapping is used instead. Describe this formulation and analyze its performance and scalability on a hypercube, a mesh with SF-routing, and a mesh with CT-routing. How does this scheme compare with 1-D block mapping?
10.13 Consider the problem of parallelizing Johnson's single-source shortest paths algorithm for sparse graphs (Section 10.7.2). One way of parallelizing it is to use p1 processes to maintain the priority queue and p2 processes to perform the computations of the new l values. How many processes can be efficiently used to maintain the priority queue (in other words, what is the maximum value for p1)? How many processes can be used to update the l values? Is the parallel formulation that is obtained by using the p1 + p2 processes cost-optimal? Describe an algorithm that uses p1 processes to maintain the priority queue.
10.14 Consider Dijkstra's single-source shortest paths algorithm for sparse graphs (Section 10.7). We can parallelize this algorithm on a p-process hypercube by splitting the n adjacency lists among the processes horizontally; that is, each process gets n/p lists. What is the parallel run time of this formulation? Alternatively, we can partition the adjacency list vertically among the processes; that is, each process gets a fraction of each adjacency list. If an adjacency list contains m elements, then each process contains a sublist of m/p elements. The last element in each sublist has a pointer to the element in the next process. What is the parallel run time and speedup of this formulation? What is the maximum number of processes that it can use?
10.15 Repeat Problem 10.14 for Floyd's all-pairs shortest paths algorithm.
10.16 Analyze the performance of Luby's shared-address-space algorithm for finding a maximal independent set of vertices on sparse graphs described in Section 10.7.1. What is the parallel run time and speedup of this formulation?
10.17 Compute the parallel run time, speedup, and efficiency of the 2-D cyclic mapping of the sparse graph single-source shortest paths algorithm (Section 10.7.2) for a mesh-connected computer. You may ignore the overhead due to extra work, but you should take into account the overhead due to communication.
10.18 Analyze the performance of the single-source shortest paths algorithm for sparse graphs (Section 10.7.2) when the 2-D block-cyclic mapping is used (Section 3.4.1). Compare it with the performance of the 2-D cyclic mapping computed in Problem 10.17. As in Problem 10.17, ignore extra computation but include communication overhead.
10.19 Consider the 1-D block-cyclic mapping described in Section 3.4.1. Describe how you will apply this mapping to the single-source shortest paths problem for sparse graphs. Compute the parallel run time, speedup, and efficiency of this mapping. In your analysis, include the communication overhead but not the overhead due to extra work.
10.20 Of the mapping schemes presented in Section 10.7.2 and in Problems 10.18 and 10.19, which one has the smallest overhead due to extra computation?
10.21 Sollin's algorithm (Section 10.8) starts with a forest of n isolated vertices. In each iteration, the algorithm simultaneously determines, for each tree in the forest, the smallest edge joining any vertex in that tree to a vertex in another tree. All such edges are added to the forest. Furthermore, two trees are never joined by more than one edge. This process continues until there is only one tree in the forest - the minimum spanning tree. Since the number of trees is reduced by a factor of at least two in each iteration, this algorithm requires at most log n iterations to find the MST. Each iteration requires at most O (n2) comparisons to find the smallest edge incident on each vertex; thus, its sequential complexity is Q(n2 log n). Develop a parallel formulation of Sollin's algorithm on an n-process hypercube-connected parallel computer. What is the run time of your formulation? Is it cost optimal?