8.1 Consider the two algorithms for all-to-all personalized communication in Section 4.5.3. Which method would you use on a 64-node parallel computer with Q(p) bisection width for transposing a 1024 x 1024 matrix with the 1-D partitioning if ts = 100µs and tw = 1µs? Why?
8.2 Describe a parallel formulation of matrix-vector multiplication in which the matrix is 1-D block-partitioned along the columns and the vector is equally partitioned among all the processes. Show that the parallel run time is the same as in case of rowwise 1-D block partitioning.
Hint: The basic communication operation used in the case of columnwise 1-D partitioning is all-to-all reduction, as opposed to all-to-all broadcast in the case of rowwise 1-D partitioning. Problem 4.8 describes all-to-all reduction.
8.3 Section 8.1.2 describes and analyzes matrix-vector multiplication with 2-D partitioning. If 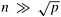 , then suggest ways of improving the parallel run time to
, then suggest ways of improving the parallel run time to 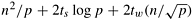 . Is the improved method more scalable than the one used in Section 8.1.2?
. Is the improved method more scalable than the one used in Section 8.1.2?
8.4 The overhead function for multiplying an n x n 2-D partitioned matrix with an n x 1 vector using p processes is 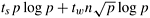 (Equation 8.8). Substituting this expression in Equation 5.14 yields a quadratic equation in n. Using this equation, determine the precise isoefficiency function for the parallel algorithm and compare it with Equations 8.9 and 8.10. Does this comparison alter the conclusion that the term associated with tw is responsible for the overall isoefficiency function of this parallel algorithm?
(Equation 8.8). Substituting this expression in Equation 5.14 yields a quadratic equation in n. Using this equation, determine the precise isoefficiency function for the parallel algorithm and compare it with Equations 8.9 and 8.10. Does this comparison alter the conclusion that the term associated with tw is responsible for the overall isoefficiency function of this parallel algorithm?
8.5 Strassen's method [AHU74, CLR90] for matrix multiplication is an algorithm based on the divide-and-conquer technique. The sequential complexity of multiplying two n x n matrices using Strassen's algorithm is Q(n2.81). Consider the simple matrix multiplication algorithm (Section 8.2.1) for multiplying two n x n matrices using p processes. Assume that the 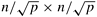 submatrices are multiplied using Strassen's algorithm at each process. Derive an expression for the parallel run time of this algorithm. Is the parallel algorithm cost-optimal?
submatrices are multiplied using Strassen's algorithm at each process. Derive an expression for the parallel run time of this algorithm. Is the parallel algorithm cost-optimal?
8.6 (DNS algorithm with fewer than n3 processes [DNS81]) Section 8.2.3 describes a parallel formulation of the DNS algorithm that uses fewer than n3 processes. Another variation of this algorithm works with p = n2q processes, where 1  q n. Here the process arrangement is regarded as a q x q x q logical three-dimensional array of "superprocesses," in which each superprocess is an (n/q) x (n/q) mesh of processes. This variant can be viewed as identical to the block variant described in Section 8.2.3, except that the role of each process is now assumed by an (n/q) x (n/q) logical mesh of processes. This means that each block multiplication of (n/q) x (n/q) submatrices is performed in parallel by (n/q)2 processes rather than by a single process. Any of the algorithms described in Sections 8.2.1 or 8.2.2 can be used to perform this multiplication.
q n. Here the process arrangement is regarded as a q x q x q logical three-dimensional array of "superprocesses," in which each superprocess is an (n/q) x (n/q) mesh of processes. This variant can be viewed as identical to the block variant described in Section 8.2.3, except that the role of each process is now assumed by an (n/q) x (n/q) logical mesh of processes. This means that each block multiplication of (n/q) x (n/q) submatrices is performed in parallel by (n/q)2 processes rather than by a single process. Any of the algorithms described in Sections 8.2.1 or 8.2.2 can be used to perform this multiplication.
Derive an expression for the parallel run time for this variant of the DNS algorithm in terms of n, p, ts, and tw. Compare the expression with Equation 8.16. Discuss the relative merits and drawbacks of the two variations of the DNS algorithm for fewer than n3 processes.
8.7 Figure 8.7 shows that the pipelined version of Gaussian elimination requires 16 steps for a 5 x 5 matrix partitioned rowwise on five processes. Show that, in general, the algorithm illustrated in this figure completes in 4(n - 1) steps for an n x n matrix partitioned rowwise with one row assigned to each process.
8.8 Describe in detail a parallel implementation of the Gaussian elimination algorithm of Algorithm 8.4 without pivoting if the n x n coefficient matrix is partitioned columnwise among p processes. Consider both pipelined and non-pipelined implementations. Also consider the cases p = n and p < n.
Hint: The parallel implementation of Gaussian elimination described in Section 8.3.1 shows horizontal and vertical communication on a logical two-dimensional mesh of processes (Figure 8.12). A rowwise partitioning requires only the vertical part of this communication. Similarly, columnwise partitioning performs only the horizontal part of this communication.
8.9 Derive expressions for the parallel run times of all the implementations in Problem 8.8. Is the run time of any of these parallel implementations significantly different from the corresponding implementation with rowwise 1-D partitioning?
8.10 Rework Problem 8.9 with partial pivoting. In which implementations are the parallel run times significantly different for rowwise and columnwise partitioning?
8.11 Show that Gaussian elimination on an n x n matrix 2-D partitioned on an n x n logical mesh of processes is not cost-optimal if the 2n one-to-all broadcasts are performed synchronously.
8.12 Show that the cumulative idle time over all the processes in the Gaussian elimination algorithm is Q(n3) for a block mapping, whether the n x n matrix is partitioned along one or both dimensions. Show that this idle time is reduced to Q(n2 p) for cyclic 1-D mapping and Q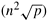 for cyclic 2-D mapping.
for cyclic 2-D mapping.
8.13 Prove that the isoefficiency function of the asynchronous version of the Gaussian elimination with 2-D mapping is Q(p3/2) if pivoting is not performed.
8.14 Derive precise expressions for the parallel run time of Gaussian elimination with and without partial pivoting if the n x n matrix of coefficients is partitioned among p processes of a logical square two-dimensional mesh in the following formats:
Rowwise block 1-D partitioning.
Rowwise cyclic 1-D partitioning.
Columnwise block 1-D partitioning.
Columnwise cyclic 1-D partitioning.
8.15 Rewrite Algorithm 8.4 in terms of block matrix operations as discussed at the beginning of Section 8.2. Consider Gaussian elimination of an n x n matrix partitioned into a q x q array of submatrices, where each submatrix is of size of n/q x n/q. This array of blocks is mapped onto a logical 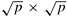 mesh of processes in a cyclic manner, resulting in a 2-D block cyclic mapping of the original matrix onto the mesh. Assume that
mesh of processes in a cyclic manner, resulting in a 2-D block cyclic mapping of the original matrix onto the mesh. Assume that 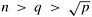 and that n is divisible by q, which in turn is divisible by
and that n is divisible by q, which in turn is divisible by 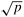 . Derive expressions for the parallel run time for both synchronous and pipelined versions of Gaussian elimination.
. Derive expressions for the parallel run time for both synchronous and pipelined versions of Gaussian elimination.
Hint: The division step A[k, j] := A[k, j]/A[k, k] is replaced by submatrix operation 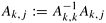 , where Ak,k is the lower triangular part of the kth diagonal submatrix.
, where Ak,k is the lower triangular part of the kth diagonal submatrix.
8.16 (Cholesky factorization) Algorithm 8.6 describes a row-oriented version of the Cholesky factorization algorithm for factorizing a symmetric positive definite matrix into the form A = UTU. Cholesky factorization does not require pivoting. Describe a pipelined parallel formulation of this algorithm that uses 2-D partitioning of the matrix on a square mesh of processes. Draw a picture similar to Figure 8.11.
Algorithm 8.6 A row-oriented Cholesky factorization algorithm.
1. procedure CHOLESKY (A)
2. begin
3. for k := 0 to n - 1 do
4. begin
5. 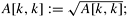 6. for j := k + 1 to n - 1 do
7. A[k, j] := A[k, j]/A[k, k];
8. for i := k + 1 to n - 1 do
9. for j := i to n - 1 do
10. A[i, j] := A[i, j] - A[k, i] x A[k, j];
11. endfor; /*Line3*/
12. end CHOLESKY
6. for j := k + 1 to n - 1 do
7. A[k, j] := A[k, j]/A[k, k];
8. for i := k + 1 to n - 1 do
9. for j := i to n - 1 do
10. A[i, j] := A[i, j] - A[k, i] x A[k, j];
11. endfor; /*Line3*/
12. end CHOLESKY
8.17 (Scaled speedup) Scaled speedup (Section 5.7) is defined as the speedup obtained when the problem size is increased linearly with the number of processes; that is, if W is chosen as a base problem size for a single process, then
Equation 8.19
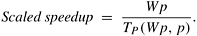
For the simple matrix multiplication algorithm described in Section 8.2.1, plot the standard and scaled speedup curves for the base problem of multiplying 16 x 16 matrices. Use p = 1, 4, 16, 64, and 256. Assume that ts = 10 and tw = 1 in Equation 8.14.
8.18 Plot a third speedup curve for Problem 8.17, in which the problem size is scaled up according to the isoefficiency function, which is Q(p3/2). Use the same values of ts and tw.
Hint: The scaled speedup under this method of scaling is
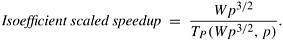
8.19 Plot the efficiency curves for the simple matrix multiplication algorithm corresponding to the standard speedup curve (Problem 8.17), the scaled speedup curve (Problem 8.17), and the speedup curve when the problem size is increased according to the isoefficiency function (Problem 8.18).
8.20 A drawback of increasing the number of processes without increasing the total workload is that the speedup does not increase linearly with the number of processes, and the efficiency drops monotonically. Based on your experience with Problems 8.17 and 8.19, discuss whether using scaled speedup instead of standard speedup solves the problem in general. What can you say about the isoefficiency function of a parallel algorithm whose scaled speedup curve matches the speedup curve determined by increasing the problem size according to the isoefficiency function?
8.21 (Time-constrained scaling) Assume that ts = 10 and tw = 1 in the expression of parallel execution time (Equation 8.14) of the matrix-multiplication algorithm discussed in Section 8.2.1. For p = 1, 4, 16, 64, 256, 1024, and 4096, what is the largest problem that can be solved if the total run time is not to exceed 512 time units? In general, is it possible to solve an arbitrarily large problem in a fixed amount of time, provided that an unlimited number of processes is available? Give a brief explanation.
8.22 Describe a pipelined algorithm for performing back-substitution to solve a triangular system of equations of the form Ux = y, where the n x n unit upper-triangular matrix U is 2-D partitioned onto an n x n mesh of processes. Give an expression for the parallel run time of the algorithm. Modify the algorithm to work on fewer than n2 processes, and derive an expression for the parallel execution time of the modified algorithm.
8.23 Consider the parallel algorithm given in Algorithm 8.7 for multiplying two n x n matrices A and B to obtain the product matrix C. Assume that it takes time tlocal for a memory read or write operation on a matrix element and time tc to add and multiply two numbers. Determine the parallel run time for this algorithm on an n2-processor CREW PRAM. Is this parallel algorithm cost-optimal?
8.24 Assuming that concurrent read accesses to a memory location are serialized on an EREW PRAM, derive the parallel run time of the algorithm given in Algorithm 8.7 on an n2-processor EREW PRAM. Is this algorithm cost-optimal on an EREW PRAM?
Algorithm 8.7 An algorithm for multiplying two n x n matrices A and B on a CREW PRAM, yielding matrix C = A x B.
1. procedure MAT_MULT_CREW_PRAM (A, B, C, n)
2. begin
3. Organize the n2 processes into a logical mesh of n x n;
4. for each process Pi,j do
5. begin
6. C[i, j] := 0;
7. for k := 0 to n - 1 do
8. C[i, j] := C[i, j] + A[i, k] x B[k, j];
9. endfor;
10. end MAT_MULT_CREW_PRAM
8.25 Consider a shared-address-space parallel computer with n2 processors. Assume that each processor has some local memory, and A[i, j] and B [i, j] are stored in the local memory of processor Pi,j. Furthermore, processor Pi,j computes C [i, j] in its local memory. Assume that it takes time tlocal + tw to perform a read or write operation on nonlocal memory and time tlocal on local memory. Derive an expression for the parallel run time of the algorithm in Algorithm 8.7 on this parallel computer.
8.26 Algorithm 8.7 can be modified so that the parallel run time on an EREW PRAM is less than that in Problem 8.24. The modified program is shown in Algorithm 8.8. What is the parallel run time of Algorithm 8.8 on an EREW PRAM and a shared-address-space parallel computer with memory access times as described in Problems 8.24 and 8.25? Is the algorithm cost-optimal on these architectures?
8.27 Consider an implementation of Algorithm 8.8 on a shared-address-space parallel computer with fewer than n2 (say, p) processors and with memory access times as described in Problem 8.25. What is the parallel runtime?
Algorithm 8.8 An algorithm for multiplying two n x n matrices A and B on an EREW PRAM, yielding matrix C = A x B.
1. procedure MAT_MULT_EREW_PRAM (A, B, C, n)
2. begin
3. Organize the n2 processes into a logical mesh of n x n;
4. for each process Pi,j do
5. begin
6. C[i, j] := 0;
7. for k := 0 to n - 1 do
8. C[i, j] := C[i, j] +
A[i, (i + j + k) mod n] x B[(i + j + k) mod n, j];
9. endfor;
10. end MAT_MULT_EREW_PRAM 8.28 Consider the implementation of the parallel matrix multiplication algorithm presented in Section 8.2.1 on a shared-address-space computer with memory access times as given in Problem 8.25. In this algorithm, each processor first receives all the data it needs into its local memory, and then performs the computation. Derive the parallel run time of this algorithm. Compare the performance of this algorithm with that in Problem 8.27.
8.29 Use the results of Problems 8.23-8.28 to comment on the viability of the PRAM model as a platform for parallel algorithm design. Also comment on the relevance of the message-passing model for shared-address-space computers.